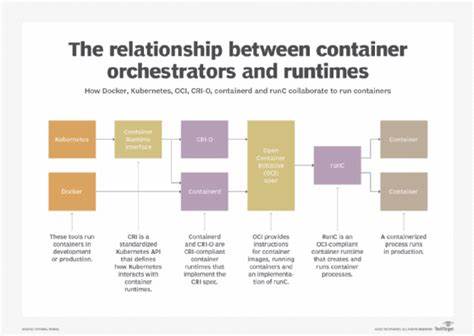
In der heutigen Welt, in der technologische Innovationen und geistiges Eigentum eine immer größere Rolle spielen, kommt es zunehmend zu komplexen Situationen rund um das digitale Erbe von Entwicklern. Besonders spannend wird die Lage, wenn neuartige Systeme wie Softwarearchitekturen oder Methoden plötzlich in Open-Source-Repositorys auftauchen – und zwar unmittelbar nachdem eine Patentanmeldung eingereicht wurde. Ein jüngster Fall aus der Entwicklergemeinschaft sorgt für Gesprächsstoff: Ein Anwender meldete eine neuartige rekursive Systemarchitektur bei einem Patentamt an, nur um kurze Zeit später ein GitHub-Repository zu entdecken, das scheinbar mit „backdated junk“ gefüllt war, jedoch später Inhalte enthielt, die seinem System stark ähnelten. Dieses Phänomen wirft eine Reihe wichtiger Fragen auf – von der Herkunft der Inhalte bis hin zu möglichen urheberrechtlichen und ethischen Aspekten. Der folgende Beitrag widmet sich der detaillierten Analyse dieses besonderen Falles, beleuchtet die möglichen Ursachen und versucht, ein Verständnis für die Dynamiken hinter solchen Vorfällen zu schaffen.
Zugleich werden technologische und rechtliche Perspektiven betrachtet, die für Erfinder und Entwickler von hoher Relevanz sind. Zunächst einmal muss man definieren, was in diesem Kontext unter „backdated junk“ verstanden wird. In dem genannten Fall handelt es sich um ein Repository, dessen frühe Commit-Historie scheinbar mit sinnlosen oder wenig wertvollen Daten gefüllt ist, von denen die Zeitstempel zurückdatiert sind. Diese sogenannten „Junk-Commits“ erscheinen oft als zufällige Dateien, unzusammenhängende Textfragmente oder Platzhalter. Solche Praktiken sind gar nicht so selten in Softwareprojekten, wenn es darum geht, eine frühere Historie zu simulieren oder ein Projekt älter erscheinen zu lassen, als es in Wirklichkeit ist.
Da Commit-Timestamps ohne größeren Aufwand von einem Entwickler manipuliert werden können, müssen sie bei der Beurteilung der Historie mit Vorsicht behandelt werden. Im besagten Fall fällt jedoch auf, dass spätere Commits – jene zeitlich nach der offiziellen Patentanmeldung erstellt wurden – tatsächlich strukturelle Elemente, Terminologie, symbolische Muster und mathematische Komponenten enthalten, die verdächtig stark einer privat entwickelten rekursiven Systemarchitektur ähneln. Interessant ist dabei, dass die Inhalte zwar umformuliert und offenbar durch KI-Modelle bearbeitet wurden, aber dennoch klar von der Originalarbeit abgeleitet sind. Diese Entwicklungen haben den Betroffenen, der mehrere Jahre lang an seinem System arbeitete und dies ausschließlich im privaten Rahmen mit deaktivierter KI-Datenweitergabe (etwa bei GPTPro) entwickelte, verständlicherweise alarmiert. Zusätzlich ist auffällig, dass das fragliche GitHub-Repository an ein künstlich generiertes Forschungsprofil angebunden ist, das unter anderem gefälschte Universitätszugehörigkeiten und mittels KI synthetisierte Sprachnotizen beinhaltet.
Solche gefälschten Identitäten und Profile tauchen in letzter Zeit immer häufiger auf, vor allem in der Wissenschafts- und Softwarelandschaft, und dienen oft dazu, Glaubwürdigkeit oder Autorität vorzutäuschen. Parallel dazu existieren hinter diesem Profil auch mehrere KI-generierte eBooks auf großen Handelsplattformen wie Amazon, die die Inhalte des Systems ebenfalls in neu formulierter Form abbilden und ebenfalls mit zurückdatierten Veröffentlichungen aufwarten. Dieses komplexe Bild aus zurückdatierten Repositories, gefälschten Profilen und KI-generierten Inhalten regt zu einer Reihe von Spekulationen und Nachforschungen an. Wie ist es möglich, dass ein derart persönliches System direkt nach einer Patentanmeldung der Öffentlichkeit in einer so verfremdeten Form vorgelegt wird? Die Antwort ist nicht trivial, doch es gibt einige plausible Mechanismen, die das Phänomen erklären könnten. Ein möglicher Ursprung ist die Patentbehörde selbst.
