In der heutigen Welt der datengetriebenen Geschäftsmodelle zählt vor allem Geschwindigkeit: Wie schnell können Daten verarbeitet und analysiert werden? Für Unternehmen, die auf Cloud-Datenbanken wie ClickHouse setzen, ist die Antwort darauf entscheidend. Doch während object storage-Dienste wie Amazon S3, Google Cloud Storage oder Azure Blob Storage enorme Skalierbarkeit bieten, stellen ihre hohen Latenzen und die Trennung von Speicher und Rechenleistung eine Herausforderung dar. Hier setzt die Entwicklung eines verteilten Caches speziell für S3 an, der den Zugriff auf „heiße“ Daten erheblich beschleunigt und damit die Leistungsfähigkeit moderner Cloud-Datenbanken revolutioniert. Die Grundproblematik besteht darin, dass Objektspeicher zwar günstig und dauerhaft verfügbar sind, aber mit Latenzen im Bereich von Hunderten Millisekunden aufwarten. Beim analytischen Arbeiten bedeutet das Verzögerungen, die sich selbst durch hohe parallele Lesefrequenz nicht ausgleichen lassen.
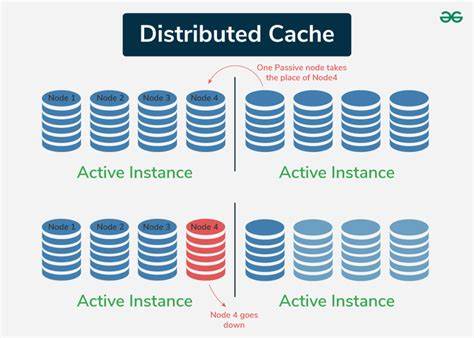
Insbesondere bei wiederholten oder verschachtelten Abfragen entstehen dadurch längere Wartezeiten. Kunden von ClickHouse Cloud kennen diese Herausforderung: Compute-Knoten greifen auf gemeinsam genutzte Daten im Objekt-Storage zu, verfügen jedoch lediglich über lokale Caches, die nur isoliert arbeiten. Diese Inseln der Zwischenspeicherung bremsen die Skalierung aus und führen immer wieder zu Kaltstarts, weil der Cache beim Hochskalieren oder bei neuen Knoten komplett neu geladen werden muss. Die Antwort auf diese Problematik ist der verteilte Cache: eine gemeinsam genutzte Zwischenschicht, die es allen Compute-Knoten ermöglicht, schnell und ohne erneuten Zugriff auf die langsame Object-Storage-Schicht auf heiße Daten zuzugreifen. Dabei fungiert der verteilte Cache als Netzwerkdienst, der Daten intelligent verwaltet und unter den Knoten verteilt.
Er agiert als Brücke zwischen der Hochgeschwindigkeit des Arbeitsspeichers auf den Rechnern und der kosteneffizienten, aber trägen Objektablage. Historisch betrachtet hat das Caching in ClickHouse mehrere Entwicklungsphasen durchlaufen. Zunächst setzten die Anwender auf das Betriebssystem-Page-Cache in Kombination mit lokalem SSD-Speicher, was sehr schnell, aber an den jeweiligen Server gebunden war. Der Umstieg auf die Cloud machte dieses Modell unzureichend, da Speicherkapazität und Rechenleistung voneinander entkoppelt wurden. Um dem entgegenzuwirken, entstand die Idee eines lokalen Dateisystems-Caches auf den Cloud-Compute-Knoten, der als Zwischenspeicher für S3 fungiert.
Zwar erhöhte dies die Performance spürbar, doch blieb das Problem isolierter Caches bestehen: Knoten profitieren nicht voneinander, und Skalierung führte zu Kaltstarts. Der verteilte Cache als dritte Stufe ist eine fundamentale Neuerung: Er integriert eine Netzwerkebene, die hochperformant zwischen gemeinsamer Objektablage und den Rechenknoten vermittelt. Dank moderner Netzwerke mit Latenzen im Mikrosekundenbereich und Durchsatzraten von mehreren Gigabyte pro Sekunde ermöglicht dieser Dienst eine signifikante Reduzierung der Zugriffslatenz auf Daten. Durch konsistente Verteilung der Datenblöcke auf spezielle Cache-Knoten und parallele Abrufe maximiert das System die Bandbreite umfassend. Dadurch erreichen mehrgängige Abfragen eine deutliche Beschleunigung, die sogar die Performance von lokal-Datenträgern im traditionellen Shared-Nothing-Setup übertrifft.
