Im Zeitalter der künstlichen Intelligenz erleben wir eine rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs), die zunehmend komplexe, mehrstufige Aufgaben übernehmen. Trotz beeindruckender Fortschritte zeigt sich eine stille, aber weitreichende Problematik: Fehler, die sich durch jede Stufe der Verarbeitung fortpflanzen und in Folge signifikante Fehlschläge verursachen können. Diese sogenannte Fehlerakkumulation ist kein neues Phänomen, sondern eine gut erforschte Herausforderung aus der Informatik und Robotik, die jedoch bislang in der KI-Gemeinschaft nicht ausreichend adressiert wird. Die daraus resultierenden Fehlfunktionen großer Sprachmodell-Agenten wirken auf den ersten Blick oft unbedeutend, können sich jedoch exponentiell verschärfen und mit potenziell katastrophalen Folgen in produktiven Anwendungen enden. Die Grundlagen der Fehlerfortpflanzung wurden von Pionieren der Computerwissenschaft bereits Mitte des 20.
Jahrhunderts gelegt. Wilkinson etwa wies in den 1960er Jahren darauf hin, dass numerische Ungenauigkeiten bei aufeinanderfolgenden Rechenschritten systematisch zunehmen, wenn keine Korrekturmechanismen integriert sind. Goldberg betonte später, dass auch einfache Berechnungen durch kumulative Präzisionsverluste anfällig für Fehler sind, was zur Einführung des IEEE 754-Standards führte, der Gleitkommazahlen präzise und kontrolliert handhabbar macht. Diese theoretischen Erkenntnisse bildeten das Fundament für Zuverlässigkeit und Sicherheit in vielen klassischen Computingsystemen, von der Finanztechnologie bis zur Raumfahrt. In der Robotik, einem Gebiet, in dem physische Fehler unmittelbar sicht- und spürbar sind, wurde das Problem der Fehlerakkumulation konsequent analysiert und technisch adressiert.
Sensorrauschen, Positionsungenauigkeiten und Unsicherheiten in der Umgebungswahrnehmung führen zu einer exponentiellen Verstärkung von Fehlern im Bewegungsablauf und in Umgebungsmodellen. Die Antwort waren robuste Algorithmen wie SLAM (Simultane Lokalisierung und Kartierung), Kalman-Filter und andere probabilistische Verfahren, die kontinuierlich Unsicherheiten quantifizieren und korrigieren. Das Ergebnis sind Systeme, die in der Lage sind, auch trotz ungenauer Eingangsdaten stabil und zuverlässig zu funktionieren, was in sicherheitskritischen Anwendungen unverzichtbar ist. Die Funktionsweise von LLM-Agenten weist strukturelle Parallelen zu diesen klassischen Systemen auf, unterscheidet sich aber auch gravierend. Während Robotik und numerische Systeme mit klar quantifizierbaren Fehlermaßen arbeiten, setzen LLMs auf semantische Verarbeitung natürlicher Sprache, dessen Fehler oft erst nach mehreren Verarbeitungsschritten in Erscheinung treten.
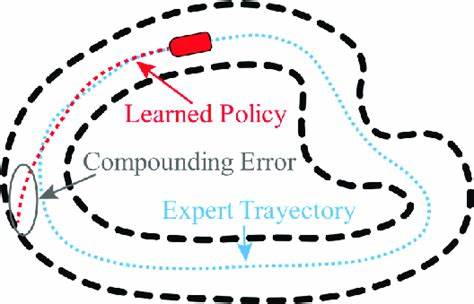
Ein falsch interpretierter Fakt oder ein halluzinierter Begriff wirkt zunächst genauso valide wie korrekte Informationen und führt somit zu einer latenten Fehlerrate, die sich unsichtbar ausbreitet. Dies macht den Umgang mit Fehlern in Großsprachmodellen besonders herausfordernd, da die fehlerhafte Semantik erst im Zuge komplexer, oft mehrstufiger Schlussfolgerungen klar wird. Trotz dieser Parallelen und den jahrzehntelangen Erkenntnissen aus Informatik und Robotik scheint die Informatik- und KI-Gemeinschaft bisher nur sehr zögerlich auf die Problematik der kumulativen Fehler in LLM-Agenten zu reagieren. Die verbreitete Hoffnung auf emergente Selbstkorrekturfähigkeiten oder robuste semantische Verarbeitung führt zwar zu vereinzelten Erfolgen, diese sind jedoch meistens inkonsistent und nicht verlässlich reproduzierbar. Studien zeigen vielmehr, dass die Genauigkeit bei mehrstufigen Aufgaben exponentiell abnimmt – bis hin zu katastrophalem Versagen bei komplexen Abläufen, die mehr als nur wenige Verarbeitungsschritte umfassen.
Erschwerend kommt hinzu, dass größere Modelle zwar tendenziell geringere Einzelschritt-Fehlerraten aufweisen, systemische Defizite wie Halluzinationen und inkohärente Argumentationen selbst in sehr großen Sprachmodellen bestehen bleiben. Selbst Optimierungen wie Chain-of-Thought-Prompting, die kontextbasiertes Denken simulieren sollen, zeigen nur begrenzte Erfolge bei der Vermeidung von Fehlerfortpflanzung und sind stark abhängig von perfektem Kontextzugriff. Die Folgen dieser Erkenntnisse sind weitreichend. In hochsensiblen Anwendungsfeldern wie Finanzanalyse, medizinischen Diagnosen, oder Infrastrukturmanagement können kumulative Fehler verheerende Auswirkungen haben. Während Fehler in der Robotik zu sichtbaren Fehlfunktionen führen und sofortige Korrektur erfordern, verlaufen Fehler in LLM-Anwendungen oft unsichtbar und werden als bloße „Randfälle“ abgetan.
