Die rasante Entwicklung künstlicher Intelligenz (KI), insbesondere im Bereich der großen Sprachmodelle, hat das Potenzial, die Gesundheitsversorgung grundlegend zu verändern. Um jedoch sicherzustellen, dass diese neuen Technologien nicht nur leistungsfähig, sondern auch vertrauenswürdig und sicher sind, ist es von zentraler Bedeutung, ihre Fähigkeiten in realistischen medizinischen Kontexten zu überprüfen. Genau hier setzt HealthBench an – ein neu entwickeltes Benchmark-System zur umfassenden Bewertung von KI-Modellen im Gesundheitswesen, das auf die komplexen Anforderungen im klinischen Alltag eingeht. HealthBench wurde in enger Zusammenarbeit mit 262 erfahrenen Ärztinnen und Ärzten aus 60 Ländern entwickelt, die ihre Expertise aus einer Vielzahl von medizinischen Fachgebieten einbrachten. Diese Ärztinnen und Ärzte halfen dabei, 5.
000 realitätsnahe Gesprächsszenarien zwischen Nutzer beziehungsweise Patient und einem KI-System zu erstellen. Das Ziel dieser Szenarien ist es, typische Interaktionen abzubilden, wie sie in der Praxis bei der Beratung, Diagnoseunterstützung oder Versorgungskontrolle vorkommen könnten. Diese Gespräche sind mehrstufig, umfassen verschiedene Sprachen und bedienen unterschiedliche Benutzerprofile – darunter sowohl medizinisches Fachpersonal als auch Laien – und decken eine breite Palette von medizinischen Spezialgebieten und Kontexten ab. Ein wesentliches Merkmal von HealthBench ist die Verwendung ausführlicher, ärztlich entwickelter Bewertungskriterien. Jedes KI-Response wird anhand eines individuellen Rubriksystems beurteilt, das festlegt, welche Informationen enthalten sein sollten und welche Fehler es unbedingt zu vermeiden gilt, wie etwa die Nutzung unnötig komplexer Fachbegriffe oder das Verschweigen wichtiger Sicherheitswarnungen.
Insgesamt umfasst HealthBench über 48.000 einzelne Bewertungskriterien, was eine tiefgehende und facettenreiche Analyse der KI-Antworten ermöglicht. Die KI-Antworten werden mit Hilfe eines Modell-basierten Bewertungssystems überprüft, das auf GPT‑4.1 basiert und die Erfüllung der einzelnen Kriterien automatisiert ermittelt. Dadurch kann eine objektive und reproduzierbare Bewertung sichergestellt werden, die eng mit der ärztlichen Einschätzung korrespondiert.
Dieses Vorgehen gewährleistet eine hohe Glaubwürdigkeit der Ergebnisse und erlaubt es Entwicklern, gezielt Schwachstellen zu identifizieren und gezielte Verbesserungen an den Modellen vorzunehmen. HealthBench legt dabei besonderen Wert auf drei zentrale Qualitätsmerkmale. Die Bewertung soll bedeutungsvoll sein, das heißt, dass die Punktzahlen einen realen Einfluss auf die Patientenversorgung reflektieren – weit über einfache Prüfungsfragen hinaus. Die Kriterien reproduzieren echte klinische Arbeitsabläufe und Kommunikationssituationen. Gleichzeitig ist HealthBench vertrauenswürdig, indem es die medizinische Fachmeinung authentisch abbildet.
