Im Zuge des rasanten Wachstums von Cloud Computing seit etwa 2010 haben sich AMDs Opteron- und Intels Xeon-Prozessoren als führende Technologien etabliert. Doch die wachsende Bedeutung dieses Marktes hat zunehmend auch andere Prozessorhersteller angezogen – allen voran Qualcomm. Das Unternehmen, bekannt für seine starke Position im mobilen SoC-Segment, entschied sich Mitte der 2010er Jahre, auf den Servermarkt vorzudringen. Qualcomm baute auf seiner Expertise in energieeffizientem CPU-Design auf und setzte mit dem Centriq 2400 und der eigens entwickelten Falkor-Architektur eine eigene ARM-basierte Serverlösung um. Insbesondere das Zusammenspiel von hoher Kernanzahl, Leistung pro Watt und moderner Fertigungstechnologie macht das Konzept bemerkenswert und unterscheidet den Centriq 2400 klar von anderen ARM-Serverchips jener Zeit.
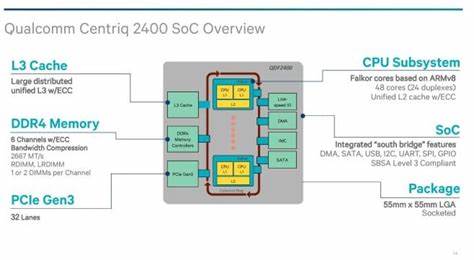
Qualcomm konnte aus seiner langen Erfahrung in der Mobilprozessorentwicklung schöpfen, insbesondere bei der Optimierung der Power Efficiency. Zugleich sicherte sich das Unternehmen den Zugang zu Samsungs 10-nm-FinFET-Fertigung, die eine technologisch moderne und energiearme Produktion des Centriq 2400 ermöglichte. Mit bis zu 48 Falkor-Kernen auf einem Die von 398 mm² Größe und einem Thermischen Design Power (TDP) von 120 Watt bietet der Chip eine dichte und effiziente Lösung, die gegenüber Intel- und AMD-Prozessoren mit ihren größeren Kernen und höherem Stromverbrauch punkten kann. Die Falkor-Architektur ist vollständig auf die Anforderungen von Cloud-Computing-Workloads ausgelegt. Statt wie viele ARM-basierte oder mobile CPUs eine breite Ausrichtung zu haben, geht Qualcomm mit Falkor den Weg, eine hohe Kernanzahl mit solider Einzelkernleistung zu kombinieren.
Der Fokus liegt eindeutig auf einer Balance zwischen hoher Multithread-Performance und niedrigem Stromverbrauch pro Kern. Qualcomm positioniert Falkor damit als wettbewerbsfähige Lösung für moderne Rechenzentren, in denen Skalierbarkeit und Effizienz entscheidend sind. Der Kern selbst ist ein 4-Wege aarch64-Design, das die 64-Bit-Arm-Instruktionssatzarchitektur mit Erweiterungen aus Armv8.1 nutzt. Dabei hat Qualcomm bewusst auf die Unterstützung von 32-Bit-Programmen verzichtet, da es im Serverumfeld nur eine geringe Nachfrage gibt.
Falkor ist zudem Qualcomms fünfte eigene CPU-Designentwicklung und stellt zugleich den ersten Kern dar, der gezielt für Cloud-Anwendungen entworfen wurde. Im Vergleich zu früheren mobilen Designs wurde der Core hinsichtlich seiner Speicherhierarchie und des Speichersubsystems deutlich aufgewertet. Ein bemerkenswertes Detail der Falkor-Architektur ist ihr aufwändiges Instruktionscache-Design. Mit einem zweistufigen L0- und L1-Instruktionscache kombiniert Falkor eine niedrige Latenz mit hoher Kapazität und großem Durchsatz. Der L0-Cache ist mit 24 KB klein, aber dreifach assoziativ und kann Instruktionen besonders schnell bereitstellen.
Der größere 64 KB große L1-Cache ergänzt das frontal mit einer achtfach assoziativen Struktur. Auffällig ist die exklusive Beziehung zwischen L0 und L1, wodurch insgesamt rund 88 KB Instruktionscache-Kapazität zur Verfügung stehen – eine Größe, die erst mit Apples späterem M1-Prozessor wieder erreicht wurde. Diese umfassende Cache-Kapazität verbessert das Handling von Programmcode besonders bei kleineren und mittleren Arbeitslasten erheblich. Ein weiterer Vorteil der Falkor-Architektur ist die Integration der Branch Target Bufferfunktion direkt in die Instruktionscaches. So kann der Prozessor die Sprungziele und Instruktionsbytes in einem einzigen Zugriff laden und dadurch vorausschauende Sprungvorhersagen effizienzsteigernd vornehmen.
