Die rasante Entwicklung von Künstlicher Intelligenz (KI) hat in den letzten Jahren bedeutende Fortschritte im Bereich der Large Language Models (LLMs) hervorgebracht. Während allgemeine Sprachmodelle wie ChatGPT beeindruckende Fähigkeiten demonstrieren, stoßen sie im medizinischen Bereich auf spezielle Herausforderungen. Medizinisches Fachwissen ist nicht nur tiefgreifend und komplex, sondern auch für die korrekte Diagnose und Behandlung essenziell. Insbesondere professionelle Kenntnisse, hohe Rechenressourcen und die Anforderungen an sichere und effiziente Einsatzumgebungen erschweren das direkte Anwenden allgemeiner Modelle in der Medizin. Genau hier setzt die Methode rund um die Architektur eines medizinischen vertical Large Language Models basierend auf Deepseek R1 an und bietet wichtige Lösungen für die medizinische KI-Community.
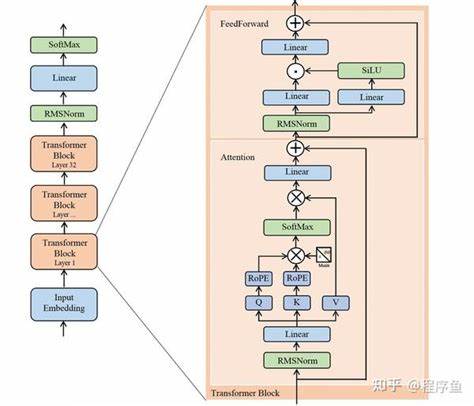
Das primäre Ziel besteht darin, ein qualitativ hochwertiges, leichtgewichtiges Modell zu entwickeln, welches zugleich fachlich präzise und ressourceneffizient arbeitet. Ein solcher medizinischer vertical LLM (Low Vertical Large Language Model) zielt darauf ab, das Fachwissen zielgerichtet auf medizinische Anwendungen auszurichten und gleichzeitig die technische Machbarkeit, insbesondere bei eingeschränkten Ressourcen wie bei Edge-Computing-Geräten, sicherzustellen. Die Grundlage dafür ist Deepseek R1, ein leistungsfähiges, aber gleichzeitig anpassungfähiges Modell, welches als Ausgangspunkt für die Entwicklung dient. Das Besondere an diesem Ansatz ist die Berücksichtigung dreier zentraler Dimensionen: Wissensaufnahme und -transfer, Modellkompression sowie Rechenoptimierung. Diese kombinierte Vorgehensweise ermöglicht es, die typischen Botlenecks bei großen Modellen zu überwinden und exakt auf die medizinischen Anforderungen zuzuschneiden.
Im Bereich des Wissenstransfers erfolgt eine gezielte Feinabstimmung durch sogenannte Teacher-Student-Modelle. Das heißt, ein großes, gut trainiertes „Lehrermodell“ – in diesem Fall Deepseek-R1-Distill-70B – überträgt seine relevanten medizinischen Kenntnisse an ein kleineres „Schülermodell“ (Deepseek-R1-Distill-7B). Dadurch wird die Expertise erhalten, während die Modellgröße erheblich reduziert wird. Besonders innovative Techniken wie Low-Rank Adaptation (LoRA) kommen zum Einsatz, um die wichtigsten Aufmerksamkeitsmechanismen im Modell präzise und effizient anzupassen. LoRA ermöglicht eine sehr gezielte und ressourcenschonende Weiterentwicklung eines Modells, indem nur kleinere Parameterbereiche aktualisiert werden, was die Trainings- und Speicheranforderungen spürbar minimiert.
Im Bereich der Modellkompression wird eine der größten Herausforderungen adressiert: Wie kann die Leistungsfähigkeit bei geringer Modellgröße erhalten bleiben? Dies gelingt durch den Einsatz fortschrittlicher Komprimierungsmethoden wie der 4-Bit-Quantisierung für Gewichte. Diese Technik reduziert Speicherbedarf und Rechenlast drastisch, ohne die für medizinische Schlussfolgerungen notwendige Genauigkeit und Repräsentationsfähigkeit zu verlieren. Die Balance zwischen Einsparungen und Performance ist hierbei entscheidend, um sowohl Effizienz als auch Sicherheit und Zuverlässigkeit zu garantieren. Auf der Ebene der Rechenoptimierung setzt das Modell auf moderne Beschleunigertechniken während der Inferenzphase. Flash Attention beispielsweise vermindert die Rechenzeit durch effiziente Speicher- und Verarbeitungsstrategien bei der Berechnung von Aufmerksamkeitsmechanismen.
Kontinuierliches Batching wiederum optimiert die parallele Verarbeitung mehrerer Anfragen, was gerade im medizinischen Kontext, wo Echtzeitantworten entscheidend sind, große Bedeutung hat. Ergänzt wird dies durch ein speziell entwickeltes Prompt-Templatesystem, welches unterschiedliche Arten medizinischer Fragen erkennt und individuell darauf eingeht. Dieses System gewährleistet, dass das Modell kontextspezifisch reagieren kann und damit die Interaktion mit Fachpersonal oder Patienten optimiert wird. Die wichtigsten Ergebnisse basieren auf umfangreichen Experimenten mit medizinischen Frage-Antwort-Datensätzen, die die Wirksamkeit der Methode demonstrieren. Trotz deutlicher Reduktionen im Speicher (über 60 Prozent Einsparung) und einer Verbesserung der Antwortzeit (knapp 12 Prozent schnellere Inferenz) konnte das Modell eine stabile und fachlich genaue Leistung erbringen.
Dies ist ein entscheidender Durchbruch vor allem für den Einsatz in ressourcenbeschränkten Umgebungen wie Krankenhäusern mit begrenzter IT-Infrastruktur, mobilen Geräten oder Edge-Computing-Lösungen. Die Kombination aus wissenschaftlicher Methodik und technischer Umsetzung macht das vorgeschlagene System zu einem wichtigen Schritt auf dem Weg hin zur Demokratisierung von medizinischer KI. Die Nutzung von LLMs wird damit nicht mehr nur hoch spezialisierten Forschungsinstituten oder großen Unternehmen vorbehalten, sondern kann auch in kleineren Kliniken und Praxen sinnvoll eingesetzt werden. Die Grundprinzipien der Architektur von Deepseek R1 eröffnen dabei vielfältige Anwendungsfelder. Neben der direkten Diagnosestellung zählen vor allem das interaktive Training von Medizinstudenten, das Bereitstellen von evidenzbasierten Therapieempfehlungen, Patientenaufklärung oder auch automatische Dokumentation zu möglichen Einsatzgebieten.
Die hohe Effizienz sorgt zusätzlich für eine bessere Nachhaltigkeit in der medizinischen IT und verringert den ökologischen Fußabdruck der eingesetzten Technologien. Neben den praktischen Vorteilen ist der Ansatz auch aus Sicht der Forschung relevant. Die Integration von LoRA-Techniken, quantifizierter Kompression und Inferenzoptimierung beschreibt innovative Wege, wie LLMs spezialisierte Fachdomänen bedienen können, ohne an Leistung oder Sicherheit einzubüßen. Die iterative Verfeinerung über Teacher-Student-Modelle zeigt zudem den Weg für zukünftige Entwicklungen, bei denen bestehende große Modelle als Wissensquellen für kleinere, domänenspezifische Modelle fungieren können. Die Herausforderungen im Einsatz von KI im medizinischen Sektor sind bekannt: Datenschutz, Erklärbarkeit, Validität der Informationen und Einhaltung regulatorischer Vorgaben benötigen stete Aufmerksamkeit.