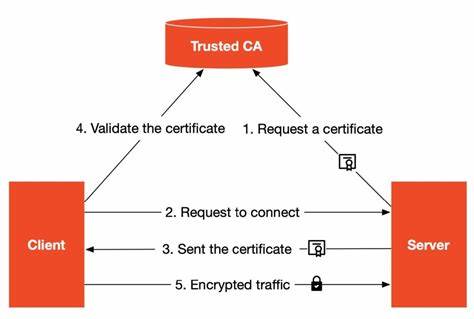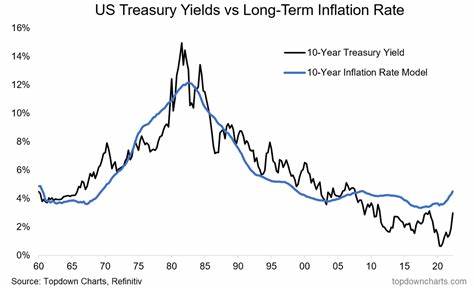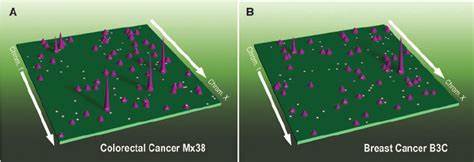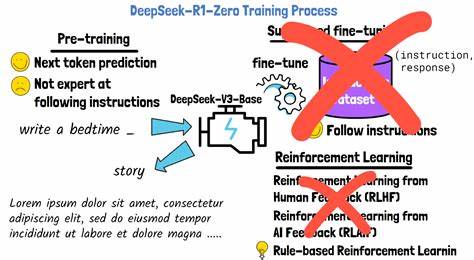
Reinforcement Learning (RL), zu Deutsch Verstärkendes Lernen, hat sich in den letzten Jahren zu einer der revolutionärsten Techniken im Bereich der künstlichen Intelligenz entwickelt. Viele der beeindruckendsten KI-Erfolge stammen aus der Anwendung von RL, insbesondere in Bereichen wie Spielen, Robotik und autonomem Fahren. Dennoch klafft oft eine Lücke zwischen dem theoretischen Potenzial von RL und der Praxis seiner Anwendung. Hier setzt das Konzept des End-to-End Reinforcement Learning Post-Training an und verspricht, die Entwicklung von KI-Modellen nachhaltiger, schneller und flexibler zu gestalten. Das traditionelle RL-Verfahren zeichnet sich durch eine oft komplexe Pipeline aus, die verschiedene Phasen voneinander trennt: Datensammlung, Modelltraining, Evaluation und anschließende Optimierungen.
Dieser Prozess bringt seine eigenen Herausforderungen mit sich, darunter hoher Rechenaufwand, zeitintensive Implementierungen und eine Vielzahl an Hyperparametern, die feinjustiert werden müssen. Für Entwickler entsteht dadurch eine merkliche Trägheit, die das Vorankommen des Projektes und die praktische Umsetzung oft verzögert. End-to-End RL Post-Training möchte genau hier ansetzen, um die Pipeline zu vereinfachen und den Weg von der Datenaufnahme bis zum finalen Modell zu verkürzen. Das Besondere am End-to-End Ansatz ist, dass sämtliche Schritte entlang des RL-Prozesses nahtlos miteinander verbunden sind und durch eine einzige optimierende Routine begleitet werden. Der Vorteil liegt darin, dass die einzelnen Bestandteile nicht isoliert voneinander betrachtet werden, sondern im Zusammenspiel stetig anpassen und verbessern - ähnlich einem biologischen Lernprozess.
