Die Welt des maschinellen Lernens entwickelt sich mit rasanter Geschwindigkeit weiter und stellt Forscher vor stetige neue Herausforderungen. Ein zentraler Aspekt ist dabei das Lernen mit begrenzten oder gar nicht vorhandenen gelabelten Daten. In diesem Zusammenhang hat sich das sogenannte selbstüberwachte kontrastive Lernen (Self-Supervised Contrastive Learning, kurz CL) als eine der vielversprechendsten Methoden herausgestellt. Bislang wurde vor allem seine empirische Effektivität hervorgehoben, doch die theoretischen Grundlagen blieben lange Zeit unklar. Aktuelle Forschungsarbeiten zeigen jedoch, dass selbstüberwachtes kontrastives Lernen in seiner Wirkungsweise überraschend nah an den klassischen, überwachten kontrastiven Lernverfahren liegt.
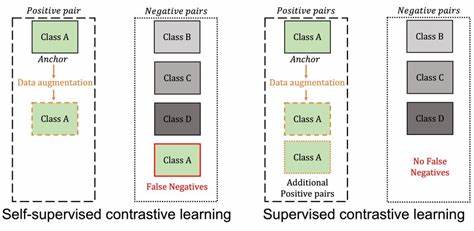
Diese Erkenntnis könnte maßgeblich das Verständnis und den Einsatz dieser Methoden in der Praxis prägen. Kontrastives Lernen fußt auf der Idee, durch den Vergleich von Datenpaaren die Ähnlichkeiten und Unterschiede in den zugrunde liegenden Strukturen zu erfassen. Im überwachten Umfeld bedeutet dies, dass Labels genutzt werden, um explizit ähnliche und unähnliche Paare zu definieren und die Modelle entsprechend zu trainieren. Selbstüberwachtes Lernen hingegen kommt ohne externe Labels aus und erstellt seine Lernaufgaben durch technische Tricks wie Datenaugmentation. Trotz dieses Unterschieds zeigt sich, dass die Verluste, die bei beiden Methoden optimiert werden, sich in mehreren Aspekten sehr ähneln und sich im Grenzfall der steigenden Anzahl von Klassen sogar nahezu angleichend verhalten.
Eine Kernneuheit der aktuellen Forschung ist die Definition des sogenannten "negatives-only supervised contrastive loss" (NSCL). Dieses Konzept beschreibt eine Variante des überwachten kontrastiven Lernens, bei der ausschließlich Unterschiede zwischen verschiedenen Klassen berücksichtigt werden und gleichklassige Vergleiche ausgeschlossen bleiben. Das Ergebnis dieser Betrachtung ist verblüffend: Das klassische selbstüberwachte Kontrastive Lernen approximiert diesen NSCL-Loss immer genauer, je mehr semantische Klassen in den Daten vorhanden sind. Dabei spielt es keine Rolle, welche Architektur für das Modell verwendet wird oder ob Labels tatsächlich vorhanden sind – die Analyse ist label-agnostisch und architekturunabhängig. Dies stärkt die allgemeine Aussagekraft und Validität der Ergebnisse.
Neben dem theoretischen Nachweis wurden auch wichtige Eigenschaften der optimalen Repräsentationen, die durch den NSCL-Loss gelernt werden, untersucht. Charakteristisch ist dabei das Phänomen der sogenannt en Augmentationskollaps, bei dem unterschiedliche Varianten derselben Datenprobe sehr ähnliche Repräsentationen erhalten. Außerdem treten ein starker innerklasslicher Kollaps sowie die Bildung von Klassenmitten auf, die die geometrische Struktur eines sogenannten simplex equiangular tight frame aufweisen. Diese Strukturen sorgen für eine besonders günstige Verteilung der Repräsentationen im Merkmalsraum, die sowohl die Trennung der Klassen als auch die Robustheit gegenüber Variationen fördert. Ein weiterer wichtiger Beitrag ist die neue theoretische Bindung, die den Fehler beim Few-Shot-Lernen mittels linearer Proben beschreibt.
Few-Shot-Lernen zielt darauf ab, mit sehr wenigen gelabelten Beispielen neue Klassen oder Aufgaben zu bearbeiten. Die vorgestellte Fehlerabschätzung hängt von zwei Hauptfaktoren ab: Zum einen der Streuung der Merkmale innerhalb einer Klasse und zum anderen der Variation entlang der Richtungen zwischen den Klassenmitten. Hervorzuheben ist, dass vor allem die Variation entlang dieser Richtungen eine dominierende Wirkung hat, während die innerklassliche Streuung mit einer steigenden Anzahl gelabelter Beispiele an Bedeutung verliert. Diese Erkenntnis unterstützt die Praxis, dass kontrastives Lernen selbst in Szenarien mit spärlichen Labels äußerst effektiv ist und die so gewonnenen Repräsentationen eine gute Grundlage für spätere Klassifikationen mit einfachen linearen Modellen bilden. Die theoretischen Einsichten wurden auch durch umfangreiche empirische Studien bestätigt.
