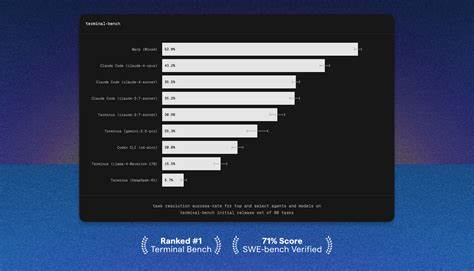
In der dynamischen Welt der künstlichen Intelligenz gewinnt die Fähigkeit von Agenten, sich in komplexen Terminalumgebungen zu behaupten, zunehmend an Bedeutung. Terminalumgebungen, die traditionell als textbasierte Schnittstellen zur Steuerung von Betriebssystemen und Anwendungen dienen, stellen für KI-Agenten besondere Herausforderungen dar. Hier benötigt man nicht nur sprachliche Kompetenz, sondern auch technisches Verständnis sowie präzise Ausführung von Befehlen. Vor diesem Hintergrund ist Terminal-Bench entstanden – eine Benchmark-Plattform, die darauf abzielt, die Effizienz und Zuverlässigkeit von KI-Agenten speziell in Kommandozeilenumgebungen zu bewerten und standardisiert zu vergleichen. Terminal-Bench bietet eine Sammlung von Aufgaben und eine umfassende Evaluierungsumgebung, mit der Entwickler ihre KI-Agenten auf den Prüfstand stellen können.
Die Plattform umfasst aktuell eine Vielzahl von Aufgaben, die unterschiedlichste technische Fähigkeiten abdecken – von der Erstellung selbstsignierter TLS-Zertifikate bis hin zur Verwaltung von Verzeichnissen und der Automatisierung von Sicherheitsprüfungen. Durch die Bewertung zahlreicher Agenten an denselben Aufgaben lassen sich Stärken, Schwächen und Verbesserungspotentiale exakt identifizieren. Ein Hauptziel von Terminal-Bench ist es, einen objektiven Maßstab zur Quantifizierung der sogenannten "Terminal-Mastery" zu schaffen. Dies bedeutet, dass ein KI-Agent nicht nur theoretisches Wissen in einer Task zeigen soll, sondern diese auch korrekt und effizient in der Kommandozeilenumgebung ausführt. Die Benchmark ist deshalb so konzipiert, dass sie die reale Anwendungssituation nachbildet, in der Entwickler und Systemadministratoren täglich agieren.
Damit erlaubt Terminal-Bench eine praxisnahe Bewertung der Praktikabilität von KI-gesteuerten Automatisierungen. Die Entwicklung von Terminal-Bench ist eine Kollaboration zwischen Forschern renommierter Institutionen, darunter etwa Stanford University und Laude, und erhält Unterstützung durch Unternehmen wie Anthropic, die das Benchmarking nutzen, um neue Standards für KI-Agenten zu setzen. Indem die Plattform für Entwickler allgemein zugänglich gemacht wird, fördert sie einen offenen Wettbewerb und Innovationsschub im Bereich der KI-basierten Automatisierung. Die Vielfalt der in Terminal-Bench enthaltenen Aufgaben trägt dazu bei, unterschiedlichste Fähigkeiten zu prüfen. Zum Beispiel umfasst der Task "openssl-selfsigned-cert" die Erstellung eines selbstsignierten TLS-Zertifikats.
Hier muss der Agent nicht nur korrekte OpenSSL-Kommandos anwenden, sondern auch Verzeichnisstrukturen anlegen, Berechtigungen richtig setzen und abschließend die Gültigkeit des Zertifikats überprüfen. Dies erfordert eine Kombination aus technischer Expertise, präziser Ausführung und Wissen über Sicherheit. Weitere Aufgaben in der Plattform reichen von der Datenverarbeitung über Sicherheitsanalysen bis hin zur Systemadministration. Beispielsweise beinhaltet der Task "reshard-c4-data" die Umstrukturierung großer Datenmengen mit bestimmten Größen- und Ordnerbeschränkungen, gekoppelt mit der Entwicklung eines Revert-Skripts. Solche komplexen Anforderungen garantieren, dass ein KI-Agent nicht nur einfache Befehle korrekt ausführt, sondern auch komplexe Workflows sinnvoll abbildet.
