In modernen verteilten IT-Umgebungen ist die Koordination von Prozessen und Ressourcen eine komplexe Herausforderung. Google begegnet diesem Problem mit Chubby, einem spezialisierten Lock-Dienst, der zuverlässige Sperrmechanismen für verteilte Systeme bereitstellt. Chubby spielt eine zentrale Rolle in verschiedenen Google-internen Anwendungen, wie dem Google File System (GFS) und BigTable, wo es als Fundament für konsistente und koordinierte Abläufe dient. Die Grundidee hinter Chubby ist, Entwicklern eine relativ einfache Möglichkeit zu bieten, Konflikte bei der Ressourcennutzung zu vermeiden und Systeme effektiv zu orchestrieren, ohne sich in der Komplexität klassischer Konsensverfahren zu verlieren. Chubby ist kein Dienst, der auf hohe Transaktionsrate oder extrem häufige Lock-Anfragen ausgelegt ist.
Vielmehr spezialisiert er sich auf sogenanntes grobkörniges Locking – Situationen, in denen Sperren über längere Zeiträume gehalten werden, oft für Stunden oder gar Tage. Dieses Einsatzprofil macht Chubby besonders geeignet für Aufgaben wie die Wahl eines Masters oder die Koordination von wenigen kritischen Ressourcen in einer verteilten Umgebung. Die Grundidee hinter Chubby beruht darauf, eine einfache, robuste und skalierbare Sperr- und Benachrichtigungsinfrastruktur bereitzustellen, die auf umfangreiche Client-Zahlen ausgelegt ist, jedoch eine moderate Anzahl von Transaktionen pro Sekunde verarbeiten muss. Ein zentrales Designprinzip von Chubby ist die Kombination von Locking-Mechanismen mit einer Dateisystem-ähnlichen Schnittstelle. Chubby bietet eine Dateisystem-Namensstruktur an, bei der Dateien und Verzeichnisse als "Knoten" bezeichnet werden.
Diese Knoten können dauerhaft oder flüchtig (ephemeral) sein. Flüchtige Knoten verschwinden automatisch, wenn der Client, der sie hält, keine Verbindung mehr zum Dienst aufrechterhält. Dadurch lassen sich beispielsweise temporäre Sperren einfach darstellen. Zugriffe auf diese Knoten können im exklusiven Schreibmodus oder im komplementären Lesemodus erfolgen, womit verschiedene Stufen des Zugriffs auf Ressourcen modelliert werden können. Die interne Architektur von Chubby setzt auf eine Replikation und eine Master-Wahl mittels des bewährten Paxos-Konsensprotokolls.
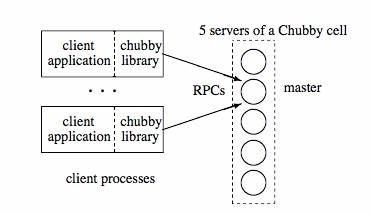
Innerhalb eines Chubby-Clusters gibt es mehrere Replikate, wovon stets eines als Master agiert. Dieser Master übernimmt die Verantwortung für die zentrale Steuerung und Vergabe von Sperren. Um seine Rolle konsistent auszufüllen, erhält der Master von den anderen Replikaten eine sogenannte Lease, die ihm für eine bestimmte Zeitspanne exklusiven Zugriff auf den Cluster zusichert. Fällt der Master aus, löst ein erneutes Paxos-Protokoll die Wahl eines neuen Masters aus, wodurch hohe Verfügbarkeit und Ausfallsicherheit gewährleistet werden. Clients, die mit Chubby interagieren, greifen über spezielle Client-Bibliotheken auf den Dienst zu.
Um den aktuellen Master zu finden, orientieren sich die Clients an DNS-Abfragen, welche sie auf das jeweils aktive Master-Replikat umleiten. Nach Etablierung dieser Verbindung führen die Clients Locking-Operationen aus und registrieren sich für Ereignisse, um Benachrichtigungen bei Änderungen oder Failover-Situationen zu erhalten. Diese enge Kopplung zwischen Client und Server steigert die Effizienz und Zuverlässigkeit der Koordination. Ein großes Problem bei verteiltem Locking besteht darin, wie mit abgestürzten oder nicht reagierenden Anwendungen umgegangen werden soll, die eine Sperre halten. Chubby begegnet diesem Problem mit intelligenten Mechanismen wie Lock-Delays und Sequenznummern.
Lock-Delays definieren eine Wartezeit, bevor ein vermeintlich verlorener Lock an einen anderen Client vergeben wird, wodurch inkonsistente Zustände vermieden werden. Die Sequenzmechanismen ermöglichen es Anwendungen, die Gültigkeit einer Sperre auch nach Wartezeiten und Failures eindeutig zu überprüfen. So kann sichergestellt werden, dass keine überschneidenden oder veralteten Zugriffe stattfinden. Ereignisse und Benachrichtigungen spielen bei Chubby ebenfalls eine gewichtige Rolle. Über sogenannte Callbacks können sich Clients Informationen über Veränderungen an Knoten, Master-Failover oder Änderungen im Systemzustand holen.
