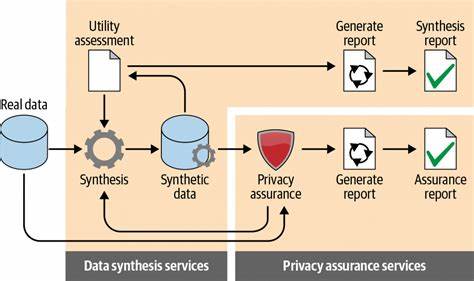
Die Erzeugung synthetischer Daten hat sich zunehmend als ein zukunftsweisendes Konzept sowohl innerhalb akademischer Kreise als auch in der unternehmerischen Praxis etabliert. Während die Forschung an Universitäten und Forschungseinrichtungen oft im Mittelpunkt solcher Entwicklungen steht, stellt sich vielfach die Frage, wie praktikabel und effektiv diese Technologie außerhalb der akademischen Sphären tatsächlich ist. Die Diskussion über die Anwendbarkeit synthetischer Datenbasierten Modelle und Pipelines gewinnt in der Praxis immer mehr an Bedeutung und wirft spannende Fragestellungen auf, die tiefgehendes Verständnis und langfristige Perspektiven erfordern. Synthetische Daten werden grundsätzlich generiert, um reale Daten entweder zu ergänzen oder zu ersetzen. Sie entstehen durch KI-Modelle, Simulationen oder speziell entwickelte Algorithmen, die auf Basis existierender Muster neue, realistisch anmutende Daten erzeugen.
Ein erheblicher Vorteil liegt in der Möglichkeiten, durch synthetische Daten sensible oder schwer zugängliche Informationen zu ersetzen und dadurch Datenschutzprobleme zu umgehen, ohne dabei auf die nötige Datenvielfalt verzichten zu müssen. Dieser Punkt ist gerade in Branchen mit hohen regulatorischen Anforderungen, wie dem Gesundheitswesen, dem Finanzsektor oder der öffentlichen Verwaltung, von besonderem Interesse. Die jüngsten Fortschritte großer Sprachmodelle (Large Language Models, LLMs) haben die Fähigkeit zur Erzeugung qualitativ hochwertiger synthetischer Daten signifikant verbessert. LLMs können zum Beispiel für die Generierung von Frage-Antwort-Paaren, die Nachbildung komplexer Gedankengänge oder das Entwickeln von Datenstrukturen genutzt werden, die bei der Entwicklung von Modellen für spezifische Aufgaben sehr hilfreich sind. Das Training kleinerer, spezialisierterer Modelle wird dadurch oftmals schneller und effizienter, was gerade in der Industrie, wo Rechenressourcen und Zeit Kostentreiber sind, einen erheblichen Mehrwert darstellt.
Trotz dieser Fortschritte ist es jedoch so, dass viele der bislang vorgestellten synthetischen Datenpipelines noch stark forschungsorientiert sind. Der Transfer in produktive Umgebungen ist in vielen Fällen noch nicht vollumfänglich gelungen. Es fehlt oft an robusten Anwendungsbeispielen, die unter realen, oft auch „dreckigen“ und unvorhersehbaren Bedingungen zuverlässig funktionieren. In der Praxis hat sich gezeigt, dass die Realität nicht selten deutlich komplexer und unberechenbarer ist als die sauberen, idealisierten Datensätze, mit denen viele akademische Modelle trainiert wurde. Beispielsweise kann die Aufbereitung von Daten aus medizinischen Geräten oder industriellen Anlagen oftmals eine ganz andere Herausforderung darstellen als die Konstruktion synthetischer Datensätze im Labor.
