In der heutigen digitalen Ära gewinnt die Verarbeitung und Einbettung von Textdaten immer mehr an Bedeutung. Besonders bei Suchmaschinen, Empfehlungsdiensten oder künstlicher Intelligenz, die auf natürlicher Sprache basiert, sind präzise und effiziente Methoden für das Verstehen und Klassifizieren von Texten unerlässlich. Die Qwen3 Embedding-Serie stellt einen bedeutenden Meilenstein in der Weiterentwicklung dieser Technologien dar. Hinter diesem innovativen Ansatz steht ein leistungsfähiges Foundation-Modell, das nicht nur Textembedding, sondern auch Reranking auf einem bislang unerreichten Niveau ermöglicht. Die Qwen3 Modelle zeichnen sich durch ihre herausragende Vielseitigkeit und ihre hochentwickelten Fähigkeiten in der mehrsprachigen Textverarbeitung aus.
Während traditionelle Embedding-Modelle oft auf einzelne Sprachen oder domänenspezifische Daten beschränkt sind, unterstützt Qwen3 mehr als 100 Sprachen und bietet zudem umfangreiche Kompetenz im Umgang mit Programmiercode. Diese Multilingualität macht die Modelle besonders attraktiv für global agierende Unternehmen und Entwickler, die auf vielseitige, sprachübergreifende Anwendungen angewiesen sind. Ein zentrales Merkmal der Qwen3 Embedding-Serie ist die Kombination von Embedding- und Reranking-Modellen in verschiedenen Größenordnungen, die sich an unterschiedliche Anwendungsfälle und Performance-Anforderungen anpassen lassen. Die Modelle variieren von kompakten 0,6 Milliarden Parametern bis zu potenten 8 Milliarden Parameter-Versionen, wodurch sie sowohl ressourceneffiziente Lösungen als auch hochleistungsfähige Systeme ermöglichen. Diese Skalierbarkeit unterstützt Entwickler dabei, ihre Anwendungen individuell zu optimieren – sei es durch schnellere Antwortzeiten oder durch präzisere Suchergebnisse.
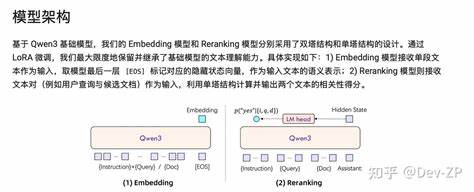
Die Architektur der Qwen3 Modelle ist dabei besonders durchdacht: Die Einbettungsmodelle basieren auf einem Dual-Encoder-Ansatz, bei dem einzelne Textsegmente semantisch erfasst und in hochdimensionale Vektorraumdarstellungen transformiert werden. Dies ist essenziell, um in großen Datenbeständen schnell relevante Dokumente zu identifizieren und effiziente Ähnlichkeitsberechnungen durchzuführen. Parallel dazu nutzt das Reranking-Modell eine Cross-Encoder-Struktur, die bei der Bewertung von Textpaaren eingesetzt wird, etwa bei der Relevanzbewertung von Suchanfragen gegenüber Ergebnissen. Diese Kombination erhöht die Treffergenauigkeit signifikant und verbessert die Nutzererfahrung in Such- und Retrieval-Systemen deutlich. Die Trainingmethodik von Qwen3 hebt die Modelle weit über herkömmliche Ansätze hinaus.
