Im Bereich der Softwareentwicklung spielt das Logging eine zentrale Rolle, wenn es darum geht, Programme zu überwachen, Fehler zu analysieren und die Leistung zu optimieren. Besonders bei der Programmiersprache Rust gewinnt die Bibliothek tracing immer mehr an Bedeutung, da sie moderne und flexible Möglichkeiten zur Ereignisverfolgung bietet. Im Unterschied zu klassischen Log-Systemen, die oft nur einfache Textnachrichten ausgeben, basiert tracing auf sogenannten Events und Spans, wodurch wesentlich detailliertere und strukturierte Informationen erzeugt werden können. Das rust-eigene Ökosystem setzt zunehmend auf tracing, da etwa der Compiler, Tokio und diverse Bibliotheken wie GraphQL ihre Protokollierungen darauf abstimmen. Dadurch wird klar, dass tracing als zukunftsweisendes Logging-Framework etabliert ist.
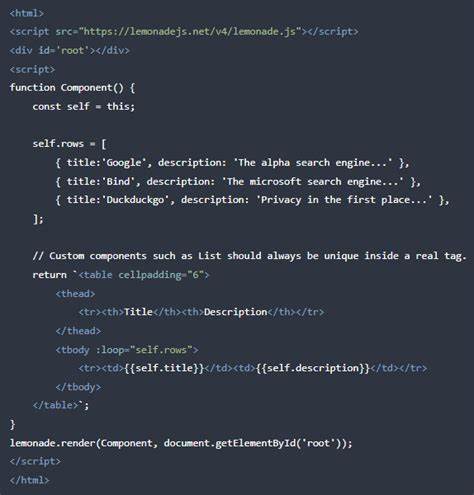
Dennoch ist die Standard-Ausgabeform der Bibliotheken zeitweise nicht immer optimal für jeden Anwendungsfall. Einige Entwickler empfinden das vorgefertigte JSON-Logging als nicht ganz passend, weshalb die Erstellung maßgeschneiderter Logger eine sinnvolle Alternative darstellt. Um einen eigenen Logger in Rust zu bauen, der perfekt auf die eigenen Bedürfnisse zugeschnitten ist, benötigt man vor allem ein Grundverständnis der Funktionsweise von tracing und tracing-subscriber. Diese beiden Bibliotheken bilden das Herzstück des gesamten Logging-Systems. tracing übernimmt die Erfassung von Ereignissen und Zeitspannen, während tracing-subscriber für die Verarbeitung und Ausgabe der Daten verantwortlich ist.
Ein maßgeschneiderter Logger kann daher durch Implementierung spezifischer Schichten, sogenannter Layer, realisiert werden, die auf bestimmte Events reagieren und diese in beliebiger Form ausgeben. Der erste Schritt besteht in der Installation der notwendigen Bibliotheken. In der Cargo.toml Datei müssen tracing, tracing-subscriber und serde_json als Abhängigkeiten mit angegeben werden, um das Konzept starten zu können. Die Verwendung von serde_json erleichtert vor allem die strukturierte Ausgabe in JSON-Format erheblich, was heutzutage häufig für Log-Auswertungen und Monitoring-Tools benötigt wird.
Im Grundgerüst einer Rust-Anwendung wird tracing-subscriber mit der selbst definierten CustomLayer verknüpft, wobei diese Layer in der Lage ist, die Events auszuwerten und nach eigenen Vorgaben zu verarbeiten. Die grundlegende Struktur der CustomLayer beruht dabei auf der Implementierung des Layer-Traits, der im crate tracing-subscriber definiert ist. Zu Beginn ist es ratsam, mit einer minimalen Implementierung zu starten, die allerdings erst einmal keine Events verarbeitet, sondern lediglich registriert wird. Das Resultat ist erwartungsgemäß, dass keine Ausgabe erfolgt, da noch keine Methode zur Ereignisverarbeitung überschrieben wurde. Wichtig ist an dieser Stelle zu verstehen, dass alle relevanten Logging-Daten während der Programmausführung in Form sogenannter Events generiert werden.
Ein Event ist vergleichbar mit einem einzelnen Log-Eintrag – sprich: eine Momentaufnahme eines bestimmten Vorgangs im Programm. Die Strategie ist deshalb, gezielt auf diese Events zu reagieren. Der Layer-Trait stellt hierfür die Funktion ‚on_event‘ zur Verfügung. Diese Methode wird aufgerufen, sobald ein Ereignis erfasst wird. Über das Event-Objekt lässt sich auf Metadaten wie den Schweregrad (Level), den Zielkontext (Target) und den Namen des Events zugreifen.
Außerdem kann man herausfinden, welche Felder (Fields) im Event enthalten sind. Ein erster Test mit println!-Ausgaben gibt den Überblick über die verfügbaren Informationen und bestätigt, dass die Datenstruktur Events sinnvoll ausgelesen werden kann. Doch nach einer Weile stößt man auf eine Einschränkung: Zwar sind alle Feldnamen sichtbar, aber die eigentlichen Werte bleiben zunächst verborgen. Dies liegt an der spezifischen Speicherstrategie von tracing. Events und Spans speichern nämlich keine Daten dauerhaft, sondern übergeben diese direkt zur Verarbeitung.
