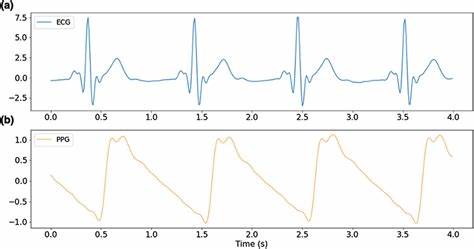
Die Integration von künstlicher Intelligenz in die medizinische Diagnostik erfährt derzeit eine bemerkenswerte Entwicklung, besonders auf dem Gebiet der Herzuntersuchungen mittels Elektrokardiogrammen (EKG). Im Zentrum dieser Fortschritte stehen die sogenannten Elektrokardiogramm-Sprachmodelle (ELMs), welche auf großen Sprachmodellen (LLMs) basieren und darauf ausgelegt sind, EKG-Daten zu interpretieren und in menschenähnlicher Weise verständliche Diagnosen, Analyseberichte sowie individuelle Therapieempfehlungen zu generieren. Doch um das volle Potenzial dieser Technologien auszuschöpfen, stellt sich eine essentielle Frage: Welche Form der Datenrepräsentation ist für die Eingabe in solche Sprachmodelle am effektivsten? Im Gegensatz zu traditionellen, oft auf Klassifikation basierenden EKG-Analysewerkzeugen, bieten ELMs eine weitaus umfassendere und flexiblere Herangehensweise an die Diagnose. Sie können aus komplexen zeitlichen Verläufen des EKGs den Zustand des Herzens interpretieren, morphologische Besonderheiten der Wellenformen herausarbeiten und sogar patientenspezifische Faktoren einbeziehen, um maßgeschneiderte Handlungspläne vorschlagen zu können. Diese Fähigkeiten beruhen maßgeblich darauf, wie die EKG-Informationen den Modellen präsentiert werden.
Forschende haben in jüngster Zeit intensiv verschiedene Eingabesegmente untersucht, dabei kristallisieren sich drei Hauptkategorien heraus: rohe Zeitseriensignale, gerenderte Bilddarstellungen und symbolisch diskretisierte Sequenzen. Jedes dieser Formate bringt spezifische Eigenschaften, Vorteile und Herausforderungen mit sich. Rohzeitseriensignale sind praktisch das Originalsignal des EKGs in digitaler Form, das unbehandelt sämtliche Frequenzen, Amplituden und zeitlichen Abläufe beinhaltet. Renderings als Bild erlauben es, die visuellen Darstellungen, wie sie Herzspezialisten üblicherweise interpretieren, direkt zu nutzen und können räumliche Muster betonen. Symbolische Repräsentationen dagegen wandeln die kontinuierlichen Signale in diskrete Symbole um, etwa durch Clustern von Signalmerkmalen oder Umwandlung in eine abstrahierte Form, die potenziell die Modellverarbeitung erleichtert und fokussierter gestaltet.
Eine vielversprechende Studie verglich diese Formate systematisch über sechs öffentliche EKG-Datensätze und bewertete die Leistung anhand von fünf verschiedenen Metriken. Die Ergebnisse zeigten, dass symbolische Eingabedarstellungen gegenüber reinen Rohsignalen und Bilddaten signifikante Vorteile in der Genauigkeit und Robustheit aufweisen. Dies deutet darauf hin, dass ein gezieltes Vorverarbeiten und Abstrahieren der EKG-Signale erheblich zur Leistungssteigerung von ELMs beiträgt. Darüber hinaus untersuchten die Forschenden wichtige Einflussfaktoren wie die Wahl der Sprachmodell-Backbones, die Dauer der analysierten EKG-Segmente sowie das zulässige Token-Budget, also die Menge an Information, die ein Modell pro Eingabe verarbeiten darf. Interessanterweise zeigte sich, dass die optimale Eingaberepräsentation auch von diesen Parametern abhängt.
So kann ein gut angepasstes symbolisches System selbst bei begrenztem Token-Budget eine vollständige und präzise Diagnose ermöglichen, während rohe Daten oft eine größere Verarbeitungskapazität erfordern, um dieselbe Detailtiefe zu erzielen. Ein weiterer Aspekt, der in der klinischen Praxis von erheblicher Bedeutung ist, betrifft die Robustheit der Modelle gegenüber Signalstörungen, die durch Artefakte, Bewegungen oder technische Probleme entstehen können. Hier erwiesen sich symbolische Darstellungen ebenfalls als resilienter. Durch ihre abstrahierte, verdichtete Form sind sie weniger anfällig für kleine, irrelevante Schwankungen der Rohdaten, was eine stabilere und zuverlässigere Leistung ermöglicht. Die innovative Kombination von modernster KI-Forschung mit kardiologischer Expertise verspricht damit nicht nur genauere Diagnosen, sondern auch eine Verbesserung der Patientenversorgung insgesamt.
Die Fähigkeit von ELMs, nicht nur simple Klassifikationen vorzunehmen, sondern vollständige dialogbasierte Berichte und Empfehlungen zu formulieren, könnte die Kommunikation zwischen Ärzten und Patienten revolutionieren und zudem die Effizienz in Kliniken steigern. Natürlich stehen noch Herausforderungen bevor. Die Qualität und Quantität der zugrunde liegenden Instruction-Tuning-Datensätze ist ein limitierender Faktor. Um ELMs wirklich praxisreif zu machen, sind groß angelegte, vielfältige und gut annotierte Daten notwendig, die verschiedene Patientengruppen, Krankheitsbilder und technische Bedingungen abdecken. Ferner müssen ethische und Datenschutzaspekte stets berücksichtigt werden, damit der Einsatz solcher Systeme verantwortungsvoll erfolgt.
Abschließend lässt sich festhalten, dass die Wahl der richtigen Eingabedarstellung einen maßgeblichen Einfluss auf den Erfolg von Elektrokardiogramm-Sprachmodellen hat. Symbolische Repräsentationen bieten derzeit den vielversprechendsten Ansatz, um die Vorteile großer Sprachmodelle in diesem sensiblen medizinischen Bereich maximal zu nutzen. Durch eine sorgfältige Gestaltung der Datenpipeline und die Berücksichtigung von klinischen Anforderungen wird die Zukunft der automatisierten Herzdiagnostik zweifellos von diesen Erkenntnissen profitieren. Mit der fortschreitenden Forschung und technologischen Weiterentwicklung dürfte die Integration von ELMs in den klinischen Alltag zunehmend Realität werden. Dies eröffnet Ärzten neue Möglichkeiten, die komplexen Signale des Herzens besser zu verstehen und Patienten schneller sowie präziser zu behandeln.
Die Transformation der Elektrokardiographie durch die Kraft der künstlichen Intelligenz steht somit kurz bevor und markiert einen bedeutenden Meilenstein in der kardiologischen Medizin.