Ein mehrstufiger Trainingsprozess trägt entscheidend zur Leistungsfähigkeit bei: Zunächst durchläuft das Embedding-Modell eine kontrastive Vortrainingsphase mit umfangreichen, schwach überwachten Daten, um ein robustes Verständnis für die semantische Struktur von Texten zu entwickeln. Darauf folgt eine gezielte Supervised-Lernphase, die durch qualitativ hochwertige, manuell etikettierte Datensätze das Modell weiter verfeinert und anwendungsbezogen optimiert. Als abschließender Schritt werden verschiedene Kandidatenmodelle zusammengeführt, um deren Stärken zu bündeln und eine ausbalancierte Gesamtleistung zu gewährleisten. Diese Trainingstaktik stellt sicher, dass das Modell sowohl generalisierbar als auch anpassbar an spezielle Aufgabenstellungen bleibt. Besonders innovativ ist die im Training integrierte multi-taskfähige Prompting-Methode, bei der das Qwen3 Foundation Model seine Fähigkeiten zur Textgenerierung nutzt, um automatisch Textpaare zu erzeugen, die als Trainingsdaten für unterschiedliche Sprachen und Aufgaben dienen.
Diese methodische Neuheit erlaubt eine effiziente Skalierung des Trainingsdatensatzes und reduziert die Abhängigkeit von externen, oft unvollständigen Datenquellen. Daraus resultiert eine optimierte Trainingsbasis, die sich auf vielfältige Anwendungsbereiche übertragen lässt. Die Evaluationsergebnisse der Qwen3 Embedding- und Reranking-Modelle spiegeln ihre herausragende Leistungsfähigkeit wider. Auf bekannten Benchmarks wie MTEB, CMTEB und MMTEB schneiden die Modelle durchweg überdurchschnittlich ab. Besonders die größeren Modelle mit 4 und 8 Milliarden Parametern zeigen eine beeindruckende Steigerung in der Genauigkeit bei der Textähnlichkeitserkennung und der Relevanzbewertung von Dokumenten.
Ein Blick auf die Entwicklungsmetriken offenbart, dass Qwen3 Modelle in Rankings für mehrsprachige Texteingabe bei Google, Baidu und anderen großen Plattformen oft die Spitzenposition einnehmen. Dies unterstreicht ihre Dominanz im Bereich der intelligenten Textverarbeitung. Darüber hinaus besitzen die Qwen3 Modelle bemerkenswerte Flexibilitätsmerkmale. So können Nutzer bei der Einbettung eigene Dimensionen für die Vektoren definieren und mit Instruktionen die Modelle für spezifische Szenarien feinjustieren. Dies ist insbesondere für spezialisierte Branchenlösungen vorteilhaft, in denen die Genauigkeit der Repräsentation von Fachbegriffen oder Kontexten essentiell ist.
Auch die Einbindung von Programmiersprachen im Rahmen der Multilingualität eröffnet neue Anwendungsfelder für Code-Suche und -Analyse. Der Open-Source-Charakter der Qwen3 Embedding-Serie trägt ebenfalls maßgeblich zur starken Verbreitung bei. Durch die Veröffentlichung unter der Apache 2.0 Lizenz auf Plattformen wie Hugging Face und ModelScope können Entwickler weltweit auf die Modelle zugreifen, eigene Experimente durchführen und Innovationen vorantreiben. Die Bereitstellung des Quellcodes und technischer Berichte auf GitHub erhöht zudem die Transparenz und erleichtert die Integration in bestehende Systeme.
Im Hinblick auf die Zukunftsvisionen kündigt das Qwen Team fortlaufende Optimierungen der Foundation-Modelle an, die sowohl die Trainingsgeschwindigkeit als auch die Einsatzeffizienz weiter verbessern sollen. Geplant ist außerdem die Erweiterung in Richtung multimodaler Repräsentationen, die eine semantische Verknüpfung von Text, Bild und anderen Medienformaten ermöglichen. Dies könnte neue Möglichkeiten in Bereichen wie Cross-Modal Retrieval, personalisierte Assistenzsysteme oder automatisierte Inhaltsgenerierung schaffen. Die Einführung der Qwen3 Embedding-Serie markiert damit eine entscheidende Weiterentwicklung im Bereich der natürlichen Sprachverarbeitung. Durch die Kombination von technologischer Exzellenz, umfassender Mehrsprachigkeit und praktischer Anpassungsfähigkeit werden neue Maßstäbe gesetzt.