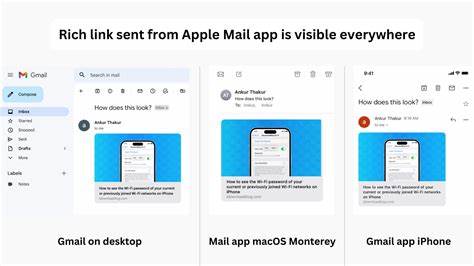
Im digitalen Zeitalter, in dem schnelle und präzise Informationsbereitstellung eine unverzichtbare Rolle spielt, gewinnen Linkvorschauen und Publisher-Informationen zunehmend an Bedeutung. Diese Elemente sind essenziell für eine verbesserte Nutzererfahrung, insbesondere bei der Darstellung geteilter Inhalte in sozialen Netzwerken, Messaging-Apps oder Suchmaschinen. Traditionell wurde das Sammeln von Meta-Daten durch das Scrapen der jeweiligen Webseite realisiert, was jedoch mehrere technische und rechtliche Herausforderungen mit sich bringt. Die Entwicklung innovativer Lösungen, die ohne direktes Scrapen auskommen, verspricht große Vorteile sowohl für Entwickler als auch für Unternehmen unterschiedlicher Branchen. Die klassische Herangehensweise, um Linkvorschauen und Publisher-Informationen zu generieren, basiert meist auf dem Herunterladen und Analysieren des HTML-Inhalts der Zielseite.
Dabei werden Meta-Tags wie Open Graph, Twitter Cards oder reguläre HTML-Meta-Elemente ausgelesen, um Titel, Beschreibungen, Bilder und weitere relevante Daten zu extrahieren. Obwohl diese Methode weit verbreitet ist, bringt sie einige gravierende Nachteile mit sich. Zum einen ist das Scraping oftmals ressourcenintensiv, da jede Anfrage an den Zielserver Kosten für Bandbreite und Rechenleistung verursacht. Zum anderen können Scraping-Mechanismen durch verschiedene Barrieren wie Captchas, IP-Blockaden oder dynamische Webseitenstrukturen erschwert oder sogar verhindert werden. Zudem bestehen juristische Grauzonen bezüglich der Datenverwendung und Urheberrechte, die bei reinem Scraping berücksichtigt werden müssen.
Um diese Herausforderungen zu umgehen, setzt die moderne Technologie zunehmend auf Lösungen, die Meta-Daten extrahieren, ohne die Zielseite direkt zu scrapen. Eine der elegantesten Methoden ist die Nutzung von offiziellen APIs oder speziellen Meta-Informationen, die von vielen Webseiten standardisiert und maschinenlesbar bereitgestellt werden. Einige Webseiten unterstützen sogenannte Link-Previews per spezieller Schnittstellen, die schnelle und zuverlässige Metadaten-Lieferungen ermöglichen. Entwickler können somit direkt auf strukturierte Daten zugreifen, ohne den Seiteninhalt komplett laden oder parsen zu müssen. Ein weiterer Trend ist der Einsatz intelligenter Metadaten-Caches und Indexsysteme, die von spezialisierten Anbietern angeboten werden.
Diese Dienste sammeln, verarbeiten und speichern die relevanten Informationen kontinuierlich und stellen sie via API für verschiedene Anwendungen bereit. Dadurch werden große Verkehrsaufkommen auf den Originalseiten vermieden und gleichzeitig eine schnelle und konsistente Auslieferung der Meta-Daten sichergestellt. Im Kontext von Suchmaschinen oder Social-Media-Plattformen führt dies zu verbesserter Performance und höherer Verfügbarkeit der Linkvorschauen. Die Verwendung von modernen Webstandards wie schema.org erweiterten Microdata oder JSON-LD spielt ebenfalls eine zentrale Rolle in diesem Zusammenhang.
Webseiten, die strukturierte Daten gemäß diesen Standards einbinden, ermöglichen Maschinen eine einfache Interpretation und Zuordnung der Inhalte. APIs und Systeme, die diese Informationen gezielt auslesen, können Linkvorschauen und Publisher-Daten dann bedarfsgerecht zusammenstellen, ohne externe Scraping-Verfahren nötig zu machen. Neben technischen Vorteilen profitieren Unternehmen durch diese Methoden auch von einer erhöhten Rechtssicherheit. Das Umgehen von Scraping verringert mögliche Konflikte mit Datenschutzbestimmungen und Urheberrechtsfragen, da ausschließlich autorisierte oder öffentlich zugängliche Datenquellen genutzt werden. Dies ist insbesondere wichtig vor dem Hintergrund sich ständig ändernder gesetzlicher Rahmenbedingungen im Internet.
Auf Entwicklerseite eröffnen sich durch diese Technologien zahlreiche Möglichkeiten. Sie können Anwendungen gestalten, die nicht nur effizienter und skalierbarer sind, sondern auch langfristig stabil bleiben. Die Integration in Services wie URL-Meta-Informationen, Web-Suche oder die Analyse von Google-Scores als Maß für die Popularität einer Seite erlauben vielfältige Nutzungsszenarien – von der automatischen Kategorisierung über Inhaltsvorschläge bis hin zur Bewertung von Quellenqualität. Das Unternehmen Laterical Labs beispielsweise bietet eine Plattform mit API-Schnittstellen, die genau diese Ansätze verfolgt. Mit Angeboten wie dem API Playground, URL Meta oder Web Search stellt Laterical Entwicklern Werkzeuge bereit, die Link-Previews und Publisher-Informationen effizient und ohne direktes Scraping liefern.
Dies unterstützt Unternehmen dabei, ihre Web- und API-Lösungen optimal zu gestalten und ihren Nutzern eine hochwertige, schnelle Informationsvermittlung zu bieten. Darüber hinaus wird die Kombination von traditionellen und innovativen Technologien zunehmend relevanter. So kann die intelligente Verzahnung von Suchalgorithmen, maschinellem Lernen und strukturierten Metadaten die Qualität der ausgelieferten Linkvorschauen weiter steigern. Die Identifikation von relevanten Inhalten und deren semantische Aufbereitung erlauben ein besseres Verständnis und damit eine bessere Nutzung der bereitgestellten Daten in Echtzeit. Die Zukunft der Linkvorschau- und Publisher-Informationserfassung ohne direktes Scraping ist somit geprägt von mehr Effizienz, legaler Sicherheit und technischer Innovation.
Unternehmen, die sich frühzeitig mit diesen Lösungen auseinandersetzen, profitieren von Wettbewerbsvorteilen, skalierbaren Lösungen und einer verbesserten Nutzerbindung. Für Entwickler bedeutet es eine Vereinfachung der Implementierung und stabile, langfristige Funktionalität. Abschließend lässt sich festhalten, dass die Verzicht auf traditionelles Scraping zugunsten moderner, API-basierter und strukturierter Datenquellen der Schlüssel ist, um im Web von morgen erfolgreich zu agieren. Die zunehmende Verfügbarkeit von standardisierten Metadaten, die Zusammenarbeit mit Plattformen wie Laterical Labs und die Nutzung intelligenter Technologien bilden dabei das Fundament. Durch diese Entwicklung werden nicht nur technische Hürden überwunden, sondern auch die Qualität und Zuverlässigkeit von Linkvorschauen und Publisher-Informationen nachhaltig verbessert.
Damit wird der Grundstein gelegt für ein Web, das sowohl für Anbieter als auch für Nutzer effektiver, sicherer und komfortabler wird.








