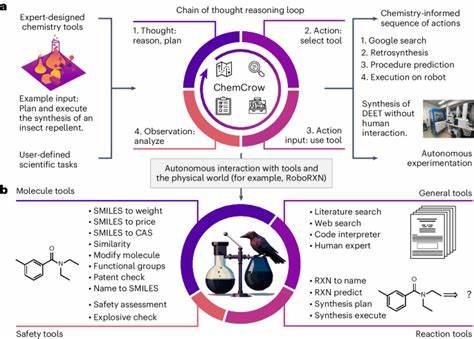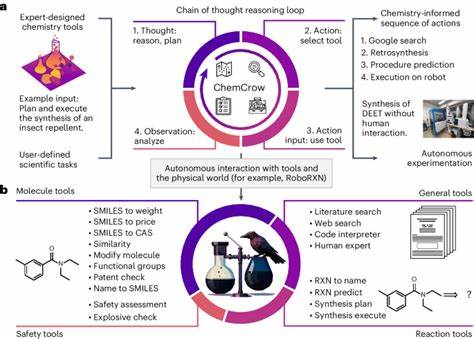
Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat in den letzten Jahren zahlreiche Fachgebiete beeinflusst. Insbesondere in der Chemie eröffnen solche KI-Systeme neue Möglichkeiten, wissenschaftliche Texte zu verarbeiten, chemisches Wissen abzurufen und sogar komplexe Fragestellungen zu beantworten. Doch wie stehen diese künstlichen Intelligenzsysteme im Vergleich zur menschlichen Expertise von Chemikern? Welche Fähigkeiten besitzen LLMs, wo sind ihre Grenzen, und welche Auswirkungen hat dies auf Forschung, Ausbildung und praktische Anwendungen? Um diese Fragen zu klären, wurde mit ChemBench ein neuartiges Bewertungsframework entwickelt, das die Kenntnisse und das logische Denken von LLMs gezielt anhand chemischer Fragestellungen misst und mit den Leistungen von Chemiker*innen vergleicht. Große Sprachmodelle basieren auf maschinellem Lernen, das durch riesige Textmengen trainiert wird. So gelingt es ihnen, Sprache zu verstehen und darauf zu reagieren, selbst bei Themen, die nicht explizit Bestandteil ihres Trainings waren.
Dies führte zu beeindruckenden Erfolgen, wie dem Bestehen medizinischer Zulassungsprüfungen oder der selbstständigen Planung und Durchführung chemischer Reaktionen, wenn sie mit ergänzenden Werkzeugen kombiniert werden. Trotz der Fortschritte bestehen jedoch Zweifel, ob LLMs wirklich ein Verständnis chemischer Sachverhalte besitzen oder nur Muster aus dem Trainingsdatensatz wiedergeben, ohne tiefgehendes fachliches Verständnis oder nachvollziehbare Schlussfolgerungen zu ziehen. ChemBench ist ein umfassendes Bewertungstool, das über 2.700 Fragen aus unterschiedlichsten chemischen Themenbereichen enthält. Es wurde entwickelt, um den Wissensstand und die Fähigkeit zur logischen Schlussfolgerung von modernen LLMs zu testen.
Dabei werden nicht nur Faktenwissen, sondern auch komplexe Problemlösungen sowie chemische Intuition abgefragt. Die Fragen stammen aus Universitätsprüfungen, Fachliteratur und programmierten Szenarien und decken die gesamte Breite der Chemie ab – von Allgemein- und Technischer Chemie bis hin zu Spezialisierungen wie analytischer oder anorganischer Chemie. Das Ziel von ChemBench ist es, LLMs objektiv und transparent mit der Leistung menschlicher Chemiker*innen zu vergleichen. Dafür wurden Testpersonen mit unterschiedlichem Erfahrungshintergrund eingeladen, die gleichen Fragen unter Bedingungen mit und ohne Zugriff auf Hilfsmittel wie Websuche zu beantworten. Die Ergebnisse dieser Studie zeigen überraschende Erkenntnisse: Das beste aktuell verfügbare LLM übertraf im Durchschnitt die Leistung der befragten Chemiker*innen deutlich, manche Open-Source-Modelle konnten sogar mit proprietären Systemen mithalten.