Essentiell dabei ist das Konzept des „hot table data“ – also die Teilmengen der Tabellendaten, die aufgrund häufigerer Anfragen besonders relevant sind. Diese Daten werden beim Laden nicht nur lokal zwischengespeichert, sondern über den verteilten Cache für alle Compute-Knoten nutzbar gemacht. Dank dieser geteilten Cacheschicht profitieren neue Knoten beim Hochskalieren sofort von den bereits vorhandenen Zwischenspeichern. Die Rechenknoten selbst werden dadurch entlastet, da redundante Datenzugriffe auf Object Storage entfallen. Technisch kombiniert das System mehrere Caching-Layer.
Neben dem verteilten Cache existiert eine Userspace-Seitencache in den Compute-Knoten, die im Arbeitsspeicher gehalten wird und die Zugriffe auf den verteilten Cache weiter beschleunigt. Dadurch entsteht eine mehrstufige Cache-Hierarchie: vom permanenten, aber langsamen Objekt-Speicher über den SSD-basierten verteilten Cache bis zum RAM-basierten Userspace-Cache eines jeden Knotens. Dieses Zusammenspiel reduziert die Latenz auf bis zu mehreren Mikrosekunden und ermöglicht Datendurchsätze, die mit traditionellen SSD-Setups nicht mehr mithalten können. Messungen zeigen beeindruckende Ergebnisse: Auf großen Datensätzen, wie zum Beispiel der Amazon Reviews Tabelle mit einem Volumen von über 30 Gigabyte komprimierter Daten, erreichen Abfragen dank des verteilten Caches bis zu vierfach schnellere Laufzeiten bei Volltabellen-Scans im Vergleich zu einem klassischen SSD-Setup. Noch beeindruckender ist die Skalierung der Latenzzeiten bei kleinen, scattered Reads: Trotz komplett fehlendem lokalen Datenspeicher erreichen neu gestartete Knoten annähernd SSD-Performance bei der Datenabfrage, da sie auf den Hot-Cache im Netzwerk zurückgreifen können.
Diese Kombination aus Performance und Skalierbarkeit ist speziell für Cloud-Analytik entscheidend. Die Architektur des verteilten Caches ist zudem auf Multi-Tenancy ausgelegt und arbeitet pro Availability Zone, um Netzwerkverzögerungen und Kosten durch Cross-Zone-Traffic zu minimieren. Sicherheit wird durch gezielte Authentifizierung und Verschlüsselung gewährleistet, sodass die Isolation zwischen unterschiedlichen ClickHouse-Cloud-Instanzen erhalten bleibt. Dies eröffnet einen Einsatzbereich, bei dem mehrere Kunden parallel profitieren können, ohne dass sich die Caches gegenseitig beeinflussen. Nicht nur der reine Datenzugriff profitiert von der neuen Cache-Schicht.
Auch das Zwischenspeichern von Metadaten, Index-Dateien und temporären Daten wie Sortier- oder Joins-Teilen erfolgt über den verteilten Cache. Damit entpuppt sich der Dienst als zentrale Komponente, die den gesamten I/O-Pfad optimiert und Fehlerquellen sowie Redundanzen minimiert. Diese Innovation ist ein großer Schritt hin zu modernen Cloud-Datenplattformen, die sich nahtlos elastisch skalieren lassen, ohne Kompromisse bei der Performance einzugehen. Während frühere Systeme oft kostspielige Neukonfigurationen oder Datenreshardings erforderten, läuft das Skalieren mit dem verteilten Cache dynamisch und unterbrechungsfrei ab. Das ermöglicht nicht nur eine bessere Nutzung der vorhandenen Ressourcen, sondern senkt auch die Betriebskosten und vereinfacht das Management.
Ausblickend wird die Technologie weiterentwickelt und adaptiert, um neben S3 auch andere Objektspeicher wie Azure Blob Storage zu unterstützen. Das Ziel ist es, eine universelle Lösung für alle bedeutenden Cloud-Anbieter anzubieten und damit eine noch größere Bandbreite an Kunden und Anwendungsfällen zu bedienen. Die private Preview des verteilten Caches bietet Interessierten die Möglichkeit, frühzeitig von den Vorteilen zu profitieren und Feedback für die Weiterentwicklung beizusteuern. Die Einführung des verteilten Caches für S3 in ClickHouse Cloud ist ein Meilenstein für die Cloud-Analytik. Sie ebnet den Weg für extrem schnelle, flexible und skalierbare Datenverarbeitung ohne Abstriche bei der Latenz.
Das Ergebnis sind leistungsfähige Systeme, die den Anforderungen moderner Unternehmen gerecht werden und zugleich die Grenzen traditioneller Caching-Methoden sprengen. Damit ist der Traum einer skalierbaren, stets heißen Datenhaltung in der Cloud endlich Realität geworden – und ein entscheidender Mehrwert für alle, die auf schnelle und effiziente Datenanalyse angewiesen sind.