AMD ist heute vor allem für seine Infinity Fabric Interconnect-Technologie bekannt, die als Rückgrat für die Verbindung von CPU- und GPU-Komponenten in modernen Systemen dient. Doch bevor Infinity Fabric seinen Siegeszug antrat, schlug AMD mit der Trinity Accelerated Processing Unit (APU) bereits vor über einem Jahrzehnt einen neuen Weg ein. Trinity zeigte, wie die Integration von CPU-Kernen und leistungsfähiger integrierter Grafik in einem Chip mithilfe einer ausgeklügelten Northbridge-Architektur realisiert werden kann. Ein genauer Blick auf diese Northbridge zeigt nicht nur, welche technischen Herausforderungen bewältigt werden mussten, sondern auch, wie die damalige Lösung den Grundstein für spätere Innovationen legte. Die Trinity-APU wurde im Jahr 2012 eingeführt und kombinierte Piledriver-basierte CPU-Module mit einer iGPU der Terascale-3-Generation.
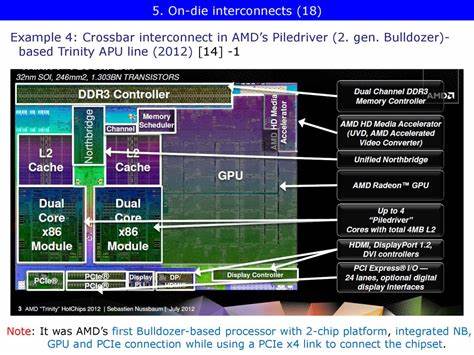
Während AMD bei der CPU-Architektur auf bewährte Technologien setzte, war die Herausforderung, CPU und iGPU effektiv miteinander zu verbinden, um eine möglichst leistungsstarke und effiziente Zusammenarbeit zu gewährleisten. Zu dieser Zeit war die klassische Northbridge, einst ein separater Chipsatz auf dem Mainboard, bereits auf die CPU gewandert. Doch an ihre ursprüngliche Funktion als zentraler Kommunikationsknoten zwischen CPU, Speicher und Peripherie erinnerte die Northbridge von Trinity nur noch in Teilen. AMD musste neue Wege finden, den Datenaustausch zwischen CPU und iGPU zu optimieren. Die zentrale Innovation von Trinity war die zweistufige Crossbar-Architektur, bestehend aus dem System Request Interface (SRI) und dem sogenannten XBAR.
Der SRI bündelt Speicheranfragen der CPU-Kerne, während der XBAR als eigentlicher Schalter fungiert, der Anfragen an den Speichercontroller oder die Ein- und Ausgabekomponenten weiterleitet. Bemerkenswert ist, dass sowohl der SRI als auch der XBAR in einem separaten Spannungs- und Frequenzbereich betrieben werden. Auf dem A8-5600K zum Beispiel läuft die Northbridge mit 1,8 GHz, während die CPU-Kerne schneller ticken. Diese Isolation erlaubte es AMD, den Datenverkehr präzise zu steuern und Engpässe zu minimieren. Eine Besonderheit von Trinity war die getrennte Speicheranbindung von CPU und GPU.
Die CPU kommunizierte primär über den Memory Controller (MCT), der für Cache-Kohärenz sorgte und Speicheranfragen optimierte. Dagegen erhielt die iGPU über den sogenannten „Radeon Memory Bus“, intern auch als „Garlic“ bezeichnet, direkten Zugang zu den DRAM-Controllern und umging die Cache-Kohärenz-Mechanismen des MCT. Gleichzeitig war die iGPU über eine zweite Verbindung, genannt „Onion“ oder Fusion Control Link, mit dem XBAR verbunden. Diese diente vor allem dazu, den Cache-Kohärenzmechanismus für die gemeinsame Nutzung des Cache-sensitiven Arbeitsspeichers sicherzustellen. Der entscheidende Vorteil des „Garlic“-Busses war, dass die iGPU den vollen Speicherzugriff mit hoher Bandbreite realisieren konnte, ohne durch die CPU-Kohärenzprotokolle ausgebremst zu werden.
Da CPUs und GPUs in der Regel unterschiedliche Datenbereiche nutzen, wäre ein umfassendes Cache-Snooping ineffizient und energieintensiv gewesen. Deshalb verzichtete AMD bewusst auf den Versuch, die iGPU in das Kohärenzmodell der CPU vollständig einzubinden, sondern schuf mit „Garlic“ und „Onion“ pragmatische Lösungen für jeweils spezielle Fälle. Die Speicherarchitektur von Trinity machte sich auch durch ausgeklügelte Bandbreiten- und Prioritätsmechanismen bemerkbar. So konnten sowohl der MCT als auch der Graphics Memory Controller (GMC) die Anzahl ausstehender Speicherzugriffe regulieren, um zu vermeiden, dass CPU oder GPU die Speichercontroller verdrängen. Die DRAM-Controller wiederum wechselten zwischen CPU- und GPU-Anforderungen, um eine ausgewogene Bandbreitennutzung zu gewährleisten.
