In der heutigen Ära der Big Data ist die Fähigkeit, riesige Datenmengen effizient zu verarbeiten, von zentraler Bedeutung. Eine der bahnbrechenden Technologien, die diese Herausforderung meisterte, ist MapReduce, ein Modell und Framework, das erstmals in einem wegweisenden Google-Paper vorgestellt wurde. Die Idee dahinter ist einfach, aber revolutionär: Große Datenmengen werden in überschaubare Teilaufgaben zerlegt, parallel verarbeitet und anschließend zusammengeführt. Während MapReduce die Grundlage für viele moderne verteilte Datenverarbeitungssysteme bildet, kann das Verständnis der internen Funktionsweise und der Umsetzung dieses Modells einen erheblichen Vorteil für Entwickler und Datenwissenschaftler darstellen. MapReduce basiert auf zwei Hauptfunktionen: Map und Reduce.
Die Map-Funktion nimmt jeweils einen Datenabschnitt auf, verarbeitet ihn und erzeugt eine Menge von Schlüssel-Wert-Paaren. Die Reduce-Funktion übernimmt dann alle Werte, die zu einem bestimmten Schlüssel gehören, und fasst sie zu einem Endergebnis zusammen. Diese Struktur ermöglicht es, komplexe Datenverarbeitungsaufgaben wie Sortieren, Filtern oder Aggregieren effizient zu distribuieren und zu verarbeiten. Die Vision von Google war es, dieses Modell zu nutzen, um massive Mengen an Webdaten zu analysieren und dadurch unter anderem bessere Suchindexe zu erstellen. Durch die Aufteilung der Daten und der Rechenleistung auf zahlreiche Server wird eine enorme Skalierbarkeit erreicht, was für traditionelle Datenbankansätze kaum möglich wäre.
Besonders beeindruckend dabei ist, wie MapReduce automatisch mit Fehlern umgeht, indem fehlgeschlagene Tasks neu gestartet werden, sodass die Zuverlässigkeit der Verarbeitung gewährleistet ist. Die praktische Umsetzung dieser theoretischen Grundlagen stößt jedoch auf einige Herausforderungen. Beim Versuch, MapReduce von Grund auf neu zu implementieren, müssen Entwickler eine Infrastruktur schaffen, die Datenverteilung, Aufgabenverwaltung, Fehlerbehandlung und Kommunikationsmechanismen zwischen den einzelnen Knoten eines Rechenclusters regelt. Die Wahl der Programmiersprache, die Gestaltung der API und die Optimierung der Performance sind ebenso entscheidend. Ein aktuelles Projekt, welches diese Prinzipien nachvollziehbar umsetzt, bietet ein minimalistisch gestaltetes MapReduce-System in der Programmiersprache Go.
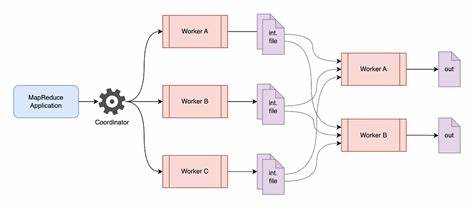
Diese Implementierung dient als hervorragendes Beispiel, wie die Kernaspekte von MapReduce – das Zerlegen in Map- und Reduce-Aufgaben, die Verteilung auf Worker-Knoten und die anschließende Zusammenführung der Ergebnisse – in einem überschaubaren und gut verständlichen Code realisiert werden können. Die Nutzung von Go bringt dabei Vorteile wie einfache Parallelität, effiziente Channel-Kommunikation und eine vergleichsweise leichtgewichtige Laufzeit. Die Architektur eines solchen Systems umfasst typischerweise einen Master-Knoten, der die Koordination übernimmt, und mehrere Worker-Knoten, die die eigentliche Datenverarbeitung durchführen. Der Master ist verantwortlich für das Zuweisen der Map- und Reduce-Tasks, das Überwachen des Fortschritts und das Wiederholen fehlgeschlagener Aufgaben. Die Worker empfangen ihre Aufgaben, führen sie aus und senden die Ergebnisse zurück.
