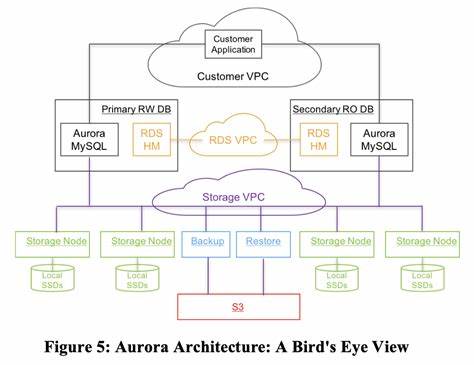
Die Entwicklung von relationalen Datenbanken, die in der Cloud betrieben werden und gleichzeitig extrem hohe Datenmengen verarbeiten können, stellt eine enorme technische Herausforderung dar. Die Anforderungen an Verfügbarkeit, Skalierbarkeit, Fehlertoleranz und Performance steigen exponentiell, wenn Datenbanken über geografisch verteilte Rechenzentren hinweg betrieben werden. In diesem Kontext haben sich neuartige Architekturansätze und Designprinzipien herauskristallisiert, die zeigen, wie verteilte Systeme effizient organisiert und betrieben werden können, um diese Ziele zu erreichen. Ein herausragendes Beispiel für eine solche cloud-native relationale Datenbank ist Amazon Aurora, die auf mehr als einer konventionellen Architektur aufbaut und innovative Lösungen gegen bekannte Flaschenhälse in verteilten Systemen einsetzt. Die Kernherausforderung liegt dabei vor allem in der Handhabung der Netzwerklatenz und der verursachten Leistungseinbußen.
Herkömmliche Datenbanksysteme, die beispielsweise auf MySQL basieren, replizieren Daten und Redo-Logs über das Netzwerk zwischen Knoten, was bei wachsender Anzahl von Replikaten zu einem enormen Netzwerktraffic führt und die Performance stark beeinträchtigt. Amazon Aurora begegnet diesem Problem mit einer radikalen Neuerung: Der ursprüngliche Flaschenhals, das permanente Lesen und Schreiben von Daten über das Netzwerk in Echtzeit, wird durch das Verschieben der Redo-Log-Verarbeitung in die Speicherungslayer entschärft. Statt komplette Datenseiten bei jedem Schreibvorgang zu übertragen, werden lediglich die inkrementellen Redo-Log-Einträge übermittelt und dort verarbeitet. Dieses Konzept ändert grundlegend, wie der Datenbestand kontinuierlich aufgebaut wird – die Verarbeitung und das Replizieren von Daten werden asymmetrisch und asynchron betrieben, wodurch die Server-Seite von der aufwändigen Synchronisation entlastet wird. Diese Architektur führt nicht nur zu niedrigerer Latenz bei Schreiboperationen, sondern auch zu einer schnelleren und kontinuierlichen Wiederherstellung im Fehlerfall.
Komponenten in der Cloud können ausfallen oder aufgrund von Wartungen und Skalierungsvorgängen neu gestartet werden. Aurora adressiert die unweigerlichen Ausfälle mit einem hochgradig resilienten Replikationsmodell, das Daten mehrfach in sogenannten Protection Groups über verschiedene Availability Zones verteilt. Dabei wird eine höhere Replikationsintensität gewährleistet, um nicht nur den Ausfall einzelner Knoten, sondern auch ganzer Availability Zones ohne Performanceverlust abzufangen. Die Verteilung der Daten erfolgt in kleinen Segmenten von etwa 10 Gigabyte, deren mehrfache Replikation sich schnell beheben lässt. Dieses Vorgehen reduziert die mittlere Wiederherstellungszeit von Knoten drastisch, sodass das System grundsätzlich auch bei komplexen Ausfallszenarien weiterlaufen kann.
Die Idee dahinter ist, dass kleine Einheiten schneller neu aufgebaut werden können als komplette Datenbanken, was das Risiko reduziert, dass das System durch zu lang dauernde Fehlerzustände beeinträchtigt wird. Zudem erlaubt diese verbesserte Fehlertoleranz eine durchgehende Wartung und Pflege der zugrunde liegenden Infrastruktur ohne spürbare Ausfallzeiten im Betrieb. Die Architektur von Aurora spiegelt die Notwendigkeit wider, das Netzwerk als limitierenden Faktor einer verteilten relationalen Datenbank zu begreifen und diesen Engpass durch ein neues Speichermodell zu umgehen. Durch das Pushen der logischen Verarbeitungsebene mit den Redo-Logs in die Speicherschicht wird aus dem Netzwerk eine Plattform, die nur die tatsächlich notwendigen inkrementellen Änderungen transportieren muss. Dies führt zu einer starken Reduzierung des Netzwerkdatenvolumens und ermöglicht gleichzeitig, Lese- und Schreiboperationen flexibel und vor allem performant auf unterschiedliche Knoten zu verteilen.
