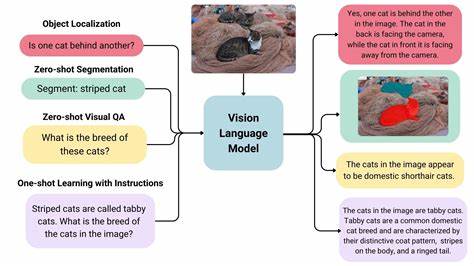
Vision Language Modelle (VLMs) haben sich in den letzten Jahren zu einem der spannendsten und innovativsten Gebiete der künstlichen Intelligenz entwickelt. Die Kombination aus visuellen und sprachlichen Daten ermöglicht es diesen Modellen, komplexe Aufgaben zu bewältigen, die zuvor nur durch menschliches Verständnis möglich waren. Von der Bilderkennung über Textgenerierung bis hin zur Interaktion mit der realen Welt setzen Vision Language Modelle neue Maßstäbe in Effizienz, Vielseitigkeit und Intelligenz. Ein entscheidender Wandel in diesem Bereich ist die Entwicklung sogenannter Any-to-Any Modelle, die Eingabedaten beliebiger Modalitäten wie Bild, Text oder Audio aufnehmen und in ebenso vielfältigen Formaten ausgeben können. Diese Modelle arbeiten durch die Schaffung eines gemeinsamen Repräsentationsraums, in dem unterschiedliche Modalitäten harmonisch zusammengeführt werden.
Die Architektur umfasst mehrere Enkoder für die jeweiligen Modalitäten und Decoder, die das kombinierte Wissen in die gewünschte Form bringen. Ein bekanntes Beispiel ist das Modell Qwen 2.5 Omni mit seiner innovativen Thinker-Talker-Architektur, bei der der „Thinker“ die Textgenerierung übernimmt und der „Talker“ natürliche Sprachantworten in Echtzeit liefert. Neben der Erweiterung der Modalitäten liegt ein Schwerpunkt auf der Fähigkeit zu komplexem logischem Denken, auch bekannt als Reasoning. Modelle wie Kimi-VL-A3B-Thinking zeigen, dass Vision Language Modelle nicht nur visuelle Informationen verstehen, sondern auch lange und komplexe Entscheidungsprozesse meistern können.
Diese Multi-Experten-Modelle (MoE) verwenden spezialisierte Submodelle, die je nach Aufgabe selektiv aktiviert werden, was Leistung und Effizienz erheblich steigert. Die Kombination aus tiefgreifendem Verständnis und Agentenfähigkeiten ermöglicht Anwendungen, die weit über reine Bildbeschreibung hinausgehen und eine Interaktion mit komplexen Umgebungen erlauben. Ein weiterer Trend ist die Entwicklung kleiner, dennoch äußerst leistungsfähiger Modelle, die auf durchschnittlicher Hardware laufen können. SmolVLM und Modelle wie gemma3-4b-it von Google DeepMind demonstrieren eindrucksvoll, wie sich Größe und Komplexität reduzieren lassen, ohne signifikanten Verlust an Leistungsfähigkeit. Dieser Paradigmenwechsel eröffnet die Tür für lokale Ausführungen, schnellere Inferenzzeiten und datenschutzfreundliche Anwendungen, die traditionell durch die Anforderungen großer Modelle limitiert waren.
Die Vision Language Action Modelle (VLA) haben darüber hinaus eine spannende Nische in der Robotik besetzt. Sie erweitern Vision Language Modelle durch die Fähigkeit, nicht nur zu verstehen, sondern auch physische Aktionen auf Basis von Bild- und Textinformationen auszuführen. Projekte wie π0 und π0-FAST zeigen die praktische Umsetzbarkeit dieser Technologie in realen Robotikanwendungen, von Haushaltsaufgaben bis zur Interaktion mit vielfältigen Objekten. NVIDIA’s GR00T N1 ist ein exemplarisches Beispiel für einen allumfassenden Ansatz, bei dem ein Modell durch visuelle Wahrnehmung und Sprachverständnis gleichzeitig Steuerbefehle in komplexen, humanoiden Robotern generiert. Neben den Modellen selbst rücken spezialisierte Fähigkeiten immer mehr in den Fokus.
Vision Language Modelle können inzwischen weit mehr als einfache Erkennung oder Klassifikation. Sie bewältigen auch Objekterkennung, Segmentierung und die Zählung von Instanzen selbst in anspruchsvollen Szenarien. Fortschritte im Bereich der Kodierung von Segmentierungsinformationen durch Variational Autoencoder eröffnen neue Möglichkeiten, visuelle Daten detailliert und präzise auszuwerten und in Textform darzustellen. Diese Fähigkeiten sind besonders wertvoll in Bereichen wie medizinischer Bildgebung, Forschung und automatisierter Analyse komplexer Dokumente. Sicherheit und Ethik sind ebenfalls zentrale Themen bei der Entwicklung von VLMs.