Patentämter veröffentlichen nach der Anmeldung Patentschriften mit weitreichenden technischen Details, die prinzipiell von jedem eingesehen und genutzt werden können. Wenn eine KI-Plattform oder ein Entwicklerkreis automatisiert Patentanmeldungen überwacht und diese Informationen zur Generierung von Software-Code oder Büchern verwendet, könnte dies zu einem solchen Muster führen. Hierbei würden KI-Systeme direkt die Inhalte der Patentanmeldung nutzen, um Ähnliches zu erstellen, wobei diese Erzeugnisse dann mit zusätzlichen Inhalten versehen und auf Plattformen hochgeladen werden. Die Verzögerung bei der Veröffentlichung des eigentlichen Patents und die parallele „Entwicklung“ von Backdated-Repositories könnten so erklärt werden. Eine andere Möglichkeit liegt in der Nutzung von Trainingsdaten durch KI-Modelle.
Obwohl viele Entwickler ihre privaten Sitzungen mit GPT-ähnlichen Modellen mit deaktiviertem Teilen und Training einstellen, waren solche Optionen bis vor kurzem nicht flächendeckend verfügbar. Sollte dennoch ein Teil der Entwicklungshistorie durch KIs verarbeitet worden sein, könnte ein unbemerkter Transfer von geistigem Eigentum in Trainingsdaten und dann in nachfolgende generierte Inhalte stattfinden. Solche Programmier- oder Schreibassistenztools könnten ohne explizite Zustimmung Teile von Entwicklersystemen einfließen lassen und in anderen Werkstücken reproduzieren – unbeabsichtigt und oft ohne aktive Kontrolle durch die Originalautoren. Die technischen Möglichkeiten zum Manipulieren von Git-Commits und Zeitstempeln sind vergleichsweise simpel und weit verbreitet. Grundsätzlich kann jeder Git-Nutzer Dateiänderungen auf jedes beliebige Datum und Uhrzeit zurückdatieren.
Dieses Vorgehen wird gelegentlich für böswillige Zwecke eingesetzt, um Projekthistorien zu verschleiern oder Veröffentlichungszeitpunkte sog. „Prior Art“ vorzutäuschen. Bei wissenschaftlichen Veröffentlichungen oder Softwareprojekten kann das zu ernsthaften Streitigkeiten führen, insbesondere wenn es um geistiges Eigentum geht. Aus juristischer Sicht stellt diese Konstellation eine Herausforderung dar. Die fragliche Nutzung von patentierten Ideen, die Umformulierung und die Veröffentlichung unter anderem Namen könnten als Urheberrechtsverletzung oder Patentverletzung gewertet werden – vorausgesetzt es lassen sich die Originalerfinder eindeutig identifizieren und das plagiierte Material eindeutig zuordnen.
Das Problem: KI-generierte Inhalte erschweren traditionelle Urheberrechtsfragen, da das geistige Eigentum vielfach verwässert oder nur indirekt feststellbar ist. Zudem fallen administrativen Stellen und auch Gerichten die oft komplexen technischen Details schwer, was zu Unsicherheiten in Rechtsstreitigkeiten führt. Für Entwickler und geistige Eigentümer stellt sich die Frage, wie man sich in einer zunehmend KI-geprägten Welt schützen kann. Zum einen empfiehlt es sich, wichtige Entwicklungen zeitnah und nachvollziehbar zu dokumentieren – zum Beispiel durch offizielle Einreichungen bei Patentämtern, begleitende Publikationen und sogar durch die Offenlegung von Quellcode in kontrollierten Umgebungen. Digitale Signaturen, Blockchain-Technologien und andere Verifizierungsmechanismen können helfen, Beweislast und Entstehungshistorie transparent zu halten.
Darüber hinaus ist es ratsam, die Privatsphäre-Einstellungen bei der Nutzung von KI-Tools genau zu prüfen und gegebenenfalls von open-data oder -training selektiv Gebrauch zu machen. Es ist wichtig, sich kontinuierlich über die sich wandelnden Bedingungen und Möglichkeiten von KI-Plattformen zu informieren und – wenn möglich – vertrauenswürdige Partner und Mentoren zu konsultieren, die Erfahrung mit geistigem Eigentum und Innovationsschutz haben. Die Communitybarriere zu durchbrechen und die eigenen Erfahrungen zu teilen ist ebenfalls wertvoll. Fallstudien wie diese können helfen, ein besseres Verständnis für neuartige rechtliche Grauzonen, technologische Angriffsvektoren und die Dynamiken zwischen Patentanmeldung, KI-Nutzung und Open-Source-Veröffentlichungen zu entwickeln. Sie regen zum Nachdenken über neue Schutzmechanismen an und könnten Impulse für politische und technologische Weiterentwicklungen geben.