In der heutigen IT-Landschaft sind verteilte Systeme und große Mengen an Log-Daten allgegenwärtig. Unternehmen stoßen zunehmend auf Herausforderungen, wenn es um die Erfassung, Analyse und schnelle Abfrage großer Logs aus mehreren Hosts geht. Bekannte Lösungen wie Graylog sind zwar funktional und leistungsfähig, stehen aber häufig in der Kritik aufgrund komplexer Wartungsanforderungen und hoher Systemaufwände. Als Antwort darauf hat sich Nerdlog als eine einfache, schnelle und zentrale Server-freie Alternative etabliert, die den Fokus auf Performance, Minimalismus und Verlässlichkeit legt. Das Problem mit herkömmlichen Logsystemen Traditionelle Log-Management-Plattformen bündeln Logs idealerweise in einer zentralisierten Datenbank mit Indexierung und leistungsfähiger Suchoberfläche.
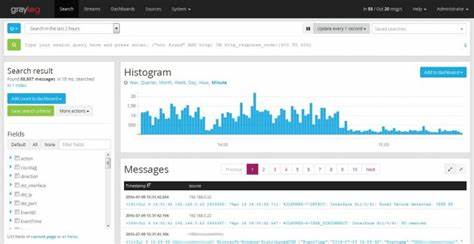
Graylog etwa ermöglicht eine fast Echtzeit-Abfrage mehrerer Millionen Log-Einträge pro Stunde und bietet komfortable Filtermöglichkeiten. Allerdings sind solche Lösungen mit einem erheblichen administrativen Aufwand verbunden und erfordern eine leistungsfähige, wartungsintensive Infrastruktur. Einige Nutzer berichten auch von Problemen mit Datenverlust, Verzögerungen bei der Verarbeitung und gelegentlicher Unzuverlässigkeit, gerade in stark verteilten Umgebungen oder bei sehr hoher Logging-Rate. Splunk, ein prominentes Log-Analyse-Tool, wird oft als Alternative eingesetzt. Doch trotz seines Markenrufs sorgt es bei vielen Anwendern eher für Frust.
Insbesondere bei großen Datenmengen treten lange Antwortzeiten auf, und selbst die verfügbaren „schnellen“ Modi sind oft mit deutlichen Einschränkungen verbunden. Viele Anwender suchen daher eine unkomplizierte Möglichkeit, große Log-Daten schnell und zuverlässig zu durchsuchen, ohne die Komplexität und die Kosten großer Systeme. Nerdlog als radikal einfache Lösung Die Grundidee hinter Nerdlog ist verblüffend simpel: Statt Logs in eine zentrale Datenbank zu kopieren und zu indexieren, verbindet sich das Tool per SSH direkt mit den Hosts und liest die dort lokal vorliegenden Log-Dateien. Dabei greift der Client auf gängige Linux-Tools wie awk und bash zurück, um die Logs zu filtern und eine schnelle Datenaggregation durchzuführen. Dies verzichtet völlig auf eine zentrale Logging-Infrastruktur und damit auf deren Wartungsaufwand.
Der Client ist eine Terminal-basierte Anwendung, die eine intuitive Benutzeroberfläche über eine Timeline-Histogramm-Visualisierung der Logs bietet. So lassen sich Zeitbereiche übersichtlich auswählen und Suchmuster dynamisch anwenden. Technische Details und Performance-Optimierungen Ein großer Vorteil von Nerdlog liegt in gezielten Optimierungen auf Host-Seite. Im Gegensatz zu einer einfachen zeilenweisen Suche durch die komplette Log-Datei kommen vorberechnete Indizes zum Einsatz, die den Zugriff auf spezifische Zeitabschnitte enorm beschleunigen. Diese Indizes speichern Zeitstempel mit zugehörigen Byte-Offsets oder Zeilennummern.
Dadurch kann das Tool per Dateiverschiebung (lseek) direkt an die relevanten Stellen springen und nur einen kleinen Ausschnitt der Daten lesen. Das reduzierte Datenvolumen wird dann mittels eines ausgefeilten awk-Skripts gefiltert und nach bestimmten Mustern durchsucht. Der gesamte Prozess erfordert keine komplexe Datenbank, sondern nutzt bewährte, standardisierte UNIX-Kommandos. Die Verwendung von Byte-Offset-Indizes steigert die Geschwindigkeit im Vergleich zu reinen Zeilennummerlösungen nochmals erheblich. Mit dieser Methode beschleunigt sich die Suche in einer Gigabyte-großen Datei von mehreren Sekunden auf wenige Hundert Millisekunden.