Qualcomms Ansatz mit einem branch target instruction cache (BTIC) für kleinere Sprunganwendungen ermöglicht sogar sprungverzögerungsfreie Prozessorpfeifen (zero-bubble taken branches). Ergänzt wird dies durch einen hochentwickelten Branch Predictor, der verschiedene Verlaufslängen parallel auswertet, was dem Konzept eines TAGE-Prädiktors ähnelt. Dadurch bleibt die Sprunggenauigkeit auch bei komplexen oder umfangreichen Verzweigungen hoch und trägt zur Steigerung der Gesamtausführungseffizienz bei. Im Backend bietet Falkor eine breite Ausstattung an Ausführungseinheiten, vor allem differenziert für unterschiedliche Arten von Integer-Operationen und Verzweigungen. Während drei ALUs allgemeine Integer-Arithmetik übernehmen, ist ein eigener Pfad für direkte Sprünge reserviert.
Multiplikationsoperationen können über eine Spezialeinheit im ALU-Pfad mit einer 5-Zyklus-Latenz abgearbeitet werden. Auch bei der Fließkommaverarbeitung zeigt Falkor Fortschritte, mit zwei symmetrischen Pipelines, die grundlegende Floating-Point- und Vektoroperationen unterstützen. Allerdings ist die Umsetzung der 128-Bit-Vektoroperationen suboptimal, da diese intern in zwei Mikrooperationen zerlegt werden, was die verfügbare Durchsatzrate limitiert – ein Kritikpunkt im Vergleich zu Konkurrenzarchitekturen, die auf Vektorperformance setzen. Das Speicher-Subsystem ist eine der wichtigsten Komponenten, die Falkor von Vorgängern sowie von vielen Mobilprozessoren unterscheidet. Der L1-Datencache ist mit 32 KB etwas kleiner dimensioniert, aber innovativ mit sowohl virtueller als auch physischer Tagging-Methode ausgestattet, was eine schnellere Datenbereitstellung ermöglicht, da Adressübersetzung (TLB) teilweise umgangen werden kann.
Diese Maßnahme reduziert die Zugriffszeit entscheidend, da die physikalische Speicheradresse nicht immer erst ermittelt werden muss. Ergänzt wird der L1-Datencache von einem 512 KB großen, L1-inklusiven L2-Cache je Kernpaar (Duplex), was für eine gute cachebasierte Datenversorgung sorgt. Eine weitere Besonderheit ist die Verwendung eines write-through L1-Datencaches kombiniert mit einer sogenannten Write Coalescing Cache (WCC) Struktur am Rand des Caches. Diese Struktur fungiert als gepufferte Speichereinheit, die mehrere Schreibzugriffe an dieselbe Cachelinie zusammenfasst und so unnötige Zugriffe in den L2-Cache und weiter in den Speicher vermeidet. Diese Lösung ist eine elegante Mischung aus den Vorteilen eines write-back Caches mit dem offensichtlichen Designvorteil eines write-through Caches hinsichtlich Fehlerkorrektur und Leistungsfähigkeit.
Qualcomm setzt außerdem auf zwei Ebenen von Translation Lookaside Buffers (TLB) mit direktem Support für Virtualisierung und Stage-2-Adressübersetzungen, was im Serverkontext eine hohe Relevanz besitzt. Neben einem 64-Einträge L1 DTLB gibt es einen 512-Einträge L2 TLB und sogar spezielle nicht finale und virtuelle TLBs. So kann der Centriq 2400 effizienten Betrieb in virtualisierten Umgebungen gewährleisten und vermeidet performancekritische Seitenübersetzungen. Das Systemdesign hebt den Fokus auf Skalierbarkeit und hohe I/O-Bandbreite hervor. Falkor-Kerne gruppieren sich in Dual-Core-Duplex-Komplexen mit gemeinsamer L2-Ebene, die über Qualcomm-eigene Systembusprotokolle (QSB) miteinander kommunizieren.
