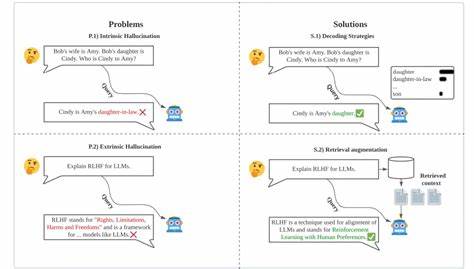
Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat die Art und Weise, wie wir mit künstlicher Intelligenz interagieren, revolutioniert. Sie ermöglichen natürliche Sprachverarbeitung, komplexe Datenanalysen und vielfältige Anwendungen im Alltag wie auch in Unternehmen. Doch gleichzeitig steigt die Sorge um Datenschutz, Sicherheit und Kontrolle über die eigenen Daten. Genau hier setzt das Konzept der End-to-End Private LLM Inferenz an, das eine sichere, vertrauliche und zugleich leistungsfähige Nutzung von KI-Modellen gewährleistet. Private LLM Inferenz bedeutet im Kern, dass Anfragen an große Sprachmodelle nicht in einer öffentlichen Cloud oder bei Drittanbietern verarbeitet werden, sondern innerhalb eines geschützten Enklavenumfelds stattfinden.
Diese Technik stellt sicher, dass sensible Daten niemals außerhalb des kontrollierten Bereichs gelangen, Manipulationen ausgeschlossen sind und die Nutzer die vollständige Kontrolle über ihre Daten behalten. In Kombination mit modernster Hardware-Sicherheit und Verifikationstechnologien wird so ein hohes Maß an Datenschutz und Compliance erreicht. Ein Vorreiter in diesem Bereich ist die Plattform Tinfoil, die es erlaubt, mit LLMs privat und gleichzeitig nahtlos über bekannte OpenAI API-Standards zu interagieren. Entwicklern und Unternehmen bietet dies enorme Vorteile, da bestehende Anwendungen und Integrationen ohne großen Aufwand auf eine sichere Infrastruktur migriert werden können. Die Kompatibilität mit populären Programmiersprachen wie Python, Node.
js, Swift und Go erlaubt eine flexible Implementierung in unterschiedlichsten Softwareprojekten. Die Funktionsweise von Tinfoil basiert auf der Nutzung sogenannter Enklaven - isolierter, geschützter Bereiche in der Computerhardware, die kryptografisch abgesichert sind. Diese Enklaven garantieren, dass die Daten während der Verarbeitung absolut vertraulich bleiben. Sollte eine Verifikation der Enklave fehlschlagen, wird die Anfrage sofort blockiert, was zusätzliche Sicherheit gegen Angriffe oder Fehlkonfigurationen bietet. Dadurch können Unternehmen vertrauensvoll ihre sensiblen Daten für KI-gestützte Analysen und automatisierte Entscheidungsfindungen verwenden.
Neben der Sicherheit überzeugt Tinfoil mit einem umfangreichen Portfolio leistungsstarker Modelle. Beispielsweise steht der DeepSeek R1 70B (Llama Distill) zur Verfügung, ein Modell mit 70,6 Milliarden Parametern und einer beeindruckenden Kontextlänge von 64.000 Tokens. Dieses Modell zeichnet sich durch herausragende Performanz im Bereich komplexer logischer Schlussfolgerungen und Sprachverarbeitung aus. Es eignet sich ideal für anspruchsvolle Unternehmensanwendungen, bei denen große Datenmengen und lange Kontexte analysiert werden müssen.
Darüber hinaus bietet Tinfoil Modelle wie Mistral Small 3.1 24B, das mit erweitertem multimodalem Verständnis und einer Kontextlänge von bis zu 128.000 Tokens überzeugt. Diese Fähigkeit, neben rein textuellen auch visuelle Informationen zu verarbeiten, eröffnet ganz neue Möglichkeiten in Bereichen wie automatisierter Bildanalyse, multimodaler Chatbots oder erweiterten Assistenzsystemen. Nicht zu vergessen ist Llama 3.
3 70B, ein multilingual ausgerichtetes Modell, das speziell für den Einsatz in global agierenden Unternehmen optimiert wurde. Die Fähigkeit, verschiedene Sprachen und kulturelle Kontexte zu verstehen und präzise darauf zu reagieren, macht es zum idealen Werkzeug für internationalen Kundensupport, mehrsprachige Content-Erstellung und globale Datenanalyse. Sicherheit und Moderation sind mit Modellen wie Llama Guard 3 1B abgedeckt, die sich speziell auf die Erkennung und Filterung unangemessener Inhalte konzentrieren. Dies ist besonders wichtig, um Risiken in der öffentlichen Kommunikation zu minimieren und die Einhaltung regulatorischer Vorgaben zu gewährleisten. Für Anwendungen im Bereich Audio- und Sprachverarbeitung steht das Whisper Large V3 Turbo Modell zur Verfügung, das für fortschrittliche Spracherkennung und präzise Transkriptionen entwickelt wurde.