Dennoch gibt es Industriezweige, in denen der Einsatz synthetischer Daten bereits heute sinnvoll und in einigen Fällen unerlässlich ist. Besonders in Bereichen, in denen Datenschutz und Nutzungssicherheit eine große Rolle spielen, ermöglichen synthetische Daten den Aufbau von Prototypen und eine beschleunigte Entwicklung von Machine-Learning-Modellen, ohne sensible Originaldaten offenlegen zu müssen. Unternehmen aus dem Bereich der Dokumentenverarbeitung profitieren beispielsweise davon, große Mengen unterschiedlich strukturierter Eingabedaten synthetisch zu generieren, um damit kleinere, schneller reagierende Modelle zu trainieren und den Workflow insgesamt zu optimieren. Auch im Bereich der Empfehlungssysteme und der Internetsuche wurde die Synthese künstlicher Daten bereits eingesetzt, um Herausforderungen wie den „Cold Start“ zu überwinden, bei dem für neue Produkte oder Nutzer noch keine realen Interaktionsdaten vorliegen. So wird versucht, mit synthetischen Klick- oder Bewertungsdaten das Nutzerverhalten zu simulieren, um Modelle vorab zu trainieren.
Das führt nicht nur zu einer besseren Performance neuer Systeme, sondern kann auch Kosten reduzieren, die sonst durch den langwierigen Aufbau von realen Datenbeständen entstehen würden. Die Qualität synthetischer Daten ist hierbei ein entscheidender Erfolgsfaktor. Sie bestimmt maßgeblich, wie gut die daraus trainierten Modelle in der Realität funktionieren. Qualitätssicherung bei synthetischen Daten ist allerdings eine Herausforderung, da eine objektive Bewertung nicht immer leicht möglich ist. Unternehmen und Entwickler nutzen hier verschiedene Verfahren, um sicherzustellen, dass die künstlich erzeugten Daten tatsächlich repräsentativ für die Einsatzbedingungen sind.
Dazu gehören Testverfahren, bei denen die Modelle mit realen Daten validiert werden, oder der direkte Vergleich statistischer Kennzahlen. Offene Toolkits und Werkzeuge vereinfachen mittlerweile den Einstieg und die Integration synthetischer Datenpipelines in industrielle Anwendungen. Open-Source-Projekte erleichtern den Zugang zu dieser Technologie und senken die Einstiegshürden, was vor allem für kleinere Betriebe oder Start-ups wichtig ist, die sich keine hochspezialisierten internen Forschungsabteilungen leisten können. Dies fördert eine breitere Nutzung und weitergehende Innovationen im praktischen Einsatz. Darüber hinaus eröffnet die kontinuierliche Verbesserung der KI-Modelle neue Möglichkeiten, synthetische Daten immer realistischer und damit anwendbarer zu gestalten.
Die Fähigkeit großer Modelle, komplexe Zusammenhänge abzubilden, kann dazu führen, dass künftig auch Szenarien abgedeckt werden, die bislang als zu komplex oder zu speziell galten. Insbesondere in Anwendungsfeldern mit sequenziellen oder zeitabhängigen Daten, wie der Analyse von medizinischen oder technischen Sensorinformationen, könnten diese Fortschritte bahnbrechend sein. Die Zukunft der synthetischen Datengenerierung außerhalb akademischer Einrichtungen hängt aber nicht nur von technischen Fortschritten ab. Es bedarf auch eines verbesserten Verständnisses über die Grenzen und Einsatzmöglichkeiten sowie einer stärkeren Etablierung entsprechender Standards. Kooperationen zwischen der Forschung und Industrie, der Austausch von Best Practices und die Entwicklung gesetzlicher Rahmenbedingungen werden dabei eine maßgebliche Rolle spielen.
Zusammenfassend lässt sich sagen, dass synthetische Daten zwar weiterhin ein stark forschungsgetriebenes Feld sind, sie aber bereits heute außerhalb der akademischen Welt praktischen Mehrwert bieten und Potenzial besitzen, in vielen Branchen eine Schlüsseltechnologie zu werden. Auch wenn es noch Herausforderungen gibt, zeigen Beispiele aus der Praxis, insbesondere aus sicherheitskritischen und datenintensiven Bereichen, dass synthetische Datengeneration ein effektives Werkzeug zur Beschleunigung der Modellentwicklung und zur Verbesserung von Datenschutzmaßnahmen sein kann. Im Zuge der technologischen Weiterentwicklung und einer stärkeren Verbreitung wird sich die Praxisrelevanz noch weiter erhöhen und die Brücke zwischen Theorie und industrieller Anwendung immer stabiler gebaut werden.