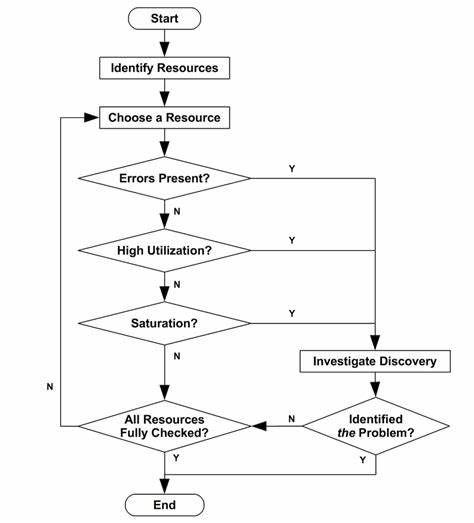
Die Leistungsfähigkeit von Computersystemen ist entscheidend für den reibungslosen Betrieb moderner Unternehmen und Anwendungen. Doch bei auftretenden Performance-Problemen stellt sich oft die Frage, wo die Ursache liegt und wie man möglichst schnell eine Lösung findet. Hier setzt die USE-Methode an, eine systematische Vorgehensweise zur Analyse der Hardware- und Software-Ressourcen, die dabei hilft, Engpässe und Fehlerquellen rasch zu identifizieren. Die Abkürzung USE steht für Utilization (Auslastung), Saturation (Sättigung) und Errors (Fehler) – drei zentrale Kenngrößen, die jeder Systemadministrator oder Performance-Analyst kennen sollte. Dabei richtet sich die Methode gleichermaßen an Anfänger wie an erfahrene Profis, die schnell eine Übersicht über den Systemzustand erhalten wollen.
Die USE-Methode ist dabei nicht auf ein spezielles Betriebssystem beschränkt, sondern lässt sich auf Linux, Solaris, Mac OS X, FreeBSD und weitere Umgebungen anwenden. Sie ist vergleichbar mit einer Notfall-Checkliste aus der Luftfahrttechnik – einfach, umfassend und schnell anzuwenden. Der Kern der Methode besteht darin, für jede Systemressource diese drei Metriken systematisch zu überprüfen. Dabei definiert die Auslastung den Anteil der Zeit, in der eine Ressource aktiv arbeitet. Die Sättigung zeigt auf, wie sehr eine Ressource durch Warteschlangen oder zusätzliche Anfragen überlastet ist.
Fehler wiederum umfassen alle problematischen Events, die den Betrieb beeinträchtigen können, auch wenn sie kurzfristig kompensiert werden. Der größte Vorteil der USE-Methode besteht darin, dass sie mögliche Ursachen nicht nur anhand von vorgegebenen Kennzahlen eingrenzt, sondern durch gezieltes Fragen ein vollständiges Bild des Systems erstellt. Man beginnt mit einer Bestandsaufnahme aller relevanten Komponenten und ermittelt dann die drei Kenngrößen, um die kritischsten Engpässe zu erkennen. Für Serversysteme beinhaltet das zum Beispiel CPU-Kerne, Speicher, Netzwerk- und Speicherschnittstellen sowie die Cockpits anderer Hardwarekomponenten wie Controller oder Busse. Auch Software-Ressourcen wie Threadpools oder Mutex-Locks können in die Analyse einbezogen werden, sofern sie relevante Kennzahlen liefern.
Ein wesentlicher Punkt dabei ist, dass die USE-Methode aufzeigt, wo Wissen fehlt – sogenannte bekannte Unbekannte – und so vermeidet, dass blinde Flecken die Fehlersuche behindern. Dies ist insbesondere in komplexen oder virtuellen Umgebungen ein großer Vorteil. Die Auslastung wird meist in Prozent über eine bestimmte Zeitspanne gemessen. Es ist jedoch wichtig zu beachten, dass eine niedrige Durchschnittsauslastung nicht zwingend bedeutet, dass das System nicht überlastet ist. Kurzfristige Spitzenlasten können zu Sättigungen führen, die sich in klassischer Überwachung oft nicht sofort zeigen.
