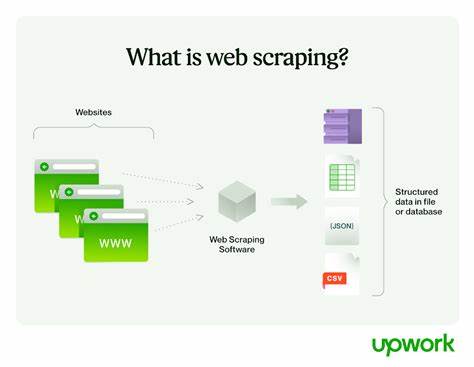
Web Scraping ist ein viel diskutiertes Thema, besonders wenn es darum geht, diese Technik im produktiven Umfeld zuverlässig einzusetzen. Während Hobbyisten und Entwickler meist mit kleinen Projekten oder persönlichen Skripten experimentieren, steht in der Industrie oftmals die Frage im Vordergrund, wie man Scraping stabil, skalierbar und rechtlich unbedenklich betreiben kann. Der Ursprung vieler Scraping-Ideen kommt aus dem Bedürfnis, automatisch Daten von Webseiten zu sammeln, die nicht über eine offizielle API zugänglich sind. Dabei reicht die Bandbreite an Anwendungen von einfachen Datenabfragen wie dem Überprüfen des eigenen Bankkontostands oder der Suche nach Interview-Slots über komplexe Informationsgewinnung für Marktanalysen und Immobilienbewertungen. Trotz der scheinbaren Einfachheit ist Web Scraping im produktiven Einsatz mit erheblichen Herausforderungen verbunden.
Die Hauptschwierigkeit liegt in der oft hohen Brüchigkeit der Scraper, die bei Änderungen der Zielwebseiten schnell nicht mehr funktionieren. Webseiten können ihr Layout, ihre Struktur oder sogar die Art der Datenbereitstellung jederzeit ändern, was Scraper ohne Wartung lahmlegt. Diese Instabilität verlangt von Entwicklern kontinuierliche Anpassungen und Monitoring-Mechanismen, damit die automatisierte Datenerfassung zuverlässig bleibt. Ein weiterer Aspekt ist die rechtliche Grauzone, in der sich viele Scraping-Initiativen bewegen. Zwar können öffentlich zugängliche Daten oft genutzt werden, jedoch variieren die Nutzungsbedingungen, und Verstöße gegen die Terms of Service drohen mit Sperrungen oder rechtlichen Konsequenzen.
Einige Dienste setzen auch technische Gegenmaßnahmen wie IP-Blocking, Captchas oder dynamische HTML-Generierung ein, um automatisiertes Scraping zu erschweren oder zu verhindern. In der Praxis helfen verschiedene Strategien, die Stabilität von Web-Scrapern zu erhöhen. Beispielsweise werden moderne Scraper oft modular und wartbar gestaltet, sodass Änderungen an einzelnen Komponenten leichter umzusetzen sind. Der Einsatz von robusteren Parsing-Techniken, die nicht nur auf statisches HTML basieren, sondern auch JavaScript-renderte Seiten durch Headless-Browser oder APIs simulieren, verbessert die Zuverlässigkeit erheblich. Ergänzend kommen Fehlererkennungs- und Wiederherstellungsmechanismen zum Einsatz, die den Betrieb nach temporären Störungen automatisch wieder aufnehmen.
Automatisiertes Testen vor dem Deployment eines Scrapers kann außerdem mögliche Probleme frühzeitig aufdecken. Ein Trend, der sich auch im Produktionsbetrieb durchsetzt, ist die Nutzung von Cloud-Diensten und orchestrierten Workflows, die eine flexible Skalierung erlauben und gleichzeitig ressourcenschonend arbeiten. Dabei kann der Scraper in bestimmte Zeitfenster eingepasst werden oder dynamisch auf die Netzwerklast reagieren. Ein oft unterschätzter Vorteil ist die Integration von Datenqualitätssicherungsprozessen, damit die gewonnenen Daten nicht nur vollständig, sondern auch korrekt und einheitlich vorliegen. Branchenübergreifend finden Web-Scraper vielfache Verwendung.
