Large Language Models haben in den vergangenen Jahren eine bemerkenswerte Entwicklung durchlaufen und sind aus vielen Bereichen der Künstlichen Intelligenz, insbesondere im Bereich der natürlichen Sprachverarbeitung, nicht mehr wegzudenken. Während die ersten Modelle vor allem darauf fokussiert waren, kurze und mittellange Texte korrekt zu verstehen und zu generieren, verschiebt sich die Forschung zunehmend in Richtung Langzeit-Kontextverarbeitung. Die Fähigkeit, große Mengen an zusammenhängenden Informationen nicht nur zu erfassen, sondern vor allem qualitativ hochwertig und kohärent in die Antwort einzubinden, gilt mittlerweile als das nächste große Innovationsfeld bei LLMs. Dabei ist der Umgang mit längeren Kontexten weit schwieriger, als es auf den ersten Blick scheinen mag, und stellt Forscher und Entwickler vor komplizierte technische Herausforderungen. Die Bedeutung von langem Kontext liegt auf der Hand: In vielen Anwendungsfällen wie etwa dem Verfassen komplexer Codeabschnitte, dem Verstehen umfangreicher Dokumentationen, der Analyse großer Datenmengen im Kontext von Retrieval-Augmented Generation (RAG) und fortgeschrittenen Reasoning-Aufgaben ist die Verarbeitung von tausenden bis Millionen von Token essenziell.
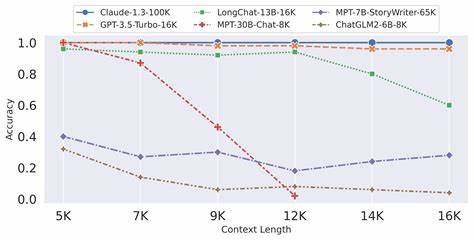
Aktuelle Modelle stoßen hier allerdings schnell an ihre Grenzen. Obwohl sie theoretisch in der Lage sind, mehrere Millionen Token als Kontext aufzunehmen, leidet die Qualität der Ausgabe mit zunehmender Länge stark darunter, was die Effizienz und den wirtschaftlichen Nutzen erheblich einschränkt. Einer der zentralen Gründe für die Schwierigkeiten mit langem Kontext ist die Schwierigkeit, qualitativ hochwertiges Trainingsmaterial bereitzustellen. Es ist eine Herausforderung, zusammenhängende und für Nutzer relevante Datensätze zu generieren, die gleichzeitig lang genug und kohärent sind. Ohne genügend diversifizierte und praxisrelevante Daten verschlechtern sich die Lernkapazitäten der Modelle bei der Langzeitverarbeitung deutlich.
Zusätzlich existieren bislang erst wenige etablierte Benchmarks, die aussagekräftig messen, wie gut ein Modell tatsächlich mit komplexen und langen Kontextinformationen umgehen kann. Ein weiterer technischer Engpass liegt in der Rechenkomplexität von Selbstaufmerksamkeitsmechanismen, die das Herzstück moderner Transformer-Architekturen bilden. Der klassische Ansatz hat eine quadratische Laufzeitkomplexität in Bezug auf die Eingabelänge, was bei längeren Sequenzen massive Hardware-Ressourcen erfordert und somit die Skalierung erschwert. Zwar wurden verschiedene Ansätze wie lineare Aufmerksamkeitsmechanismen entwickelt, welche die Komplexität reduzieren, doch sind diese häufig mit Leistungseinbußen verbunden. Die Balance zwischen Effizienz und Genauigkeit ist in diesem Feld derzeit ein zentrales Forschungsgebiet.
Auch das Problem der Positionscodierung spielt eine wichtige Rolle. Modelle nutzen meist Techniken wie Rotary Positional Encoding (RoPE), um die Reihenfolge von Token zu repräsentieren. Doch das Trainieren auf kürzeren Sequenzen und das anschließende Testen auf deutlich längeren führt zu einer scharfen Verschlechterung der Modellleistung. Neue Mechanismen wie die Positionsinterpolation versuchen, dieses Problem zu mildern, stoßen jedoch bei sehr hohen Kontextlängen an ihre Grenzen. In Bezug auf Hardware und Architektur gibt es vielversprechende Ansätze, die auf Hybridmodelle setzen.