Das ist eine gefährliche Perspektive, die in Zukunft immer weniger tragbar sein wird, wenn KI-Systeme immer stärker in kritische Entscheidungen eingebunden werden. Die Forschung der letzten Jahre bestätigt die klassischen Theorien der Fehlervermehrung auch im Kontext von LLM-Agenten. Die Genauigkeit nimmt mit jeder zusätzlichen Verarbeitungsebene ab, was sich mathematisch durch exponentielle oder potenzgesetzliche Zusammenhänge beschreiben lässt. Betrachtungen aus der Informationstheorie legen nahe, dass der semantische Informationsfluss durch die Agenten als noisy channel betrachtet werden kann, der ohne Fehlerkorrektur inhaltlich verfälscht wird. Die Erkenntnisse aus der Regelungstechnik beschreiben offene Schleifensysteme – wie gegenwärtige LLM-Workflows – als inhärent instabil bei langen Verarbeitungsketten, während geschlossene Rückkopplungsschleifen wesentliche Stabilität bringen könnten.
Vor diesem Hintergrund ist deutlich, wie wichtig es ist, Maßnahmen zu ergreifen, die Fehlererkennung und -korrektur in LLM-Agenten explizit implementieren. Eine Kombination aus semantischer Sensitivitätsanalyse, also der Messung, wie anfällig eine Verarbeitung für Eingabefehler ist, mit strukturierten Feedbackmechanismen könnte das Vertrauen in komplexe KI-Systeme signifikant verbessern. Ansätze aus der Robotik, wie Redundanz durch multiple Verarbeitungspfade und probabilistische Fehlerabschätzung, lassen sich adaptieren und bieten praktisch umsetzbare Lösungen. Darüber hinaus könnten semantische Fehlerkorrekturverfahren in Anlehnung an klassische Fehlerkorrekturcodes entwickelt werden, die eine verlässliche Überprüfung von Ergebnissen ermöglichen. Solche Mechanismen sollten darauf abzielen, die Unsicherheiten und potenziellen Fehlerquellen fortlaufend zu quantifizieren und bei Überschreiten kritischer Werte handlungsfähig zu machen – beispielsweise durch eine automatische Eskalation an menschliche Entscheider oder auf spezialisierte Subsysteme.
Die technologische Herausforderung besteht darin, diese Konzepte in die gegenwärtigen Architekturkonzepte der LLM-Agenten zu integrieren, ohne deren Effizienz zu beeinträchtigen. Gleichzeitig braucht es neue Forschungsschwerpunkte, die weit über die reine Optimierung der Modellgröße hinausgehen und die Verlässlichkeit und Robustheit in den Mittelpunkt stellen. Gerade angesichts der zunehmenden Integration von KI in lebenswichtige Systeme und Prozesse sind solche Strategien essenziell, um zukünftige, womöglich irreversible Schäden zu verhindern. Die Ursachen für das bislang geringe Bewusstsein über diese Problematik sind vielfältig. Historisch gesehen dominierten in der KI-Community eher das Streben nach Leistungssteigerung und beeindruckenden Demos, weniger ein Fokus auf Langzeitstabilität oder Fehleranalyse.
Wirtschaftliche Rahmenbedingungen begünstigen schnelle Implementierungen statt nachhaltige Systemzuverlässigkeit. Zudem erzeugt die Komplexität moderner Sprachmodelle eine Illusion von Intelligenz und Unfehlbarkeit, sodass die tatsächliche Fehleranfälligkeit unterschätzt wird. Ferner spielt eine gewisse Isolation innerhalb der Wissenschaftsdisziplinen eine Rolle: Während Informatik, Robotik und künstliche Intelligenz gemeinsame mathematische Grundlagen teilen, existiert eine kulturelle Distanz, die den Wissenstransfer hin zu praktischen Lösungen erschwert. Diese Barrieren gilt es zu überwinden, damit bewährte Verfahren aus der Physik-basierten Robotik und der numerischen Analyse auch in die domänenübergreifende KI-Entwicklung einfließen können. Zusammenfassend lässt sich festhalten, dass kumulative Fehler ein zentrales Hindernis für die Zuverlässigkeit moderner LLM-Agenten darstellen.
Die etablierten Theorien der Fehlerfortpflanzung eröffnen nicht nur Verständnis, sondern vor allem konkrete Handlungsperspektiven. Eine Weiterentwicklung von KI-Systemen im Einklang mit den Prinzipien der Fehlerkorrektur und Unsicherheitsquantifizierung ist unabdingbar, um aus technologischen Novitäten robuste Werkzeuge für den Alltag zu schaffen. Nur durch eine konsequente Integration von Rückkopplungsmechanismen, probabilistischen Modellen und Redundanz können LLM-Agenten über längere, komplexe Aufgaben hinweg stabil und vertrauenswürdig operieren. Die Alternative bedroht nicht nur die praktische Anwendbarkeit, sondern birgt auch erhebliche ethische und gesellschaftliche Risiken. Während die technologische Entwicklung rasant voranschreitet, steht die AI-Community an einem Wendepunkt.