Die Konsistenz und Synchronisation zwischen den Knoten wird dadurch unterstützt, dass jedem Log-Eintrag eine monoton steigende Log Sequence Number (LSN) zugewiesen wird, die der DB-Engine und Speichermodulen hilft, den aktuellen Stand der Daten synchron zu halten. Unterschiedliche LSN-Werte ermöglichen es, den Zustand der Datenbank zwischen verschiedenen Knoten zu vergleichen, so dass fehlende oder veraltete Daten nachträglich aktualisiert werden können. Auf diese Weise kann das System ständig den Fortschritt der Datenverarbeitung messen und anpassen, ohne dass der Client-Wirte pro Transaktion aufwendige Synchronisationsprotokolle durchlaufen muss. Die Trennung von Konsistenzpunkten für die Lesbarkeit und Dauerhaftigkeit der Daten erlaubt es Aurora, Leseoperationen performant zu bedienen, selbst wenn einzelne Speichersegmente noch nicht vollständig aktualisiert sind. Dieses feinkörnige Abstimmungssystem sorgt dafür, dass die Datenbank stets konsistente Sichtbarkeiten der Daten garantiert, ohne die parallele Verarbeitung zu behindern.
Die Skalierbarkeit von solchen Cloud-Datenbanken hängt ferner stark davon ab, wie geschickt sie mit plötzlichen Verkehrsanstiegen und Lastspitzen umgehen. Aurora implementiert Mechanismen, die dynamisch neue Speicher- und Rechenknoten einbinden, um die hohe Anpassungsfähigkeit und Verfügbarkeit des Systems sicherzustellen. Dabei spielt auch die Fähigkeit, Schemaänderungen ohne Ausfälle durchzuführen, eine wichtige Rolle. Statt sofortige, blockierende Änderungen vorzunehmen, kommt ein Modify-on-Write-Ansatz zum Einsatz. Dieser sorgt dafür, dass Änderungen am Schema schrittweise und transparent für den Nutzer durchgeführt werden, ohne die laufenden Abfragen zu unterbrechen.
Ein weiterer essenzieller Aspekt ist das Management von Softwareupdates und Sicherheits-Patches in einem verteilten Cloudumfeld. Aurora verfolgt hier eine Strategie des Zero-Downtime-Patchings, bei der einzelne Knoten nacheinander und ohne Unterbrechung des Gesamtdienstes aktualisiert werden. Dieses Vorgehen vermeidet nicht nur Unterbrechungen, sondern stärkt auch das Vertrauen der Kunden in das System, da Arbeiten im Hintergrund kontinuierlich und sicher durchgeführt werden können. Insgesamt zeigt die Architektur von Amazon Aurora und vergleichbaren cloud-nativen relationalen Datenbanken, wie eine intelligente Verlagerung der logischen Verarbeitungsschwerpunkte und ein robustes Replikationssystem zusammen ein neues Niveau an Performance und Ausfallsicherheit ermöglichen. Die Kombination aus differenzierter Replikation, optimiertem Netzwerkverkehr und asynchroner Verarbeitung macht es möglich, sowohl Speicherung als auch Berechnung effektiv voneinander zu entkoppeln.
Dies resultiert in besseren Skalierungsmöglichkeiten und einer deutlich schnelleren Recovery bei Ausfällen, was im Kontext global verteilter Anwendungen ein erheblicher Wettbewerbsvorteil ist. Für Entwickler und Betreiber von Datenbanksystemen in der Cloud ist es deshalb essenziell, die Prinzipien wie die dezentrale Log-Verarbeitung, granulare Datenpartitionierung und smarte Quorum-Modelle zu verstehen und anzuwenden. Diese ermöglichen nicht nur den Aufbau von Systemen mit hoher Verfügbarkeit, sondern auch den Umgang mit der unvermeidlichen Komplexität verteilter Umgebungen. Die kontinuierliche Optimierung von Netzwerk-I/O, die Minimierung synchroner Prozesse im kritischen Pfad von Schreiboperationen sowie eine feingranulare Segmentierung von Daten und Logs bieten dabei einen wirkungsvollen Hebel für nachhaltige Performanceverbesserungen. Abschließend lässt sich festhalten, dass cloud-native relationale Datenbanken mit Fokus auf Hochdurchsatz nicht einfach nur eine Frage der Ressourcenvermehrung oder Hardwarebeschleunigung sind.
Vielmehr beruht der Erfolg auf klugen Designentscheidungen, die bekannte Limitierungen auf Lösungsebene umgehen und in der Summe innovative Architekturen hervorbringen. Diese erlauben es, die Vorteile der Cloud – wie elastische Skalierbarkeit und Resilienz – in vollem Umfang auszuschöpfen und gleichzeitig die Anforderungen moderner Anwendungen an Verfügbarkeit, Konsistenz und Skalierung zu erfüllen. Die Lehren aus Systemen wie Amazon Aurora setzen Maßstäbe für zukünftige Entwicklungen im Bereich verteilte Datenbanken und zeigen, dass mit einem neuen Denken in Bezug auf Log-Verarbeitung, Netzwerkmanagement und Datenreplikation neue, leistungsfähigere Systeme möglich sind, die den stetig wachsenden Anforderungen der digitalen Welt gerecht werden.