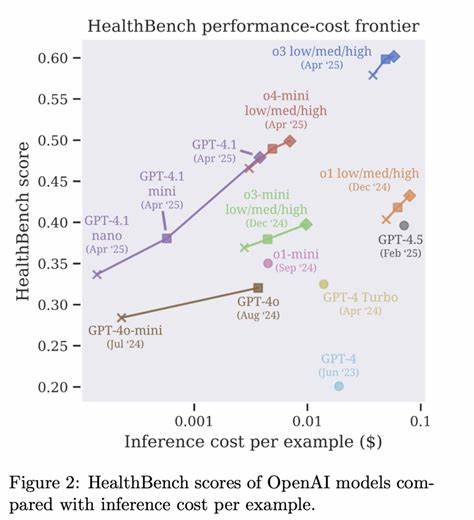
Dies schafft eine fundierte Grundlage für die stetige Verbesserung der KI-Modelle. Nicht zuletzt soll die Benchmark ungesättigt sein, was bedeutet, dass sie so anspruchsvoll gestaltet ist, dass auch hochentwickelte Systeme noch Verbesserungsmöglichkeiten haben und der technologische Fortschritt weiter vorangetrieben wird. Der Einsatz von HealthBench hat bereits spannende Erkenntnisse gebracht. So zeigen Analysen, dass die jüngsten OpenAI-Modelle, darunter o3 und GPT-4.1, deutliche Fortschritte in ihrer medizinischen Kompetenz gegenüber früheren Versionen erzielt haben.
Insbesondere konnten sie in der Sicherheit und Verlässlichkeit der Antworten punkten und zeigen eine bessere Anpassungsfähigkeit an komplexe und mehrdeutige Fragestellungen. Dennoch gibt es weiterhin Bereiche, etwa die Kontextsensitivität bei nicht klar definierten Nutzeranfragen und die Worst-Case-Verlässlichkeit, in denen Verbesserungen dringend notwendig sind. Die Anwendungen von HealthBench sind vielfältig. In der medizinischen Forschung und bei der Entwicklung von klinischen Assistenzsystemen bietet es eine standardisierte Möglichkeit, KI-Modelle vor dem Einsatz im realen Umfeld zu testen und zu validieren. Für Entwickler bedeutet HealthBench, gezielte Rückmeldungen zur Modellleistung und Verbesserungspotenzial zu erhalten, die auf fundiertem medizinischem Rat basieren.
Für Gesundheitseinrichtungen und Anwender kann es helfen, den richtigen Mix an KI-Technologien auszuwählen, die sichere Empfehlungen geben und Behandlungsprozesse unterstützen. HealthBench erfasst zudem Themen wie Notfallmanagement, das Arbeiten unter Unsicherheit, die Kommunikation auf unterschiedlichsten Expertise-Ebenen, globale Gesundheitsfragen sowie den Umgang mit Gesundheitsdaten. Diese Breite spiegelt die Vielseitigkeit der Herausforderungen wider, denen medizinisch eingesetzte KI begegnen muss. Des Weiteren ermöglicht die Plattform die Messung verschiedener Qualitätsdimensionen wie Kommunikationsqualität, Genauigkeit, Kontextwahrnehmung und Vollständigkeit der Antworten. Ein weiterer relevanter Aspekt ist die Rolle von HealthBench in der globalen Gesundheit.
KI hat das Potenzial, ärztliche Fachkenntnisse auch in unterversorgte Regionen zu bringen und so die Gesundheitsgerechtigkeit zu fördern. Indem HealthBench auch multilinguale und regionale Gesundheitskontexte berücksichtigt, wird sichergestellt, dass die KI-Systeme entsprechend angepasst und verlässlich sind – ein entscheidender Punkt für den tatsächlichen Nutzen in weltweiten Anwendungen. Die Verfügbarkeit von HealthBench als offenes Evaluationsframework und Datensatz auf GitHub stärkt zudem die Zusammenarbeit in der Wissenschafts- und Entwicklergemeinschaft. So profitieren Forscher weltweit von einem gemeinsamen Bezugspunkt für Bewertungen und können gemeinsam daran arbeiten, die KI-Modelle im Gesundheitsbereich sicherer und intelligenter zu machen. Zusammenfassend stellt HealthBench einen großen Schritt dar, um für den Einsatz von künstlicher Intelligenz in einem so sensiblen Bereich wie der Medizin echte Qualitätsstandards zu etablieren.