Diese Architektur ermöglicht eine dichte Integration von bis zu 24 Duplex-Clustern, also 48 Kernen, gleichzeitig ist der Chip klar für den Single-Socket-Einsatz konzipiert. Während AMD und Intel Multi-Socket-Systeme bedienen, setzt Qualcomm hier gezielt auf eine kosteneffiziente Lösung für gängige Cloud-Anwendungen ohne komplexe Mehrfach-Socket-Topologien. Die On-Chip-Kommunikation setzt auf ein bidirektionales, segmentiertes Ringnetzwerk. Vier Ringbusse verbinden Kerngruppen, L3-Cachebanken und Peripherie-Controller und sorgen für eine Bandbreite, die durchaus mit Intel Core i5 Skylake-Kernen vergleichbar ist. Die L3-Cache-Ebene bietet mit insgesamt 60 MB (12 Slices à 5 MB, teils deaktiviert) enorm viel Kapazität, die auch Quality-of-Service-Maßnahmen bei parallelen Anwendungen ermöglicht.
Im realen Betrieb zeigt der Qualcomm Centriq 2400 überzeugende Performancewerte. Im SPEC CPU2017-Benchmark übertrifft ein einzelner Falkor-Kern den ARM Cortex A72 deutlich, sowohl im Integer- als auch im Floating-Point-Bereich, mit besonders großen Vorsprüngen bei floating-point-lastigen Workloads. Aufgrund der stark verbesserten Speicherhierarchie und Cachegrößen meistert der Centriq insbesondere speicherintensive Szenarien deutlich stärker als viele frühere ARM-basierte Serverprozessoren. Beim Vergleich zu klassischen x86-Prozessoren der Skylake-Generation fällt die rohe Single-Core-IPC (Instructions per Cycle) zwar niedriger aus, doch die integrierten Scores pro Watt und Kern machen Centriq zu einer effizienten Alternative für viele Cloud-Anwendungen. Der Fokus auf Cloud-Workloads zeigt sich auch im begrenzten PCIe-Lanes-Angebot (32 PCIe 3.
0-Lanes), was in besonders beschleunigten Server-Szenarien mit vielen GPUs oder anderen Schnittstellen an Grenzen stößt. Gleichzeitig beschränkt die fehlende Multi-Socket-Fähigkeit die Skalierbarkeit für extrem große Server-Cluster. Qualcomm richtet sich somit klar an einen Mainstream-Markt, in dem Kosten, Energieeffizienz und Paketdichte wichtiger sind als maximale Spitzenleistung. Trotz aller technischen Stärken konnte Qualcomm sich im Markt nur bedingt durchsetzen. Dies lag unter anderem an einer noch nicht optimal ausgereiften ARM-Software- und Open-Source-Unterstützung, was gerade im Linux-dominierten Serverbereich eine große Herausforderung darstellte.
Im Vergleich zu Amazons Graviton-1 oder späteren Ampere-Altra-Lösungen ist Falkor heute nicht mehr ganz auf der Höhe der Zeit, insbesondere da Qualcomm nicht mit neuesten Fertigungstechnologien wie 7-nm-Prozessen vertiefend konkurrenzfähig war. Dennoch war der Centriq 2400 ein Meilenstein in der ARM-Serverwelt und zeigte den Weg zu hochkernigen, energieeffizienten Server-CPUs aus ARM-Designs. Blickt man in die Zukunft, plant Qualcomm eine Rückkehr in den Serverbereich, unter anderem durch Kooperationen mit AI-Firmen und Integration mit NVIDIA GPUs via NVLink. Ob aufbauend auf den Lehren aus Falkor und Centriq eine neue Generation entsteht, bleibt spannend zu beobachten. Zusammenfassend lässt sich sagen, dass Qualcomm mit dem Centriq 2400 und der Falkor-Architektur ein mutiges und technisch anspruchsvolles Projekt umgesetzt hat.
Die Kombination aus moderner Fertigung, hoher Kernanzahl, durchdachter Speicherarchitektur und Cloud-fokussierter Performance stellt auch im Rückblick einen wichtigen Beitrag zur Diversifikation des Serverprozessorenmarktes dar. Qualcomms Weg zeigt exemplarisch, wie mobile Prozessorentwicklung und Serverprozessorinnovation in einem wettbewerbsintensiven Umfeld miteinander verschmelzen können, um neuartige Lösungen für hochskalierbare Rechenzentren zu schaffen.