Neben der reinen Modellauswahl bietet Tinfoil auch Werkzeuge zur nahtlosen Integration und Nutzung, wie zum Beispiel die Tinfoil Client Libraries. Die Installation und Anwendung dieser Tools sind bewusst einfach gestaltet, sodass Entwickler ohne große technische Hürden direkt von den Vorteilen der privaten LLM-Inferenz profitieren können. Mit wenigen Zeilen Code kann eine sichere Verbindung hergestellt und die Anfrage an das gewünschte Modell gestellt werden. Die breite Unterstützung von Programmiersprachen und sogar CLI-Zugriff eröffnet vielfältige Einsatzszenarien in modernen Entwicklungsumgebungen. So lassen sich sichere KI-Funktionalitäten auch in bestehende Workflows und DevOps-Prozesse integrieren.
Das erhöht die Flexibilität und sorgt für schnelle Time-to-Market bei neuen Produkten und Dienstleistungen. Im Kontext zunehmender Datenschutzbestimmungen wie der DSGVO in Europa gewinnt die private End-to-End Inferenz immer mehr an Bedeutung. Unternehmen müssen sicherstellen, dass persönliche und geschäftsrelevante Daten nicht unkontrolliert weitergegeben oder verarbeitet werden. Die von Tinfoil realisierte Technologie stellt dabei einen technologischen Meilenstein dar, der sowohl regulatorische Anforderungen erfüllt als auch höchste Sicherheit bei der Nutzung von Künstlicher Intelligenz gewährleistet. Zusätzlich profitieren Nutzer von der hohen Leistungsfähigkeit der LLMs, die eine Vielfalt von Anwendungen abdecken: von automatisierten Chatbots und virtuellen Assistenten über Textgenerierung und -analyse bis hin zu komplexen Entscheidungsunterstützungssystemen.
Die Fähigkeit, selbst große Kontexte zu verarbeiten, macht es möglich, auch umfangreiche Dokumente, Dialoge oder multimodale Daten effektiv zu analysieren und entsprechend zu reagieren. Die Kombination aus sicherer Enklaven-Technologie, leistungsfähigen Modellen und einfacher Integration zeigt, wie End-to-End Private LLM Inferenz die Grundlage für die nächste Generation von KI-Lösungen bildet. Unternehmen erhalten dadurch die Möglichkeit, KI in sensiblen Bereichen zu nutzen, ohne Kompromisse bei Datenschutz, Compliance oder Performance eingehen zu müssen. Mit Blick auf die Zukunft sind weitere Innovationen in diesem Bereich zu erwarten. Dazu gehören noch größere und leistungsfähigere Modelle, verbesserte Unterstützung multimodaler Daten und noch intuitivere Nutzerschnittstellen.
Plattformen wie Tinfoil werden dabei eine Schlüsselrolle spielen, indem sie diesen Fortschritt auf sichere und vertrauenswürdige Weise für Unternehmen und Entwickler weltweit zugänglich machen. Private LLM Inferenz steht damit nicht nur für eine technische Lösung, sondern für einen Paradigmenwechsel im Umgang mit Künstlicher Intelligenz. Sie ermöglicht es, das Potenzial großer Sprachmodelle voll auszuschöpfen und gleichzeitig höchste Ansprüche an Datenschutz und Sicherheit zu erfüllen – eine Kombination, die gerade in der heutigen datengetriebenen Welt unverzichtbar ist. Unternehmen, die bereits heute auf private LLM-Inferenz setzen, verschaffen sich einen entscheidenden Wettbewerbsvorteil. Sie können ihre Daten schützen, innovative KI-Anwendungen entwickeln und gleichzeitig das Vertrauen ihrer Kunden und Partner stärken.
Die Integration in bestehende OpenAI-API-Standards erleichtert zudem die Adoption und senkt Barrieren für den Einsatz moderner KI-Technologien. Insgesamt markiert End-to-End Private LLM Inferenz einen Meilenstein in der sicheren und effizienten Nutzung von Künstlicher Intelligenz. Sie eröffnet neue Perspektiven für alle Branchen und zeigt, wie technische Exzellenz und Datenschutz Hand in Hand gehen können, um zukunftsfähige, vertrauenswürdige KI-Lösungen zu schaffen.