Diese Ereignisbenachrichtigung verleiht Chubby zusätzlich Aspekte eines Publish-Subscribe-Systems und unterstützt die Entwicklung reaktiver und robuster Anwendungen. Chubby stellt eine robuste Grundlage für komplexe Aufgaben wie die Master-Wahl in verteilten Systemen bereit. Ein typisches Verfahren sieht dabei vor, dass alle Kandidaten einen bestimmten Knoten im exklusiven Schreibmodus öffnen wollen. Nur der Erste, der das schafft, gilt als aktueller Master, während die anderen diese Information über die Änderungen im System erhalten und entsprechend reagieren können. Die Kombination aus Locking, Sequenzen und Benachrichtigungen erlaubt es, auch in komplexen Szenarien die Konsistenz und Stabilität der Anwendung zu gewährleisten.
Ein weiteres Merkmal von Chubby ist das konservative Caching auf Client-Seite. Clients halten lokal zwischengespeicherte Daten bereit, die im Normalbetrieb für schnellere Zugriffe sorgen und dabei stets konsistent zu den aktuellen Zuständen auf dem Server gehalten werden. Bei Änderungen blockiert Chubby gezielt Clients, die Daten aktualisieren, bis alle Cache-Invalidierungen erfolgreich an alle betroffenen Clients verteilt und bestätigt wurden. Dieses rigorose Cache-Kohärenzmodell ermöglicht einerseits Performance-Gewinne und sichert gleichzeitig die Verlässlichkeit der Daten. Verbindungen zwischen Clients und dem Chubby-Master werden über sogenannte KeepAlive-RPCs aufrechterhalten.
Diese Aufrufe sind entscheidend für das Zustandsmanagement und helfen bei der Erkennung von Ausfällen und Session-Verlusten. Fällt der Master aus oder verliert ein Client seine Lease, rücken beide Seiten automatisiert in einen sogenannten „Gefährdungszustand“ (jeopardy), während dessen die Anwendung gewarnt wird und passende Maßnahmen einleiten kann. Der Failover-Prozess bei einem Master-Ausfall läuft bei Chubby äußerst strukturiert ab. Nach Erkennung des Serverausfalls startet das Paxos-Protokoll eine neue Masterwahl. Clients erkennen anhand der Lease- und KeepAlive-Timeouts die wechselnde Situation und stellen sich darauf ein.
Der neue Master reconstructiert seine Zustände aus der persistenten Datenbank, bevor er weitere Anfragen erlaubt. Parallel informiert er die Clients über das Failover, sodass diese ihre lokalen Zustände aktualisieren und Inkonsistenzen vermeiden können. Bei all diesen komplexen Abläufen achtet Chubby darauf, maximale Zuverlässigkeit bei gleichzeitig überschaubarer Komplexität im Client-Code zu gewährleisten. Die Locking-APIs und die Dateisystem-ähnlichen Eigenschaften bieten Entwicklern eine intuitive Schnittstelle, die sich problemlos in eine Vielzahl von Anwendungen integrieren lässt. Durch die zentrale Architektur und die standardisierte Semantik werden aufwändige Konsensmechanismen oft überflüssig, insbesondere dort, wo Locking die natürliche Lösung für Koordination ist.
Die Wahl, auf einen zentralen Lock-Service anstelle eines rein verteilten Konsens-Frameworks wie Paxos zu setzen, beruht auch auf praktischen Entwicklerüberlegungen. Locking ist weithin bekannt und gut strukturierbar für Entwickler, besonders wenn Anwendungen wachsen und zunehmend koordinationspflichtige Komponenten erhalten. Zudem können Locking-Mechanismen kleine Datenmengen konsistent speichern und bieten gleichzeitig Event-basierte Benachrichtigungen, was den Entwicklungsaufwand reduziert und die Wartbarkeit erhöht. Zusammenfassend lässt sich sagen, dass Chubby ein Schlüsselelement für verteilte Koordination im Google-Ökosystem ist, das eine Kombination aus verlässlichem Locking, Ereignisbenachrichtigungen, Cache-Kohärenz und robuster Failover-Unterstützung bietet. Seine Architektur und Designentscheidungen spiegeln die hohen Anforderungen großer vernetzter Systeme wider und zeigen, wie komplexe technische Herausforderungen durch intelligente Konzepte elegant gelöst werden können.
Die durchdachte Balance zwischen Komplexität, Zuverlässigkeit und Nutzbarkeit macht Chubby zu einem wegweisenden Beispiel für verteilte Koordinationsdienste, von denen auch andere Unternehmen und Projekte lernen können.