Es zeigte sich, dass die Differenz zwischen dem klassischen selbstüberwachten kontrastiven Verlust und dem NSCL-Verlust in der Praxis tatsächlich mit der Anzahl der Klassen abnimmt. Die beiden Verluste korrelieren stark, und die Minimierung des CL-Verlustes führt indirekt zur Annäherung an Werte, die durch eine direkte Minimierung des NSCL-Verlustes erreicht werden können. Darüber hinaus liefert die neue Fehlerabschätzung eine verlässliche Prognose für die tatsächliche Performance bei Few-Shot-Tests mit linearen Probes. Diese Validierung stärkt das Vertrauen in die theoretischen Modelle und eröffnet neue Möglichkeiten für die Entwicklung verbesserter Lernverfahren. Die Bedeutung dieser Erkenntnisse reicht weit über die bloße akademische Neugier hinaus.
Selbstüberwachtes kontrastives Lernen bietet einen nachhaltigen Ansatz, um die Abhängigkeit von teuren und zeitaufwändigen Labeling-Prozessen zu reduzieren. Indem der zugrunde liegende Mechanismus besser verstanden wird, lassen sich gezielter Verbesserungen in der Modellarchitektur und Trainingsstrategie vornehmen. Beispielsweise können modulare Trainingspipelines entwickelt werden, die zunächst robuste Basisrepräsentationen mit selbstüberwachten Methoden lernen und diese anschließend gezielt durch wenige gelabelte Daten für spezifische Aufgaben verfeinern. Darüber hinaus eröffnen die geometrischen Erkenntnisse über die Struktur der Repräsentationen spannende Perspektiven für neuartige Regularisierungs- und Optimierungsverfahren. Die Tatsache, dass sich Klassenmittelpunkte in einem simplex equiangular tight frame anordnen, deutet darauf hin, dass eine bewusste Steuerung dieser Struktur im Training zu noch robusteren und interpretierbareren Modellen führen könnte.
Solche Modelle sind nicht nur im Bereich der Computer Vision relevant, sondern finden auch Einsatz in der Verarbeitung natürlicher Sprache, Bioinformatik und weiteren Domänen, in denen datenintensive Anwendungen vorherrschend sind. Die Nachhaltigkeit des Ansatzes zeigt sich auch im Bereich des Few-Shot-Lernens, das für Anwendungen mit limitierten Ressourcen und hohen Anforderungen an Generalisierbarkeit entscheidend ist. Die Tatsache, dass einfache lineare Modelle auf den durch selbstüberwachtes kontrastives Lernen gewonnenen Repräsentationen bereits sehr gute Leistungen erzielen, reduziert die Komplexität nachgelagerter Systeme. Dies spart Rechenressourcen und vereinfacht die Implementierung in produktiven Umgebungen. Zukünftig ist zu erwarten, dass diese neue theoretische Grundlage den Weg für weitere Innovationen im Bereich selbstüberwachten Lernens ebnet.
Die Kombination mit Techniken wie Meta-Learning, Transfer-Learning und multimodalen Ansätzen könnte noch vielseitigere und effizientere Lernalgorithmen hervorbringen. Insbesondere die Integration von Domänenwissen und strukturierter Wissensrepräsentation in selbstüberwachte Frameworks ist ein vielversprechendes Forschungsfeld mit großem Anwendungspotenzial. Zusammenfassend lässt sich festhalten, dass das selbstüberwachte kontrastive Lernen nicht nur experimentell überzeugt, sondern mittlerweile auch theoretisch fundiert wird. Die enge Verwandtschaft zum überwachten kontrastiven Lernen wird durch das NSCL-Konzept greifbar gemacht und liefert eine klare Erklärung für den Erfolg dieser Methoden. Die geometrischen und statistischen Eigenschaften der gelernten Repräsentationen bilden zudem die Grundlage für effiziente und robuste Anwendungen im Bereich der künstlichen Intelligenz.
Die Erkenntnisse aus der aktuellen Forschung bieten damit wertvolle Impulse für zukünftige Entwicklungen und eröffnen neue Wege im Umgang mit immer komplexeren und umfangreicheren Datenwelten.




![Cock[.]li взломали. Похищены данные миллиона пользователей](/images/6198418F-FB03-4C97-ABE0-F29085B943A2)