Diese Harmonisierung sorgte dafür, dass die CPU trotz hoher iGPU-Bandbreitenanforderungen niedrige Latenzzeiten aufrechterhalten konnte – ein bedeutender Vorteil für die Performance bei gemischten Workloads. Die von Trinity gelieferten realen Leistungsdaten untermauern diesen technischen Fortschritt. Selbst unter hoher iGPU-Auslastung mit über 24 GB/s Lese- und Schreibzugriffen auf das DRAM blieb die CPU-Arbeitslatenz erstaunlich niedrig, typischerweise unter 120 Nanosekunden. Selbst in Szenarien mit gleichzeitig hoher CPU- und GPU-Belastung stiegen die Speicherlatenzen nicht dramatisch an. Diese Effizienz war eine wichtige Voraussetzung dafür, dass Trinity, obwohl auf DDR3-RAM setzt, für den damaligen Einstieg in den anspruchsvolleren Grafikbereich konkurrenzfähig blieb.
Doch die Architektur war nicht ohne Kompromisse. Die „Onion“-Verbindung zur Aufrechterhaltung der Cache-Kohärenz war auf niedrigere Bandbreiten limitiert und erreichte etwa 10 GB/s. Bei Zugriffen auf GPU-verwalteten Speicher von CPU-Seite her musste der Speicher uncachebar (technisch write-combining) behandelt werden, was für die CPU deutliche Performanceeinbußen bedeutete. Zudem existierte keine spezielle Filtermechanik für Cache-Probes, was zu einem enormen Anstieg des Probeverkehrs – teils mehr als 45 Millionen Antworten pro Sekunde – führte. Diese Situation unterschied AMD klar von Intel, die bereits mit Sandy Bridge und Ivy Bridge eine nahtlos integrierte CPU-GPU-Architektur auf einer gemeinsamen Ringbus-Struktur umgesetzt hatten.
Bei Intel war die iGPU ein direkter Client des L3-Caches, sodass CPU und GPU eine gemeinschaftliche, kohärente Speicherinfrastruktur nutzten. AMD hatte bei Trinity zwar das Potenzial leistungsfähiger iGPUs erkannt, doch ihre Interconnect-Lösung war eher ein Kompromiss, der trotz einiger Schwächen ausreichend funktionierte. Die Bandbreitenmessungen bei realen Anwendungen vermitteln ein präziseres Bild. Benchmark-Durchläufe wie bei Unigine Valley oder Final Fantasy 14 zeigten, dass der Großteil des Speicherverkehrs über die „Garlic“-Verbindung lief. Selbst bei grafikintensiven Szenarien blieb die CPU-Seite relativ unbelastet und nutzte meist nur wenige Gigabyte pro Sekunde.
Programme, die stark CPU-lastig sind und keine GPU-Beschleunigung verwenden, zeigen hingegen einen deutlich höheren Traffic über das XBAR, da alle Speicheranforderungen dort abgewickelt werden. Die Auswirkungen auf die Anwendungsperformance waren ambivalent. Trinity erlaubte erstmals ein zero-copy-Verhalten, bei dem geteilte Speicherbereiche zwischen CPU und iGPU ohne explizite Kopiervorgänge genutzt werden konnten. Die Einschränkungen in der Kohärenz und im Zugriffsverhalten führten jedoch dazu, dass CPU und GPU bei gegenseitigem Zugriff auf den jeweils anderen Speicherbereich spürbare Leistungseinbußen hinnehmen mussten, insbesondere in Anwendungen, die intensive gemeinsame Speicheroperationen ausführen wollten. Dennoch konnte AMD mit Trinity den Markt für budgetorientierte Gaming-APUs prägen und eine solide Grundlage schaffen, auf der spätere Generationen aufbauen konnten.
Die damalige Architektur zeigte, dass leistungsfähige integrierte Grafik über eine intelligente Speicheranbindung realisierbar war, auch wenn der Schritt von der Northbridge-basierten Architekturen hin zu moderneren Interconnects noch bevorstand. Mittlerweile hat AMD mit der Einführung der Zen-Ära und der zentralen Infinity Fabric Interconnect-Technologie die Speicherintegration von CPU und GPU deutlich vereinheitlicht und die Limitierungen bei Kohärenz, Bandbreite und Latenz weitgehend beseitigt. Diese neuen Systeme ermöglichen kohärenten Zugriff auf gemeinsame Speicherbereiche, verbesserte Bandbreitenverwaltung und ein deutlich effizienteres Zusammenspiel der Systemkomponenten. Zusammenfassend lässt sich sagen, dass Trinity und ihre Northbridge-Architektur ein Meilenstein in der Entwicklung von AMDs heterogenen Computing-Plattformen war. Sie veranschaulichen die technischen Herausforderungen und kreativen Lösungen einer Zeit, in der die Integration von leistungsstarken iGPUs noch in den Kinderschuhen steckte.
Trotz gewisser Kompromisse ermöglichte diese Architektur eine neue Klasse von Produkten, die den Weg für heutige High-Performance-APUs ebneten. Für Technikinteressierte und Historiker ist Trinity ein faszinierendes Beispiel für die evolutionäre Architekturentwicklung im Halbleiterbereich und ein Zeugnis für AMDs Innovationskraft in einer wegweisenden Epoche.