Flexibilität bei der Protokollquelle Ursprünglich setzt Nerdlog ausschließlich auf klassische, unstrukturierte Log-Dateien wie /var/log/syslog. Als weiterer Protokoll-Quelle lässt sich inzwischen auch journalctl verwenden - das Standard-Tool zur Abfrage von systemd-Journalen. Journalctl bietet häufig längere und systematisierte Protokollhistorien, ist jedoch deutlich langsamer als die direkten Dateioperationen. Zudem wurde bei der Nutzung von journalctl mit verteilten Systemen festgestellt, dass einige Logs während Peaks verloren gehen können, was Nerdlog durch seine einfache Dateiansatzstrategie vermeidet. Die Wahl zwischen Logdateien und journalctl bietet hier Anwendern je nach Infrastruktur und Performance-Anforderungen maximale Flexibilität.
Benutzerfreundlichkeit und Betrieb Ein weiterer Pluspunkt von Nerdlog ist der geringe Bedarf an Setup und laufender Wartung. Die Lösung benötigt keine zentrale Komponente, keine eigene Datenbank oder komplexe Konfiguration auf den Hosts. Der Agent besteht aus einem simplen Bash-Skript, das bei Bedarf auf Remote-Systemen temporär erstellt und ausgeführt wird – es greift auf im System vorinstallierte Tools zurück und braucht keine Zusatzsoftware. Die Terminal-UI ist für Entwickler und Systemadministratoren gleichermaßen geeignet, bietet schnelles Navigieren durch Logs mit Tastaturkürzeln und hat dank der Echtzeit-Timeline-Histogramme eine exzellente Übersichtsfunktion eingebaut. Echte Praxiserfolge In Tests mit einem Cluster von über 20 Hosts und mehr als 2-3 Millionen Logzeilen pro Stunde konnte Nerdlog eine Abfragezeit von unter 2 Sekunden erreichen und die Performance damit nicht nur mit Graylog, sondern deutlich übertreffen.
Neben der Geschwindigkeit überzeugte Nerdlog auch durch Verlässlichkeit – keine Ausfälle und keine verlorenen Nachrichten, wie es in anderen SLAs gelegentlich vorkommt. Diese Kombination macht Nerdlog ideal für viele reale Szenarien, bei denen Entwickler und Systembetreuer schnell und einfach auf Logs zugreifen müssen, ohne sich durch umfangreiche Web-Schnittstellen kämpfen zu müssen oder komplizierte Wartungsprozesse zu etablieren. Erweiterungsmöglichkeiten und Zukunftsaussichten Aktuell besteht noch Verbesserungsbedarf hinsichtlich parsing-spezifischer Anpassungen. Nerdlog bietet bereits Grundfunktionen zur Aufschlüsselung von Standardfeldern aus Logzeilen, lässt jedoch noch keine flexible, anwenderspezifische Extraktion weiterer Werte zu. Die Integration von Lua-Skripten zur kundenspezifischen Analyse ist ein geplanter Schritt, der zukünftige Anpassungen erleichtern wird.
Auch weiterführende Statistiken, wie „Quick Values“ à la Graylog, die eine statistische Analyse der häufigsten Log-Muster ermöglichen, sollen bald realisiert werden. Diese Features werden Nerdlog aufwerten, ohne die grundlegende Philosophie von Minimalismus und Performance zu gefährden. Fazit Nerdlog zeigt eindrucksvoll, dass ein schlankes, auf bewährten UNIX-Tools basierendes Log-Management selbst großen Anforderungen standhalten kann. Ohne komplexe Infrastruktur bietet es schnelle Abfragen, hohe Zuverlässigkeit und Benutzerfreundlichkeit. Für viele Szenarien ist es eine echte Alternative zu schweren Systemen mit hohen Betriebskosten.
Mit weiterhin geplanter funktionaler Erweiterung, aber gleichbleibendem Fokus auf Einfachheit, bleibt Nerdlog eine spannende Lösung für professionelle Anwender, die eine transparente, performante und unkomplizierte Log-Analyse wünschen. In einer Welt voller überzentralisierter und komplexer Tools beweist Nerdlog, dass weniger oft mehr ist – und dass ein einfacher SSH-Zugriff auf Logdateien kombiniert mit smarter Filterung fundamental effektiv sein kann.


![How to Build a Smartwatch: Picking a Chip [video]](/images/2ED1841B-8757-4D60-88B8-25B749EA083D)