Diese kombinieren verschiedene Arten von Positionscodierungen sowie unterschiedliche Aufmerksamkeitsmechanismen, um die Vorteile beider Welten zu vereinen. Ein Beispiel hierfür ist das sogenannte Scout-Modell, das eine Mischung aus RoPE und NoPE nutzt, sowie Minimax, das reguläre und lineare Aufmerksamkeit verbindet. Solche Hybridansätze könnten den Weg ebnen, um qualitativ hochwertigen, millionenweichen Kontext aufzunehmen und sinnvoll zu verarbeiten. Vor allem im Bereich der Codegenerierung spielt die lange Kontextverarbeitung eine erhebliche Rolle. Entwicklerteams, die auf KI-unterstützte Werkzeuge setzen, benötigen Modelle, die große Codebasen verstehen und erweitern können, ohne an Präzision und Verständlichkeit zu verlieren.
Der Wert, den die LLM-Technologie auf diesem Gebiet schöpft, nimmt stetig zu und wird mittelfristig einen festen Platz im Softwareentwicklungsprozess einnehmen. Ein großer Technologiekonzern wie Google investiert intensiv in die Erforschung und Entwicklung von LLMs mit lange Kontextlänge, was Standardisierung sowie neue Leistungshorizonte verspricht. Die Einführung von Modellen, die bis zu 10 Millionen Tokens als Kontext nutzen können, signalisiert einen bedeutenden Fortschritt, auch wenn die Qualitätsbeurteilung derzeit noch kritisch ist. Es ist zu erwarten, dass in den kommenden Jahren die Forschung entscheidende Durchbrüche erzielt, die diese Kapazitäten zuverlässig und stabil machen. Die Entwicklung von LLMs mit langfristigem Kontext wird nicht nur die Leistungsfähigkeit einzelner Anwendungen verbessern, sondern auch neue Anwendungsfelder erschließen.
In RAG-Systemen wird die Fähigkeit, eine große Menge an Kontextmaterial ohne Informationsverlust zu integrieren, die Genauigkeit bei der Generierung von Antworten stark erhöhen. In intelligenten Assistenzsystemen wird ein besseres Verständnis großer Dokumentstrukturen möglich, was komplexes Textverständnis und tiefgehendes Reasoning erleichtert. Sie werden auch die nächste Generation von KI-gestützten Codieragenten hervorbringen, die als hochqualifizierte Partner in der Softwareentwicklung agieren. Es ist jedoch unzweifelhaft, dass die Erhöhung des Kontextumfangs keine triviale Aufgabe ist. Neben den rein technischen Herausforderungen erfordert die Optimierung der Modelle auch neue Algorithmen, innovative Trainingsparadigmen und eventuell auch eine neue Denkweise bei der Architektur von Transformer-Modellen.
Die Kombination aus intelligentem Layer-Hybrid-Design, optimierten Positionscodierungen und effizienteren Aufmerksamkeitsmechanismen bildet wahrscheinlich die Basis für die nächsten Durchbrüche. Zusammenfassend lässt sich sagen, dass die Fähigkeit von Large Language Models, qualitativ hochwertige Langzeitkontexte zuverlässig zu verarbeiten, aktuell wohl die spannendste Herausforderung im Bereich der Künstlichen Intelligenz ist. Dieses Gebiet wird den Fortschritt und die Leistungsfähigkeit von LLM-Anwendungen maßgeblich bestimmen und das Technologieprofil ganzer Unternehmen verändern. Die kommenden Jahre werden daher entscheidend sein, um das volle Potenzial dieser Technologie zu entfalten und die nächste Stufe der KI-Entwicklung einzuläuten.