Terminal-Bench bringt Vorteile sowohl für Forscher als auch für Praktiker. Für Entwickler von KI-Agenten ist die Plattform ein wertvolles Tool, um die Leistung ihrer Systeme messbar zu verbessern. Durch die Nutzung des Leaderboards erhalten Interessierte direkten Einblick, wie ihre Agenten im Wettbewerb mit aktuellen State-of-the-Art-Modellen abschneiden. Gleichzeitig fördert Terminal-Bench die Transparenz, indem es Einzelheiten der Task-Abläufe und Erfolgsraten offenlegt. Die Plattform integriert sich nahtlos in den Entwicklungsprozess von KI-Anwendungen, die in technischen, oft unstrukturierten Umgebungen wie der Kommandozeile operieren.
Besonders in Bereichen wie DevOps, IT-Sicherheit oder Systemmanagement lassen sich so Automatisierungspotenziale identifizieren und nutzen. Dies spart Unternehmen Zeit und Ressourcen, da aufwendige manuelle Tätigkeiten durch zuverlässige KI-Agenten ersetzt werden können. Ein weiteres starkes Merkmal von Terminal-Bench ist seine Offenheit und Erweiterbarkeit. Nutzer können neue Aufgaben beisteuern, die in realen Anwendungsfällen relevant sind. Dadurch entsteht eine lebendige Community, die kontinuierlich neue Herausforderungen einbringt und so den Fortschritt der KI in Terminalumgebungen fördert.
Diese Dynamik sorgt dafür, dass Terminal-Bench auch zukünftigen Anforderungen gerecht wird und mit dem technologischen Wandel Schritt hält. Die Verbindung von Terminal-Bench mit großen, modernen KI-Modellen wie Claude 4 zeigt, wie leistungsfähig diese Agenten mittlerweile sind. Unternehmen nutzen die Plattform zur Evaluierung und Optimierung, wodurch immer präzisere und vielseitigere Agenten entstehen. Das führt langfristig zu einer besseren Integration von KI in alltägliche IT-Prozesse. Für Einsteiger bietet Terminal-Bench zudem umfangreiche Dokumentation sowie eine aktive Discord-Community, in der sich Entwickler austauschen und Hilfestellung erhalten können.
Diese unterstützende Infrastruktur erleichtert den Zugang und fördert das Lernen in diesem komplexen Themenfeld. Aus Sicht der Suchmaschinenoptimierung punktet die Plattform durch umfangreiche, aktuelle Inhalte, die viele verschiedene Schlüsselbereiche der KI, Systemadministration und Sicherheit abdecken. Insgesamt bedeutet Terminal-Bench einen wichtigen Schritt hin zu praxisnaher Bewertung und Weiterentwicklung von KI-Agenten in textbasierten Umgebungen. Als Benchmark verbindet es technische Tiefe mit Anwenderfreundlichkeit und fördert Innovationen in einer Schlüsseltechnologie der Automatisierung. Für Unternehmen und Forschungseinrichtungen, die auf leistungsfähige KI-Lösungen im Bereich der Terminalumgebung angewiesen sind, stellt Terminal-Bench somit einen unverzichtbaren Referenzpunkt dar.
Die Zukunft der KI wird stark davon abhängen, wie gut diese Systeme in heterogenen und teils herausfordernden Umgebungen bestehen können. Terminal-Bench liefert dafür das notwendige Testfeld und trägt nachhaltig dazu bei, dass KI-Agenten nicht nur theoretisch, sondern auch praktisch überzeugen. Die kontinuierliche Erweiterung der Aufgaben, die Messbarkeit der Ergebnisse und die Förderung einer aktiven Community machen Terminal-Bench zu einem zentralen Bestandteil der KI-Forschung und -Entwicklung rund um Kommandozeilenlösungen. Wer innovative KI-Agenten entwickeln möchte, sollte Terminal-Bench als Referenzplattform kennen und nutzen. Neben der individuellen Leistungsbewertung lässt sich durch die Teilnahme am Wettbewerb ein direkter Vergleich mit anderen Entwicklerteams erreichen.
Das treibt den Fortschritt im Bereich intelligent gesteuerter Terminalprozesse voran – ein Aspekt, der künftig für viele Unternehmen unverzichtbar sein wird.


![What Every Computer Scientist Should Know About Floating-Point Arithmetic [pdf]](/images/69156BFE-5D72-4044-A59E-1C207FE961AA)