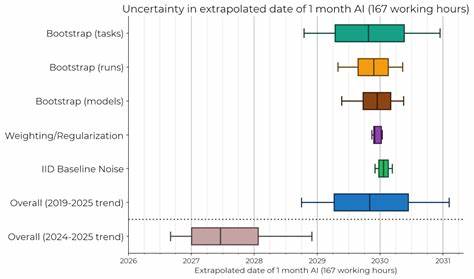
In den letzten Jahren haben große Sprachmodelle (Large Language Models, kurz LLMs) wie GPT, BERT und andere enorme Fortschritte gemacht und verändern viele Bereiche unserer Gesellschaft, von der Softwareentwicklung bis hin zur persönlichen Assistenz. Trotz dieser positiven Entwicklungen begegnet man häufig einer Vielzahl von Kritikpunkten und Missverständnissen zu diesen Technologien. Viele dieser Kritiken basieren auf falschen Annahmen oder ungenauen Vorstellungen davon, wie LLMs funktionieren und wie sie eingesetzt werden sollten. Eine differenzierte Betrachtung der häufigsten Fehlinterpretationen kann helfen, die Möglichkeiten und Grenzen von LLMs besser zu verstehen und den Diskurs über Künstliche Intelligenz (KI) insgesamt konstruktiver zu gestalten.Ein immer wieder auftauchendes Argument lautet, dass LLMs überbewertet seien.
Kritiker empfinden, dass die gigantische Aufmerksamkeit, die der KI derzeit zuteilwird, nicht mit dem tatsächlichen Nutzen für Gesellschaft und Wirtschaft korrespondiert. Sie schildern Erfahrungen, nach denen sich im Alltag wenig verändert habe, selbst wenn LLMs beispielsweise zum Schreiben von Softwarecode verwendet werden. Viele Unternehmen und Bildungsinstitutionen scheinen sich trotz der Fortschritte weiterhin auf herkömmliche Arbeitsweisen zu verlassen. Die Technik wirke zwar beeindruckend, habe aber noch nicht den grundlegenden Wandel gebracht, der oft vorausgesagt wird. Auch fühlen sich manche Nutzer angesichts der ständigen Berichterstattung über KI fast überfordert oder genervt und empfinden die Hypesituation als unangebracht.
Diese Kritik trifft teilweise zu, wenn der Blick nur auf den augenblicklichen Stand und die kurzfristige Wirkung gerichtet ist. Doch sie greift zu kurz, wenn sie die schnellen Fortschritte und das Potenzial für zukünftige Anwendungen außer Acht lässt. Tatsächlich verbessern sich LLMs kontinuierlich und können mittlerweile Aufgaben bewältigen, die vor einigen Jahren noch unvorstellbar waren. Beispielsweise unterstützen sie Entwickler bei komplexen Problemen, helfen bei Textanalysen oder liefern kreative Impulse. Die Integration von KI-Lösungen in bestehende Systeme und Prozesse befindet sich zwar oft noch in den Anfängen, doch es gibt laufend neue Beispiele von Unternehmen, die durch den Einsatz von LLMs effizienter und innovativer werden.
Darüber hinaus sinkt die Zahl der Stellenausschreibungen für klassische Softwareentwickler, was zumindest darauf hinweist, dass sich die Anforderungen der Arbeitswelt durch KI verändern.Noch komplexer wird die Diskussion, wenn der Nutzer eine klare Erwartung an eine Aufgabe formuliert und das Ergebnis von LLMs nicht den Vorstellungen entspricht. Viele Menschen gehen davon aus, dass sie eine „perfekte“ Antwort auf ihre Eingabe erhalten. In der Realität sind die Ausgaben von LLMs jedoch oft sehr variabel und hängen stark von der Qualität der Eingaben ab. Ein schlecht formulierter Prompt kann leicht zu unbrauchbaren oder unerwarteten Resultaten führen, die den Eindruck erwecken, das Modell sei „schlecht“ oder unzuverlässig.
Diese Erwartungshaltung ignoriert jedoch, dass der Umgang mit LLMs vergleichbar ist mit der Kommunikation mit einem Menschen: Je klarer und detaillierter die Fragestellung, desto besser wird in der Regel die Antwort. Erfolgreiche Anwender verbringen oft Zeit damit, ihre Eingaben sorgfältig zu gestalten und zu verfeinern, um optimale Ergebnisse zu erzielen.Die Schwierigkeit, zwischen einer „falschen“ und einer nur „unerwarteten“ Antwort zu unterscheiden, trägt erheblich zu der Kritik an LLMs bei. Wenn ein Modell eine Ausgabe liefert, die faktisch korrekt, aber nicht das ist, was der Nutzer sich vorgestellt hatte, entsteht schnell Frustration. Dies zeigt auch, dass der Umgang mit LLMs ein neues Kompetenzfeld verlangt, das sowohl technisches Verständnis als auch kommunikative Fähigkeiten umfasst.