So kann das Modell effizienter an komplexe Umgebungen und Aufgabenstellungen angepasst werden, da es sich kontinuierlich weiterentwickelt. Mit der Einführung von Post-Training Techniken im RL-Bereich ergibt sich zudem die Möglichkeit, bereits vortrainierte Modelle weiter zu spezialisieren und auf neue Herausforderungen zuzuschneiden, ohne diese vollständig von Grund auf neu trainieren zu müssen. Dies spart nicht nur erhebliche Rechenressourcen, sondern ermöglicht auch eine schnellere Anpassung an spezifische Use Cases. Insbesondere Anwendungen, bei denen die Umgebungsbedingungen sich dynamisch ändern oder nur begrenzte Daten vorhanden sind, profitieren enorm von diesem Ansatz. Darüber hinaus fördert End-to-End RL Post-Training eine engere Integration von verschiedenen Komponenten wie Sensorik, Kontrollmechanismen und Entscheidungslogiken.
Beispielsweise kann in autonomen Systemen die Verarbeitung von Sensordaten direkt mit der Aktuatorsteuerung gekoppelt werden, was zu einer präziseren Umsetzung von Handlungsstrategien führt. Solche Systeme lernen dadurch, ihre Aktionen unter realitätsnahen Bedingungen optimal zu gestalten. Ein weiterer entscheidender Aspekt ist die Benutzerfreundlichkeit. Viele Entwickler empfanden den Wechsel von traditionellen Methoden wie beispielsweise Prompt Engineering, das in der Verarbeitung natürlicher Sprache genutzt wird, hin zu leistungsfähigeren RL-Modellen als einschüchternd. End-to-End RL Post-Training verspricht, diese Barrieren zu minimieren, indem es die Komplexität des Trainingsprozesses reduziert und die Einstiegshürden verringert.
Dadurch wird der Spaß am Entwickeln von RL-Anwendungen wieder spürbar erhöht, was wiederum Innovationen beschleunigt. Die technische Umsetzung basiert häufig auf modernen Frameworks, die parallelisierte Rechenkapazitäten und automatisierte Hyperparameteroptimierung unterstützen. Durch Cloud-Computing und spezialisierte Hardware können Trainingszeiten drastisch verkürzt werden, was auch kleinen Teams oder Einzelerfindern den Zugang zu hochentwickelten RL-Lösungen ermöglicht. Dies trägt maßgeblich dazu bei, dass RL-Anwendungen breiter eingesetzt werden und somit das Machine-Learning-Ökosystem weiter wächst. Die Zukunft des End-to-End Reinforcement Learning Post-Trainings sieht besonders vielversprechend aus vor dem Hintergrund zunehmender Anforderungen an KI-Systeme in der Industrie, Forschung und sogar im Alltag.
Anwendungen, die ein hohes Maß an Autonomie, Anpassungsfähigkeit und Effizienz benötigen, wie intelligente Fertigungsanlagen, Smart Cities oder assistierende Technologien, können von dieser Methodik enorm profitieren. Gerade die Fähigkeit, sich an unvorhergesehene Situationen zu gewöhnen und schnell zu lernen, macht diese RL-Strategie zu einem unverzichtbaren Werkzeug. Aus der Perspektive der Forschung eröffnet End-to-End RL Post-Training spannende neue Möglichkeiten, um komplexe Umgebungen zu simulieren, Lernverläufe besser zu verstehen und Modelle transparenter zu gestalten. Die Kombination von Theorie und praktischer Anwendung schafft so einen Nährboden für Fortschritt, der weit über traditionelle Trainingsansätze hinausgeht. Abschließend lässt sich festhalten, dass End-to-End Reinforcement Learning Post-Training eine elegante Lösung für viele der Herausforderungen darstellt, die den Weg von KI-Systemen bisher erschwert haben.
Es verbindet Effizienz mit Flexibilität, bietet eine bessere Benutzererfahrung und öffnet die Tür für vielfältige Innovationsfelder. Entwickler, Unternehmen und Forscher sollten diesen Trend aufmerksam verfolgen und die Potenziale für ihre eigenen Projekte ausloten, um im dynamischen Feld der Künstlichen Intelligenz weiterhin erfolgreich zu agieren.