Multimodale Safety Modelle wie ShieldGemma 2 von Google oder Meta’s Llama Guard 4 arbeiten als Filter und Schutzschicht, um sicherzustellen, dass Inhalte vor und nach der Verarbeitung keine schädlichen, unangemessenen oder manipulierten Informationen enthalten. Die Integration solcher Sicherheitssysteme ist essenziell, um die Zuverlässigkeit und gesellschaftliche Akzeptanz von KI-Anwendungen zu gewährleisten, gerade in sensiblen Einsatzgebieten. Ein innovativer Bereich stellt Multimodale Retrieval Augmented Generation (RAG) dar. Durch die Kombination von visueller Dokumentenerfassung und sprachlicher Abfrage bieten multimodale RAG-Modelle effiziente Lösungen für die Suche und Interpretation komplexer Dokumente wie PDFs. Hier kommen unterschiedliche Archivierungs- und Rankingtechniken zum Einsatz, die nicht mehr auf heuristischen Layoutanalysen basieren, sondern visuelle und textuelle Relevanzen direkt miteinander verrechnen, was die Genauigkeit und Nutzerfreundlichkeit erheblich erhöht.
Die Integration von VLMs in agentische Systeme ermöglicht ein neues Level von Automatisierung und Interaktivität. Smolagents etwa stellen eine leichtgewichtige Plattform bereit, die auf Basis von Vision Language Modellen komplexe Aktionen über grafische Benutzeroberflächen steuern kann. Solche Systeme sind in der Lage, in Echtzeit auf visuelle Informationen zu reagieren, einzuordnen und darauf aufbauend strategische Vorgehensweisen umzusetzen. Die Anwendungsspektren reichen dabei von der Dokumentenbeschreibung über die Webautomatisierung bis hin zur dynamischen Steuerung von Geräten. Nicht zu vergessen sind Video Language Modelle, die durch die Analyse zeitlich aufeinanderfolgender Bilder zusätzlich die Dimension der Zeit erschließen.
Mit Methoden zur Auswahl relevanter Video-Frames und der Verarbeitung großer Kontextfenster können Modelle wie LongVU oder Gemma 3 komplexe Geschehnisse erfassen und interpretieren. Dies ist beispielsweise für Überwachungssysteme, Sportanalysen oder interaktive Medien von großer Bedeutung. Ein weiterer Meilenstein sind neue Feinabstimmungsmethoden wie die Präferenzoptimierung (Direct Preference Optimization, DPO) für VLMs, die ein differenziertes Training anhand von bevorzugten gegenüber abgelehnten Antworten ermöglichen. Hierdurch wird die Qualität der Antworten in Bezug auf menschliche Präferenzen und ethische Vorgaben verbessert. DPO trägt somit dazu bei, dass Vision Language Modelle nicht nur technisch leistungsfähig, sondern auch im Umgang mit Nutzern und Inhalten verantwortungsvoll agieren.
Zu den modernen Bewertungsansätzen zählen umfassende Benchmarks wie MMT-Bench und MMMU-Pro, die eine breit gefächerte, anspruchsvolle Evaluation der Modelle erlauben. Sie decken zahlreiche multimodale Aufgaben ab, von einfacher visueller Erkennung bis zu komplexen Planungsszenarien, und stellen so sicher, dass neue Modelle ganzheitlich geprüft und bewertet werden können. Solche Benchmarks sind essentiell, um den Fortschritt objektiv nachvollziehbar zu machen und zukünftige Forschungen gezielt zu steuern. Die jüngsten Modellhighlights wie Qwen2.5-VL oder Kimi-VL-Thinking belegen die rasante Entwicklung in dieser Domäne, indem sie vielseitige Fähigkeiten von Agentik über Multimodalität bis hin zu exzellenter Erkennung vereinen.
Kleinere Modelle wie SmolVLM2 bringen außerdem den Fortschritt auf Endgeräte und eröffnen so neue Einsatzmöglichkeiten fernab von großen Rechenzentren. Vision Language Modelle sind somit ein Schlüsselfaktor für das nächste Jahrzehnt der KI-Technologie. Sie verbinden visuelle Wahrnehmung mit sprachlicher Intelligenz und erweitern die Anwendungsszenarien künstlicher Intelligenz in vielfältiger Weise. Ob in Robotik, Medizintechnik, automatisierten Assistenzsystemen oder der Verarbeitung komplexer Dokumente – die Fortschritte bei VLMs machen zahlreiche neue Innovationen möglich. Die Entwicklung dieser Modelle bleibt dynamisch und vielversprechend.
Forschung und Praxis arbeiten Hand in Hand, um die Modelle noch besser, schneller und vielseitiger zu machen. Mit wachsender Zugänglichkeit und verbessertem Verständnis wächst auch die Erwartung, dass Vision Language Modelle künftig eine zentrale Rolle in unserem täglichen Leben spielen werden. Die Zukunft der intelligenten Systeme wird demnach nicht nur sprachlich, sondern auch visuell sprachfähig und handlungsorientiert sein – besser, schneller und stärker als je zuvor.