Dies lässt auf ein enormes Potenzial schließen, das KI-gestützte Systeme zukünftig in der Chemie entfalten können. Trotz der beeindruckenden Gesamtleistung zeigen die Modelle jedoch klare Schwächen, insbesondere bei einfachen Aufgaben, die präzises Faktenwissen erfordern. So gelingt es ihnen nicht immer, grundlegendes chemisches Faktenwissen korrekt abzurufen oder Fragen zur Sicherheit von chemischen Substanzen zuverlässig zu beantworten. Das bedeutet, dass Modelle zwar große Datenmengen speichern und kombinieren können, es ihnen aber vielfach an einer zuverlässigen, nachvollziehbaren und fehlerfreien Wissensbasis fehlt. Ein Problem, das durch das sogenannte „Übervertrauen“ verstärkt wird, bei dem die Modelle ihre Antworten häufig ohne angemessene Unsicherheitsabschätzung präsentieren und damit potenziell falsche oder gefährliche Informationen verbreiten können.
Die Analyse des Antwortverhaltens entlang verschiedener chemischer Themen zeigt zudem, dass LLMs in einigen Bereichen wie allgemeiner und technischer Chemie gute Trefferquoten erzielen, während etwa in der analytischen Chemie oder bei Aufgaben zu Toxizität und Sicherheit deutliche Defizite bestehen. Ein besonders interessanter Befund ergibt sich bei strukturell-chemischen Aufgaben, zum Beispiel bei der Bestimmung der Anzahl unterschiedlicher Signale im Kernspinresonanzspektrum. Dort schneiden die KI-Systeme schlechter ab als Menschen, was darauf hindeutet, dass reine Textmodelle Schwierigkeiten haben, strukturelle oder räumliche Aspekte adäquat zu verarbeiten. Ein weiterer entscheidender Aspekt für den praktischen Nutzen von LLMs in der Chemie ist die Fähigkeit der Modelle, ihre eigene Sicherheit bzw. Zuverlässigkeit bei den Antworten einzuschätzen.
Eine mangelhafte Kalibrierung der Konfidenz führt dazu, dass Nutzer*innen falsche Sicherheit in die Resultate investieren könnten. Die Untersuchungen mit ChemBench legen jedoch nahe, dass derzeitige Sprachmodelle bei der Selbsteinschätzung schwächeln und teilweise sehr hohe Vertrauenswerte bei fehlerhaften Antworten angeben. Dies unterstreicht, wie wichtig es ist, dass Anwender*innen die Resultate kritisch hinterfragen und niemals blind vertrauen. Neben der reinen Wissensvermittlung wurden auch Fragen zur „chemischen Präferenz“ untersucht – also der menschlichen Intuition, welches von zwei Molekülen bevorzugt wird etwa im Kontext der Wirkstoffforschung. LLMs zeigten hier keine Übereinstimmung mit den Präferenzen von erfahrenen Chemiker*innen, was deutlich macht, dass die Erfassung subtiler, erfahrungsbasierter Urteile derzeit außerhalb der Fähigkeiten dieser Modelle liegt.
Wie lässt sich die Leistung der LLMs erklären und verbessern? Ein Faktor ist die Größe des Modells: Es zeigte sich ein positiver Zusammenhang zwischen Modellgröße und Genauigkeit der Antworten, was nahelegt, dass größere Modelle prinzipiell mehr lernen und wiedergeben können. Allerdings reicht das reine Vergrößern nicht aus; der spezielle Einsatz von Fachwissen, das Training mit spezialisierten chemischen Datenbanken sowie die Integration von externen Datenquellen und Tools sind erfolgsversprechende Wege, um Wissenslücken zu schließen. Die Forschenden empfehlen zudem, chemische Bildung und Prüfungsformate an die neue Realität anzupassen. Da LLMs bei der Wiedergabe von Fakten und einfachen Problemlösungen bereits den Menschen überlegen sind, müssen Lehrpläne mehr Wert auf kritisches Denken und die Fähigkeit legen, komplexe Probleme eigenständig zu durchdringen. Nur so bleiben Chemiker*innen in einer Partnerschaft mit KI unverzichtbar.
Der Einsatz von ChemBench für Entwickler von LLMs in der Chemie schafft einen wichtigen Standard zur objektiven Überprüfung von Verbesserungen. Neben der Leistungsmessung hilft es auch, Risiken zu erkennen, etwa bei Sicherheitsbewertungen, und eine verantwortungsvolle Nutzung zu fördern. Offene Benchmarks mit Community-Einbindung, wie ChemBench, sind Schlüsselwerkzeuge, um Fortschritte transparent zu dokumentieren und die Modelle fit für die Praxis zu machen. Zukünftige Forschung wird sich intensiv damit beschäftigen, wie LLMs besser strukturelles chemisches Wissen darstellen können, etwa durch multimodale Ansätze, die neben Text auch molekulare Graphen oder 3D-Strukturen verarbeiten. Die Kombination aus KI und domänenspezifischer Expertise kann Forschung schneller machen und neue Entdeckungen ermöglichen.