In der heutigen datengetriebenen Welt ist eine effiziente, skalierbare und zuverlässige Event-Streaming-Plattform unerlässlich. Apache Kafka hat sich als Industriestandard etabliert, wenn es um Messaging und Event-Streaming geht. Dennoch suchen viele Unternehmen nach Alternativen, die besser zu ihren speziellen Anforderungen und technischen Umgebungen passen. Hier tritt Tansu auf den Plan – eine innovative, Apache Kafka API kompatible Broker-Alternative, die PostgreSQL und S3 als primäre Speicher-Engines unterstützt und dabei moderne Data-Lake-Technologien integriert. Tansu ist kein gewöhnliches Messaging-System.
Es erlaubt eine nahtlose Übernahme bestehender Kafka-Infrastrukturen, indem es dieselbe API verwendet und dadurch die Migration erheblich vereinfacht. Das System unterstützt schema-gestützte Topics, die mit JSON Schema, Apache Avro oder Protocol Buffers validiert werden. Diese Funktionen ermöglichen nicht nur die Sicherstellung der Datenqualität, sondern auch die Integration mit modernen Data-Lake-Standards wie Apache Iceberg und Delta Lake. Dadurch wird die Speicherung der Topic-Daten in Form von Apache Parquet-Dateien möglich, was eine optimierte Analyse und Abfrage großer Datenmengen erlaubt. Die Auswahl an Speicher-Backends macht Tansu besonders flexibel.
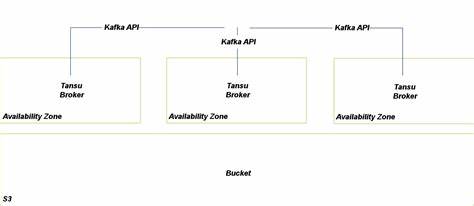
Zum einen kann PostgreSQL als robustes relationales System genutzt werden, das unter anderem durch kontinuierliches Streaming von Transaktionslogs eine sehr hohe Datenhaltbarkeit sicherstellt. Zum anderen bietet die Integration mit S3 (oder kompatiblen Objektspeichern) eine nahezu grenzenlose Skalierbarkeit und extrem hohe Verfügbarkeit durch zwölf Neunen (99,999999999%) Zuverlässigkeit. Für temporäre oder Entwicklungsumgebungen steht auch ein speicherbasierter Modus zur Verfügung, der ohne persistente Speicherung arbeitet. Ein großer Vorteil von Tansu liegt in seiner Einfachheit der Bereitstellung. Es wird als eine einzelne statisch gelinkte Binärdatei ausgeliefert, die verschiedene Subkommandos vereint.
Neben dem Kernbroker gehört dazu ein Command-Line-Interface zum Erstellen und Verwalten von Topics, ein weiteres zum Produzieren und Konsumieren von Nachrichten, sowie ein Proxy, der ebenfalls Kafka-API kompatibel ist. Diese Tools ermöglichen es Entwicklern und Betreibern, Tansu einfach in bestehende Umgebungen einzubinden und schnell produktiv zu nutzen. Die schema-basierte Validierung der Nachrichten stellt sicher, dass Event-Daten strukturell konsistent sind. Dadurch reduzieren sich Fehlerquellen dramatisch, die beispielsweise durch fehlerhafte oder inkonsistente Payloads entstehen können. Bei Verwendung entsprechender Schemas wird jede Nachricht beim Eintreffen auf Gültigkeit geprüft.
Ungültige Nachrichten werden konsequent abgelehnt, was Unternehmen mehr Datensicherheit und einen hohen Grad an Datenintegrität vermittelt. Darüber hinaus ist Tansu hervorragend geeignet, um Big-Data-Analysen zu unterstützen. Dank der schreibenden Integration mit Apache Iceberg und Delta Lake können Nachrichtenströme direkt in tabellarisch strukturierte Data-Lake-Formate konvertiert werden. Dies eröffnet vielfältige Möglichkeiten für Analytics, Machine Learning und Reporting mit modernen Data-Frameworks wie Apache Spark oder PyIceberg. Die nahtlose Kompatibilität mit PostgreSQL als Speicher-Engine bietet ebenfalls eine Menge Vorteile für Unternehmen, die bereits auf relationale Datenbanken setzen.