So kann beispielsweise die CPU über fünf Minuten im Durchschnitt nur zu 80 Prozent ausgelastet wirken, tatsächlich aber kurzfristige 100-Prozent-Spitzenbelastungen aufweisen, die die Systemreaktivität negativ beeinflussen. Die Sättigung wird vielfach als Länge der Warteschlange gemessen oder als Zeit, die Anfragen auf Verarbeitung warten müssen. Die Überprüfung auf Fehler umfasst eine Vielzahl von Events, von Hardware-Fehlermeldungen bis hin zu Software-Exception-Behandlungen. Dabei sind auch subtile Fehler wie wiederholte Operationen aufgrund von Fehlern relevant, die sich erst langfristig auf die Performance auswirken. Um mit der USE-Methode effektiv zu arbeiten, empfiehlt es sich, systematisch eine vollständige Ressourcenliste zu erstellen.
Diese beginnt oft mit der CPU, deren Kerne und Threads, über den Arbeitsspeicher und dessen Kapazität, bis hin zu Netzwerkschnittstellen und Speichermedien. Der Blick auf wichtige Controller und Busse öffnet zusätzliche Perspektiven, die in der Praxis häufig übersehen werden, obwohl sie zentrale Engpässe sein können. Eine weitere hilfreiche Vorgehensweise ist das Zeichnen eines funktionalen Blockdiagramms. Dieses zeigt nicht nur die einzelnen Komponenten, sondern auch deren Verbindungen und den Datenaustausch. So lassen sich Flaschenhälse besser lokalisieren und die Auswirkungen auf das Gesamtsystem verstehen.
Für komplexe Systeme ist dies eine sehr sinnvolle Ergänzung zur reinen Messung von Kennzahlen. Neben der einfachen Punktebeurteilung bietet die USE-Methode auch diagnostische Deutungen an. So deutet eine dauerhafte CPU-Auslastung von 100 Prozent in der Regel auf eine Überlastung hin, bei der direkte Maßnahmen erforderlich sind. Bei Speicherkapazitäten sollte die Nutzung nicht dauerhaft nahe der Grenzwerte sein, um Paging und Leistungsverluste zu vermeiden. Sättigung in Speichersystemen können sich durch Warteschlangen bei I/O-Anfragen zeigen, die zu wahrnehmbaren Verzögerungen führen.
Fehlerwerte, die kontinuierlich zunehmen, zeigen an, dass ein Fehler dauerhaft vorhanden ist und untersucht werden muss. Besonders relevant ist die Methode auch für Cloud-Umgebungen, wo oft diverse Ressourcenkontrollen wie Container-Limits, Hypervisor-Beschränkungen oder Netzwerk-Drosselungen wirken können. Hier lassen sich mit der USE-Methode sowohl physische als auch virtuelle Ressourcen gleichermaßen bewerten und so Engpässe in der Zuweisung sichtbar machen. Die USE-Methode richtet sich vor allem an Systemadministratoren und Performance-Analysten, die zu Beginn einer Untersuchung schnell eine umfassende Übersicht über die Systemressourcen erhalten möchten. Sie verhindert, dass wichtige Aspekte übersehen werden, und liefert so eine solide Grundlage für weitere, detailliertere Analysen.
Dabei ergänzt sie andere Methoden, die sich auf Latenzen, Datenbankoperationen oder spezifische Applikationen konzentrieren. Durch ihre Einfachheit und Schnelligkeit ist die USE-Methode ein unverzichtbares Werkzeug, das in keiner professionellen Toolbox fehlen sollte. Zahlreiche Praxiseinsätze haben die Effektivität und Zuverlässigkeit bestätigt. Die Methode wurde zudem in Fachbüchern und Konferenzen präsentiert und wird kontinuierlich an neue Technologien und Betriebssysteme angepasst. So existieren bereits anwendungsspezifische Checklisten für Linux, Solaris, Mac OS X, FreeBSD und andere Plattformen.
Wer die USE-Methode zur Performance-Analyse anwendet, profitiert von einer systematischen, methodischen Herangehensweise, die komplexe Systeme in handhabbare Teilbereiche zerlegt. Der Fokus auf Auslastung, Sättigung und Fehler zeigt unverzüglich auf, wo der Handlungsbedarf am größten ist. Zudem wird durch die Dokumentation aller überprüften Bereiche verhindert, dass „blinde Flecken“ bleiben. Das macht die Methode nicht nur für Routine-Checks interessant, sondern auch für kritische Eskalationsstufen, bei denen schnelle Entscheidungen gefragt sind. Die USE-Methode wurde sogar auf unkonventionelle Systeme angewandt, etwa auf das Apollo Lunar Module aus den 1960er-Jahren, wobei daraus ersichtlich wurde, wie universell sich die Strategie einsetzen lässt.