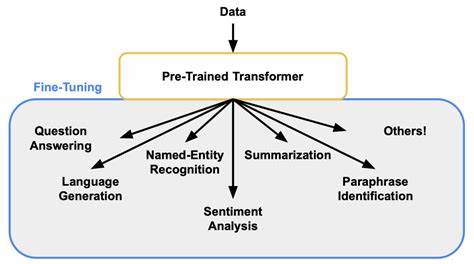
Die rasante Entwicklung großer Sprachmodelle hat das Feld der Künstlichen Intelligenz und insbesondere die Verarbeitung natürlicher Sprache revolutioniert. Transformermodelle, allen voran Modelle wie GPT und BERT, haben durch ihre enorme Kapazität und Flexibilität ein neues Zeitalter der KI eingeläutet. Dennoch bleibt das Feintuning dieser Modelle mit erheblichem Rechenaufwand verbunden, was den praktischen Einsatz einschränkt und die Kosten für Unternehmen und Forschungseinrichtungen in die Höhe treibt. An dieser Stelle kommen inference-time Techniken ins Spiel, die es ermöglichen, feinjustierte Fähigkeiten der Modelle ohne Anpassung der Modellparameter zu erreichen. Die speziell erst kürzlich vorgestellte Forschung von Asankhaya Sharma liefert dafür nicht nur theoretische Belege, sondern auch praktische Herangehensweisen, wie sich diese Konzepte realisieren lassen.
Der Kern der Untersuchung liegt in der Erkenntnis, dass unter idealisierten Bedingungen ein Basistransformer in der Lage ist, durch geschickte Inferenzmethoden die Fähigkeiten, die normalerweise erst durch überwachtes Feintuning (Supervised Fine-Tuning, kurz SFT) gewonnen werden, zu emulieren. Dabei wird keinerlei Veränderung am Modell selbst vorgenommen, sondern durch die geschickte Nutzung des Kontextfensters und Beispielen während der Abfragezeit – also in-context learning (ICL) – das Modell dazu gebracht, erwünschte Verhaltensweisen zu zeigen. Besonders bemerkenswert daran ist, dass diese Methode theoretisch unter unbeschränkten Rechenressourcen und vollständigem Zugang zum Feintuning-Datensatz funktioniert. In der Praxis sind allerdings Ressourcen begrenzt, und auch das Kontextfenster der Modelle ist endlich. Die Forschung hat gezeigt, dass dennoch sehr effiziente Approximationen möglich sind, selbst wenn nur ein Teil der Daten verfügbar ist und das Kontextfenster eine begrenzte Länge hat.
Für Textgenerierungssysteme mit einer festen Ausgabelänge lassen sich die Anforderungen an den Datensatz so präzisieren, dass die Größe beispielsweise in Relation zur Vokabulargröße, der Fehlerquote und der gewünschten Sicherheit (Fehlerwahrscheinlichkeit) skaliert. Ebenso konnten klare Grenzen für Klassifizierungsaufgaben formuliert werden, wobei die Input-Dimensionalität und der erlaubte Fehler hierbei relevante Größen sind. Diese Resultate erweisen sich als direkte Anwendung der bewiesenen Turing-Vollständigkeit von Transformermodellen: theoretisch kann ein Transformer beliebige Berechnungen abbilden, sofern genügend Kontext zur Verfügung steht. Folglich ist es möglich, die Funktionsweise eines feingetunten Modells auch zur Abfragezeit herzustellen, ohne die Parameter explizit durch teures Training zu verändern. Die Bedeutung dieser Erkenntnisse besteht nicht nur in der theoretischen Fundierung des Konzepts, sondern vor allem in den praktischen Implikationen.
Die Ressourceneffizienz wird drastisch verbessert, da kein langwieriger Trainingsprozess notwendig ist, was insbesondere für Anwendungen im industriellen Umfeld oder für Dienstleister mit begrenztem Budget von großem Vorteil ist. Zudem eröffnen diese Verfahren neue Möglichkeiten in der dynamischen Anpassung von Modellen je nach Anwendungsszenario, ohne auf starre Feintuning-Modelle zurückgreifen zu müssen. Ein weiterer wichtiger praktischer Aspekt ist die Verknüpfung mit Retrieval-Augmented Generation (RAG). Hierbei werden externe Wissensquellen bei der Fragebeantwortung oder Textgenerierung herangezogen und in das Kontextfenster eingeschleust. Diese Kombination aus ICL und RAG erlaubt es, Modelle gezielt mit domänenspezifischem Wissen zu versorgen, was ein entscheidender Schritt ist, um die theoretischen Potenziale auch in realen Anwendungen zu erschließen.
Für Unternehmen und Entwickler bedeutet das, dass der Fokus verstärkt auf die intelligente Gestaltung der Kontextinformationen und Datenauswahl gelegt wird, um bestmögliche Ergebnisse zu erzielen. Statt teure Rechenkapazitäten für Feintuning-Prozesse vorzusehen, kann durch geschicktes Prompt-Engineering und selektive Datenbereitstellung ein ähnliches oder sogar besseres Ergebnis erzielt werden, was die Agilität und Individualisierbarkeit von KI-Systemen stark erhöht. Trotz der vielen Vorteile gibt es auch Herausforderungen und Grenzen. Die Effektivität von in-context learning Techniques hängt stark von der Qualität und Repräsentativität der bereitgestellten Kontextbeispiele ab. Zudem steigt mit zunehmender Komplexität der Aufgabe und damit nötiger Kontextgröße auch die Nachfrage nach Rechenressourcen.
Hier sind innovative Kompressions- und Optimierungsmethoden gefragt, um die Balance zwischen Leistung und Effizienz beizubehalten. Es zeigt sich, dass das Prinzip von Feintuning durch Inferenzzeit-Methoden nicht nur eine theoretische Kuriosität ist, sondern das Potenzial hat, die KI-Landschaft nachhaltig zu verändern. Mit dem stetigen Fortschritt größerer und leistungsfähigerer Modelle sowie smarterer Techniken zur Datenorganisation und Kontextgestaltung werden derartige Ansätze im kommenden Jahrzehnt eine zentrale Rolle einnehmen. Zusammenfassend lässt sich sagen, dass die Verlagerung von traditionellen, rechenintensiven Feintuningprozessen hin zu flexiblen, datenbasierten Inferenzmethoden einen Paradigmenwechsel darstellt. Dieser Wandel fördert eine neue Ära der ressourcenschonenden KI-Anwendungen, bei denen Anpassungsfähigkeit und Effizienz im Fokus stehen.
Für Forscher, Entwickler und Unternehmen lohnt sich die Auseinandersetzung mit diesen Verfahren auf mehrfacher Ebene – von theoretischem Verständnis bis hin zu praxisnaher Implementierung. Zukünftige Untersuchungen werden insbesondere darauf abzielen, die Grenzen des kontextbasierten Lernens genauer abzustecken, bessere Auswahlverfahren für Kontextbeispiele zu entwickeln und die Integration externer Wissensquellen weiter zu optimieren. Damit ist ein dynamisches Forschungsfeld gegeben, das die Brücke zwischen theoretischer KI-Forschung und realen Anwendungsszenarien elegant schlägt und die Nutzung großer Transformermodelle für alle zugänglicher macht.