Um an die Werte heranzukommen, muss das Visitor-Pattern genutzt werden. Hierfür definiert man einen Besucher, der sämtliche Daten eines Events abgreift und verarbeitet. Dieser Besucher implementiert das Visit-Trait aus tracing::field und überschreibt für alle möglichen Datentypen wie Zahlen, Strings oder Booleans eine Methode zur Feldwertaufzeichnung. Durch diese Visitor-Implementierung lässt sich jedes Feld samt seinem Wert extrahieren und individuell weiterverarbeiten. Dieses Prinzip bildet die Grundlage, um aus Events strukturierte Datenobjekte zu bauen.
Ein Paradebeispiel dafür ist die Umsetzung eines JSON-Loggers, der die Eventdaten in ein gut lesbares und maschinenverarbeitbares JSON-Format überführt. Die Daten werden dabei in einer Baumstruktur mit BTreeMap gesammelt und anschließend mit serde_json zu JSON konvertiert. Diese elegante Lösung ermöglicht es, Logs nicht nur zur Laufzeit auszugeben, sondern auch in moderne Analyse- oder Monitoring-Systeme einzuspeisen. Die Ausgabe beinhaltet dabei nicht nur die Felder und Werte des Events, sondern auch Kontextinformationen wie das Log-Level, den Namen der Quelle und den Zielkontext. Dieser zusätzliche Kontext erhöht die Aussagekraft des Logs erheblich und erleichtert die spätere Analyse.
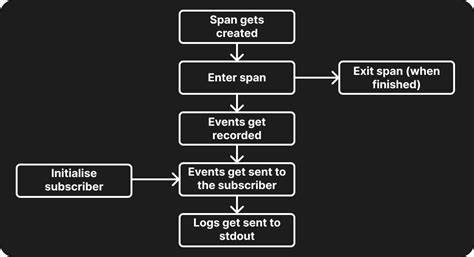
Ein solcher individueller Logger ist besonders dann wertvoll, wenn Standardlogger nicht die gewünschte Struktur oder Flexibilität bieten. Der eigene Layer ist flexibel und lässt sich leicht erweitern, etwa durch Filtern bestimmter Events, Anreicherung mit Zeitstempeln oder Anpassung des Ausgabeformats. Der modulare Aufbau von tracing erlaubt zudem die Kombination mehrerer Layer, womit sich unterschiedliche Log-Ausgaben parallel realisieren lassen. Neben der reinen Event-verarbeitung bietet tracing weiterführende Konzepte an, wie die Nutzung von Spans. Spans definieren Zeitabschnitte innerhalb des Programms, deren Beginn und Ende protokolliert werden.
Dadurch entsteht eine reichhaltige Struktur, mit der sich nicht nur Einzelereignisse, sondern zeitliche Abläufe nachvollziehen und analysieren lassen. Diese Form der strukturierten Protokollierung ermöglicht tiefergehende Einblicke sowie eine bessere Korrelation von Log-Daten. Insgesamt zeigt sich, dass tracing und tracing-subscriber in Kombination mit einer eigenen Layer-Implementierung vielfältige Möglichkeiten eröffnen, sämtliche Anforderungen an das Logging in Rust-Projekten professionell abzudecken. Die Kombination aus Flexibilität, Performance und einfacher Einbindung macht sie zu einer zukunftssicheren Wahl für neue Anwendungen. Entwickler, die sich intensiv mit den Konzepten von tracking und Visitor-Pattern beschäftigen, profitieren von einer transparenten und erweiterbaren Protokollierungslösung, die sich nahtlos in moderne Softwarearchitekturen integriert.
Damit wird nicht nur die Wartbarkeit verbessert, sondern auch die Qualität der Anwendung nachhaltig gesteigert. Wer komplexe Anwendungen mit mehreren Komponenten betreibt oder performant auf Fehler reagieren möchte, wird die Vorteile eines maßgeschneiderten Loggers schnell zu schätzen wissen. Die Rust-Community arbeitet zudem kontinuierlich daran, die tracing-Tools weiterzuentwickeln, sodass in Zukunft noch mehr Features und Optimierungen zu erwarten sind. Für den Start empfiehlt es sich, mit einer einfachen Event-Verarbeitung zu experimentieren und Schritt für Schritt weitere Funktionalitäten wie Spans und Filter einzubinden. So entsteht mit der Zeit ein robustes Logging-System, das perfekt auf die individuellen Anforderungen abgestimmt ist und tiefere Einblicke in den Programmablauf ermöglicht.
Zusammenfassend lässt sich festhalten, dass das selbst entwickelte Logging mit tracing und tracing-subscriber in Rust eine moderne und leistungsfähige Möglichkeit darstellt, um detaillierte und strukturierte Logs zu erzeugen. Der Weg vom einfachen Event-Auslesen hin zur Ausgabe in strukturierter JSON-Form zeigt das Potenzial der Bibliotheken und deren Anpassbarkeit. Dank dieser Werkzeuge lassen sich modernste Monitoring- und Analysekonzepte in Rust-Projekten realisieren und der Grundstein für eine nachhaltige Wartung und Optimierung legen.