Die Sicherstellung der Datenintegrität auf Fileservern ist ein zentraler Aspekt moderner IT-Infrastrukturen. Nutzer, die große Mengen an Dateien über Netzwerke übertragen und speichern, fragen sich häufig, ob es notwendig oder sinnvoll ist, eigene Integritätsprüfungen zu implementieren. Die Herausforderung besteht darin, Datenverlust oder -beschädigung frühzeitig zu erkennen und zu verhindern, um die Zuverlässigkeit und Verfügbarkeit von Daten zu gewährleisten. Dabei stellt sich auch die Frage, wie viel Aufwand in individuelle Lösungen investiert werden soll, wenn bestehende Systeme und Protokolle bereits Mechanismen für Datenintegrität mitbringen. Die Rolle von Betriebssystemen und Dateisystemen bei der Datenintegrität darf dabei nicht unterschätzt werden.
Moderne Betriebssysteme wie Ubuntu 24.04.2 LTS nutzen fortschrittliche Dateisysteme wie ZFS oder btrfs, welche eingebaute Funktionen zur Fehlererkennung und Fehlerkorrektur bieten. Diese Systeme arbeiten mit Prüfsummen, die automatisch bei jedem Schreibvorgang generiert und beim Lesen überprüft werden. Somit können Datenkorruptionen erkannt und teilweise auch behoben werden, bevor der Anwender den Schaden bemerkt.
Diese native Unterstützung reduziert die Notwendigkeit, zusätzliche Integritätsprüfungen manuell einzuführen. Ein weiteres Element, das häufig übersehen wird, ist das Protokoll, das bei der Datenübertragung verwendet wird. Das SFTP-Protokoll (Secure File Transfer Protocol) implementiert bereits eine Art von Fehlererkennung, indem es Prüfsummen auf Paketebene verwendet. Dies bedeutet, dass während der Datenübertragung von einem Server zu einem Client Fehler durch fehlerhafte Bits oder Übertragungsstörungen erkannt werden. Zudem ist die Datenübertragung verschlüsselt, sodass nicht nur die Integrität, sondern auch die Vertraulichkeit der Daten gesichert ist.
In Summe minimiert dies das Risiko, dass Dateien während des Downloads beschädigt werden oder Daten manipuliert werden können. Trotz dieser integrierten Maßnahmen gibt es Szenarien, in denen eigene Integritätsprüfungen auf Dateiebene sinnvoll sein können. Beispielsweise wenn ein besonders hoher Anspruch an Datenverlässlichkeit besteht oder wenn das Risiko von Datendiskrepanzen zwischen Server und lokalem Client aufgedeckt und ausgeschlossen werden soll. Dies betrifft vor allem Situationen, in denen sensible oder kritische Daten übertragen werden, die nicht durch ein Änderungsprotokoll oder Versionskontrolle abgesichert sind. Hier kann das Hashing von Dateien auf Server- und Clientseite eine unkomplizierte Methode sein, um Übereinstimmung sicherzustellen.
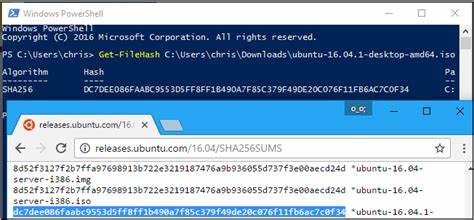
Bei der Implementierung konkreter Integritätsprüfungen ist jedoch zu bedenken, dass das permanente Erzeugen von Hashes für jede Datei Leistungsressourcen beansprucht. Die Berechnung komplexer Prüfsummen wie SHA-256 kann bei großen Dateien oder bei intensiven Schreiboperationen spürbare Verzögerungen verursachen. Im Praxisalltag kann dies die Nutzererfahrung verschlechtern, insbesondere wenn viele Dateien gleichzeitig verarbeitet werden oder wenn der Fileserver stark frequentiert ist. Deshalb ist es ratsam, den konkreten Bedarf genau abzuwägen und Optimierungen zu integrieren, etwa durch inkrementelle Hashberechnungen oder die Nutzung von Prüfsummen nur bei Bedarf. Ein weiterer Punkt ist die Frage des Bedrohungsmodells.
Wird die Integritätsprüfung ausschließlich gegen zufällige Fehler und Korruption durchgeführt, die beispielsweise durch Hardwareprobleme ausgelöst werden, ist das Risiko grundsätzlich geringer. Funktionsfähige Dateisysteme und sichere Übertragungsprotokolle greifen hier gut ineinander. Anders verhält es sich, wenn die Möglichkeit von Manipulationen durch Dritte ein Thema ist. In einem solchen Sicherheitskontext sind umfassende Kontrollen wie digitale Signaturen und verschlüsselte Prüfsummen unumgänglich, was die Komplexität und den Aufwand weiter erhöht. Zusammenfassend benötigt nicht jeder Nutzer zwingend eigene Integritätsprüfungen.
Die Technologie hinter modernen Dateisystemen und Protokollen erfüllt viele Anforderungen an Datenzuverlässigkeit und Schutz gegen Übertragungsfehler bereits effektiv. Dennoch gibt es spezielle Anwendungsfälle, in denen eine zusätzliche Absicherung durch lokale Hashvergleiche oder andere Verfahren sinnvoll ist. Entscheidend ist, dass die Implementierung von Integritätsprüfungen immer auf das individuelle Szenario und die zu schützenden Daten abgestimmt wird, um einen ausgewogenen Kompromiss zwischen Sicherheit, Performance und Aufwand zu erreichen. Ein systematischer Ansatz empfiehlt sich: zunächst die vorhandenen Funktionen und Konfigurationen des Betriebssystems und der Dateisysteme anzuschauen. Danach sollte geprüft werden, ob die Netzwerksicherheit und Datenübertragungsverfahren ausreichend sind oder ob individuelle Integritätschecks nötig sind.
Es hilft auch, sich mit Experten und entsprechenden Communitys auszutauschen, um Best Practices und potentielle Fallstricke zu erfassen. Langfristig sorgt eine gut durchdachte Kombination aus hardwarenaher Faktenprüfung und auf Protokollebene abgesicherten Übertragungen für ein robustes Sicherheitskonzept, ohne unnötigen Mehraufwand zu generieren. Die gravierenden Vorteile moderner Filesysteme wie ZFS liegen in deren Fähigkeit zur Selbstheilung. Wenn Fehler entdeckt werden, können diese automatisiert korrigiert werden, sofern entsprechende Redundanzen vorhanden sind. Dies ermöglicht eine nahezu transparente Datenkorrektur, die Nutzer kaum bemerken.