Dass LLMs manchmal andere als erwartete Vorschläge liefern, sollte daher eher als Chance zur Erweiterung des Blickwinkels denn als Mangel wahrgenommen werden.Manche Kritiker verweisen darauf, dass LLMs Fehler machen, die Menschen in der realen Welt als fatal beurteilen würden – beispielsweise das unbeabsichtigte Löschen von Daten oder fehlerhafte Ausführung von Befehlen. Diese Fälle sind natürlich problematisch und sollten ernst genommen werden. Es ist aber wichtig, sie im Kontext menschlicher Fehleranfälligkeit zu sehen: Auch erfahrene Fachkräfte machen teils schwere Fehler. Der Unterschied ist, dass ein digitaler Fehler oft sehr schnell und umfassend wirken kann und daher besondere Vorsichtsmaßnahmen notwendig sind.
Der Umgang mit LLMs erfordert daher eine verantwortungsbewusste Implementierung und die Einbindung von Kontrollmechanismen, um Risiken zu minimieren. Das bedeutet allerdings nicht, dass LLMs grundsätzlich als „schlecht“ oder „gefährlich“ abgetan werden sollten, sondern vielmehr, dass wir ihre Eigenschaften, Risiken und Grenzen verstehen und berücksichtigen müssen.Ein weiterer oft geäußerter Kritikpunkt ist, dass LLMs „nur fancy Autocomplete“ seien – also nichts anderes als eine ausgeklügelte Version der Wortvervollständigung auf modernen Smartphones oder Textverarbeitungsprogrammen. Während diese Analogie auf den ersten Blick eingängig erscheint, greift sie bei näherer Betrachtung deutlich zu kurz. Die Fähigkeiten heutiger LLMs gehen weit über das Autovervollständigen von Wörtern hinaus.
Sie können komplexe Fragen beantworten, kreative Texte verfassen, technische Dokumentationen generieren, in unterschiedlichen Stilen schreiben und komplexe logische Zusammenhänge erfassen. Dies ist eine qualitative Stufe jenseits von einfachen Prognosen aufgrund von Wahrscheinlichkeiten im Vokabular. Zudem entwickeln LLMs Fähigkeiten, Konzepte zu verknüpfen, Schlüsse zu ziehen und sogar neue Lösungsideen vorzuschlagen. Ihre Anwendungsbereiche reichen bereits von Bildung über Softwareentwicklung bis hin zu kreativen Branchen.Trotz dieser Fortschritte ist es nachvollziehbar, dass manche Menschen skeptisch bleiben und die derzeitigen Modelle als noch zu limitiert empfinden.
Wissenschaftler und Entwickler sind sich einig, dass LLMs noch nicht den Stand perfekter Künstlicher Intelligenz erreicht haben. Es handelt sich vielmehr um leistungsfähige Werkzeuge mit eindeutig vorhandenen Schwächen. Besonders vermeidbare Fehler und mangelndes kontextuelles Verständnis führen weiterhin zu Herausforderungen. Zudem ist die Geschwindigkeit der Verbesserung heute nicht mehr so rasant wie in den Anfangsjahren der KI-Forschung. Einige Stimmen innerhalb der Community sehen bereits eine Art Plateau erreicht, andere gehen davon aus, dass tiefgreifende Durchbrüche durch neue Ansätze oder zusätzliche Datenquellen noch bevorstehen.
Diskussionskultur und differenzierte Betrachtung sind Schlüssel, um die Faszination und Herausforderungen von LLMs gleichermaßen zu würdigen. Es ist weder hilfreich, LLMs ausschließlich zu idealisieren, noch sie pauschal zu verteufeln. Ein ausgewogener Blick erkennt, dass LLMs hochkomplexe Systeme sind, die durch stetige Verbesserungen und kreative Anwendungen tatsächlich viele Möglichkeiten eröffnen, aber stets auch kritisch reflektiert werden müssen. In der öffentlichen Debatte hilft es, Lazy Criticisms zu vermeiden – also vereinfachte oder unscharfe Urteile, die weder die Komplexität der Technologie erfassen noch konstruktive Impulse geben.Zusammenfassend lässt sich festhalten, dass große Sprachmodelle einen signifikanten Fortschritt darstellen, der viele Herausforderungen mit sich bringt.
Die falschen oder ungenauen Kritikpunkte entstehen oft aus unrealistischen Erwartungen, Missverständnissen des technischen Prinzips oder mangelndem Wissen über die richtige Nutzung der Modelle. Wer sich mit LLMs beschäftigt, sollte offen für Experimente und das Erlernen ihrer Besonderheiten sein, um das volle Potenzial zu entfalten. In Zukunft kann die Weiterentwicklung von LLMs nicht nur bestehende Prozesse verbessern, sondern auch völlig neue Anwendungsfelder eröffnen. Die Debatte über LLMs wird daher weitergehen – hoffentlich mit mehr Nuancen und weniger pauschaler Ablehnung, um die technologiegetriebene Zukunft gemeinsam sinnvoll zu gestalten.