Im Immobiliensektor werden sie eingesetzt, um Marktpreise, Bauvorhaben, Zonenänderungen oder Steuerdaten aus öffentlich zugänglichen Quellen zu erfassen. Verkaufs- und Marketingabteilungen nutzen Scraping zur Wettbewerbsbeobachtung oder zur Analyse von Kundenrezensionen. Auch im Verkehrs- und Logistikbereich helfen automatisierte Scraper dabei, aktuelle Informationen zu Staus, Wetter oder Baustellen einzufangen und in eigene Systeme einzuspeisen. Einige innovative Anwendungsideen setzen Scraping sogar in Kombination mit anderen Technologien ein, etwa bei der Steuerung von 3D-Druckprozessen oder zur Entwicklung fortschrittlicher biomechanischer Materialien, die sich an der Struktur von Spinnennetzen orientieren. Dabei steht das Wort „Scraping“ hier sinnbildlich für die gezielte, strukturierte Abtragung oder Nachbildung von Materialien, was zeigt, wie vielseitig das Konzept im weitesten Sinne interpretiert werden kann.
Für viele Unternehmen stellt Excel eine zugängliche Möglichkeit dar, einfache Datenabfragen durch Scraping zu realisieren. Dabei können sogenannte Web-Abfragen genutzt werden, mit denen Daten direkt aus Webseiten in Tabellen importiert werden. Diese Methode eignet sich besonders für kleinere Anwendungsfälle oder als Einstieg, wenngleich komplexere Operationen und Skalierung dadurch limitiert sind. Python ist hingegen eines der bevorzugten Werkzeuge für Softwareentwickler im Web Scraping. Mit Bibliotheken wie BeautifulSoup, Scrapy oder Selenium lassen sich flexible und leistungsfähige Scraper entwickeln, die je nach Anforderung auch komplexe Interaktionen mit Websites ermöglichen.
Python bietet zudem eine breite Community und viele Ressourcen zur Lösung häufig auftretender Probleme. Die Erzeugung von „untyped“ Formaten oder das Arbeiten mit delimited files kann je nach Use Case praktisch sein, birgt aber teilweise Herausforderungen bei der Datenverarbeitung oder -integration. Durch den Einsatz von Datenbanken oder spezialisierten Reporting-Tools wird häufig eine bessere Qualität und Nutzbarkeit der gescrapten Daten erreicht. Angesichts der Fragilität von Scraping-Lösungen im Produktivbetrieb machen es sich viele Unternehmen zur Regel, ihr Vorgehen in puncto Monitoring, Fehlerbehandlung und regelmäßige Aktualisierung automatisierter Sammler kontinuierlich zu optimieren. Es ist ratsam, den Scraping-Prozess nicht als Einmalprojekt zu betrachten, sondern als dauerhaft zu wartenden Bestandteil der Dateninfrastruktur zu verstehen.
Nur so lässt sich der Nutzen langfristig sichern. Außerdem gewinnt die Zusammenarbeit mit Rechtsexperten zunehmend an Bedeutung, um sicherzustellen, dass Scraping-Maßnahmen sowohl den gesetzlichen Vorgaben als auch den ethischen Standards entsprechen. Abschließend bleibt festzuhalten, dass Web Scraping im produktiven Einsatz zwar seine Herausforderungen hat, aber mit einer durchdachten Architektur und klaren Prozessen ein wertvolles Werkzeug zur Informationsgewinnung sein kann. Es eröffnet Unternehmen die Möglichkeit, Daten in Echtzeit zu analysieren, Marktentwicklungen frühzeitig zu erkennen und Wettbewerbsvorteile zu generieren. Innovative Ansätze und technische Weiterentwicklungen tragen dazu bei, die Zuverlässigkeit der Scraper zu steigern und gleichzeitig die Einhaltung regulatorischer Rahmenbedingungen zu gewährleisten.
Die Zukunft des Web Scraping sieht vielversprechend aus, gerade wenn man es als Teil eines ganzheitlichen, datengetriebenen Ansatzes begreift, der technische, rechtliche und organisatorische Aspekte gleichermaßen berücksichtigt.