Neben der schlichten Verteilung der Arbeit müssen Mechanismen implementiert werden, die sicherstellen, dass bei Ausfällen einzelner Knoten keine Daten verloren gehen und die Gesamtausführung dennoch fortschreiten kann. Ein weiteres zentrales Thema ist das Handling der Ein- und Ausgabeformate. Die Eingabedaten werden oftmals als große Dateien bereitgestellt, die in kleinere Chunks gesplittet werden. Die Map-Funktionen verarbeiten diese Teile unabhängig voneinander. Deren Ausgaben – sortierte Schlüssel-Wert-Paare – werden für die Reduce-Phase aufbereitet und entsprechend verteilt.
Erst nach erfolgreicher Reduzierung entsteht das finale Ergebnis, das zum Beispiel als aggregierte Statistik, sortierte Liste oder beliebige andere Form dargestellt werden kann. Zusätzlich zum technischen Aspekt lohnt es sich, die Anwendungsgebiete von MapReduce näher zu betrachten. Ob in der Webanalyse, der Verarbeitung von Logdateien, in Bioinformatik, maschinellem Lernen oder Finanzdaten – MapReduce hat zahlreiche Bereiche durch seine effiziente Datenverarbeitung geprägt. Besonders Unternehmen, die mit enormen Datenbeständen arbeiten und diese zuverlässig analysieren müssen, profitieren enorm von diesem Konzept. Die Replikation eines MapReduce-Systems aus dem Google-Paper nachzubauen bietet wichtige Einblicke in die Mechanismen verteilter Systeme und die Herausforderungen paralleler Datenverarbeitung.
Das Verstehen der damit verbundenen Konzepte, wie Task-Scheduling, Fault-Tolerance und Datenpartitionierung, ist heute unabdingbar für jeden, der sich mit Big Data und verteilten Systemen beschäftigt. Darüber hinaus gibt die praktische Umsetzung, insbesondere in einer zugänglichen Sprache wie Go, wertvolle Erfahrungen in Sachen Systemprogrammierung, API-Design und paralleler Verarbeitung. Sie bringt Entwickler dazu, über Performance-Engpässe nachzudenken, Fehlerquellen zu eliminieren und robustes Systemdesign zu fördern. Für alle, die tiefer in das Thema einsteigen wollen, stehen mittlerweile zahlreiche Ressourcen zur Verfügung, darunter ausführliche Anleitungen, offene Quellcodes und Blogbeiträge von Experten, die den Nachbau von MapReduce demonstrieren und analysieren. Ein gutes Beispiel ist ein aktueller Leitfaden, der den gesamten Prozess des Aufbaus von MapReduce von Grund auf erklärt und durch einen dazugehörigen GitHub-Repository-Code ergänzt wird.
Abschließend lässt sich festhalten, dass MapReduce weit mehr als nur ein Framework ist. Es steht symbolisch für einen Wandel in der Art und Weise, wie Datenverarbeitungskonzepte gedacht und realisiert werden. Durch das Zerlegen von Aufgaben und die Nutzung verteilter Systeme hat es die Effizienz und Skalierbarkeit in der Datenanalyse revolutioniert. Wer heute große Datenmengen bewältigen muss, sollte sich mit dem Modell vertraut machen – sei es zum besseren Verständnis der dahinter stehenden Prinzipien oder zur praktischen Anwendung in eigenen Projekten. Das Aufbauen eines eigenen MapReduce-Systems ist somit nicht nur eine technische Herausforderung, sondern auch eine wertvolle Lerngelegenheit.
Es fördert das Verständnis verteilter Systeme, paralleler Programmierung und robuster Softwarearchitekturen. Mit den richtigen Ressourcen, etwas Geduld und Neugier kann jeder Entwickler nachvollziehen, warum dieses Modell in der Welt der Datenverarbeitung einen festen Platz eingenommen hat.