Die Verwendung von PostgreSQL als Backend ermöglicht flexible Datenhaltung, unterstützt Transaktionen und bringt die Stabilität einer bewährten Datenbankplattform mit. In Verbindung mit der Kafka API Kompatibilität ist Tansu somit eine Brücke zwischen traditionellen Datenbanksystemen und modernen Event-Streaming-Architekturen. S3 als Speicherengine ist besonders attraktiv für Cloud-native Umgebungen und Microservice-Architekturen. Die Speicherung von Nachrichten und Metadaten in S3-Buckets erlaubt eine hochverfügbare, kosteneffiziente und skalierbare Infrastruktur. Für Unternehmen mit großen Datenvolumen oder global verteilten Anwendungen stellt dies eine äußerst leistungsfähige Lösung dar.
Dabei profitiert Tansu von den zahlreichen Sicherheits- und Lifecycle-Management-Funktionen von S3. Ein weiterer Aspekt, der Tansu auszeichnet, ist die umfassende Unterstützung gängiger Schemaformate. Ob JSON Schema, Avro oder Protocol Buffers, Anwender können die Datenformate wählen, die am besten zu ihren Use Cases passen. Dieses Maß an Flexibilität erleichtert die Integration in bestehende Systeme, die unterschiedliche Anforderungen an Datenstruktur und Serialisierung stellen. Darüber hinaus ist Tansu als Open-Source-Projekt in Rust geschrieben, was nicht nur für hohe Performance sorgt, sondern auch für eine sichere Speicherverwaltung und effiziente Parallelisierung.
Die Entwicklungscommunity ist aktiv, die Software lizenzfrei unter der Apache 2.0 Lizenz nutzbar, was Unternehmen die Verwendung ohne rechtliche Hürden ermöglicht. Die Bedienung von Tansu ist benutzerfreundlich und orientiert sich an den bekannten Befehlen von Apache Kafka. Entwickler können Topics erstellen und löschen, Nachrichten produzieren und konsumieren, ohne komplett neue Werkzeuge erlernen zu müssen. Die Kompatibilität mit den standardmäßigen Kafka-CLI Tools und Client-Bibliotheken wie librdkafka garantiert eine reibungslose Nutzung im Alltag.
Auch im Bereich Monitoring zeigt Tansu Stärken. Die Integration von Prometheus zur Metrikerfassung erlaubt es DevOps-Teams, Broker-Leistung und Ressourcennutzung effizient zu überwachen und darauf basierende Automatisierungen und Alarme zu implementieren. Dies trägt entscheidend zur Stabilität und Skalierbarkeit in produktiven Umgebungen bei. Die Kombination aus Kafka Kompatibilität, flexiblen Speicheroptionen und moderner Schema-Validierung macht Tansu zu einem zukunftsträchtigen Tool für Unternehmen, die entweder Kafka-Lösungen ablösen oder alternative Architekturen für Streaming-Daten in Betracht ziehen. Zusätzlich zur Cloud- und On-Premise-Tauglichkeit ist die Unterstützung von Data-Lake-Technologien ein bedeutendes Plus, das den Datenfluss vom Event-Bus bis zur Datenanalyse effizient unterstützt.
Tansu lässt sich über Docker Compose einfach aufsetzen, wodurch eine unkomplizierte Entwicklung und das Testen in unterschiedlichen Konfigurationen garantiert ist. Zudem sind umfangreiche Beispiele und eine fundierte Dokumentation vorhanden, die den Einstieg erleichtern und praxisnahe Anwendungsszenarien bieten. Insgesamt zeigt sich Tansu als durchdachte, leistungsfähige und flexible Plattform, die die Vorteile von Apache Kafka mit modernen Speicherlösungen und Data-Lake-Standards vereint. Für Unternehmen, die Datenströme konsistent und haltbar speichern möchten, dabei aber modernen Cloud- und Analytics-Anforderungen gerecht werden wollen, stellt Tansu eine äußerst attraktive Alternative dar. Technologische Trends und die steigenden Anforderungen an Datenarchitekturen fordern immer wieder neue Lösungen, die flexibel auf sich verändernde Rahmenbedingungen reagieren können.
Tansu ist ein Beispiel für die Evolution traditioneller Messaging-Systeme hin zu hybriden, integrativen Datenplattformen, die sowohl Transaktionssicherheit, Skalierbarkeit als auch Data-Lake-Kompatibilität bieten. Abschließend bleibt festzuhalten, dass Tansu durch seinen Open-Source-Charakter und die aktive Entwicklung eine wichtige Ergänzung im Ecosystem moderner Dateninfrastruktur ist. Ob als leichter Kafka-Ersatz in Entwicklungsumgebungen, als skalierbares System für produktive Streaming-Anwendungen oder als Bindeglied zwischen relationalen Datenbanken und Big-Data-Frameworks – Tansu überzeugt durch seine vielseitigen Möglichkeiten und technische Integrationsstärke.