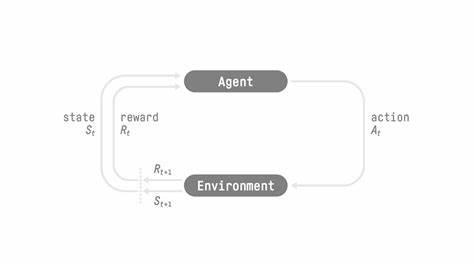
Reinforcement Learning (RL) hat sich als eine der vielversprechendsten Methoden zur Entwicklung intelligenter Agenten erwiesen, die komplexe Aufgaben eigenständig und adaptiv bewältigen können. Im Zentrum steht dabei die Fähigkeit eines Agenten, durch Versuch und Irrtum sowie durch Belohnungen aus der Umgebung zu lernen. Die wachsende Beliebtheit von RL in Forschung und Industrie hat zahlreiche Software Frameworks und Trainer hervorgebracht, die die Ausbildung dieser Agenten unterstützen. Doch trotz der beeindruckenden Fortschritte gab es bislang bedeutende Herausforderungen, die den praktischen Einsatz und die Leistungsfähigkeit einschränkten. Hier setzt das neue Open-Source Projekt ART an, das mit einem frischen Ansatz und innovativen Lösungen die Landschaft der RL-Trainingsframeworks revolutioniert.
ART steht für Agent Reinforcement Trainer und wurde von einem engagierten Team bei OpenPipe entwickelt. Das Ziel hinter ART war es, ein Framework zu schaffen, das die vielschichtigen Realitäten der Agentenausbildung besser abbildet, insbesondere dort, wo bisherige Ansätze an ihre Grenzen stießen. Viele der aktuell populären RL-Frameworks sind vor allem für relativ simple und lineare Belohnungsmodelle entworfen worden und zeigen Schwächen beim Training von Agenten, die sequentielle Entscheidungen in Multi-Turn-Szenarien treffen müssen. Gerade bei komplexen Aufgaben, die den Einsatz von mehrstufigen Strategien oder das kombinierte Nutzen verschiedener Werkzeuge erfordern, liegt die Schwäche bisheriger Systeme offen zutage. Ein oft genannter Defizitpunkt ist die mangelhafte Unterstützung von interaktiven Workflows, bei denen Agenten nicht nur einmalig eine Antwort generieren, sondern in einem Dialog oder einer mehrstufigen Aktion mehrere Schritte vollziehen müssen.
Die Fähigkeit, auf externe Werkzeuge zuzugreifen, deren Rückmeldungen erneut zu evaluieren und dann weiterführende, koordinierte Aktionen zu planen, ist für viele reale Anwendungsgebiete essenziell. ART wurde mit genau dieser Flexibilität im Fokus konzipiert. Dadurch lassen sich Agenten ausbilden, die weitaus komplexere Aufgaben bewältigen und sich dynamischer an neue Anforderungen anpassen. Ein weiteres zentrales Problem vieler bestehender Frameworks ist die suboptimale Nutzung modernster GPU-Hardware. Beim Training großer Sprachmodelle, wie sie im Bereich natürlicher Sprachverarbeitung immer mehr Anwendung finden, ist die effiziente Auslastung der GPU-Ressourcen entscheidend, um Trainingseinheiten in einem vertretbaren Zeit- und Kostenrahmen durchzuführen.
ART adressiert dieses Thema umfassend und nutzt optimierte Trainingsschemata, die auch während der sogenannten Rollout-Phase, in der der Agent Entscheidungen trifft und Daten generiert, die GPUs effizient auslasten. Das Ergebnis ist eine signifikante Steigerung der Durchsatzleistung und damit eine schnellere, ressourcenschonende Agentenausbildung selbst bei kleineren Modellen mit 7 Milliarden Parametern, die zuvor oft derart hohe Anforderungen an die Hardware gestellt hätten, dass sie nur mit mehreren High-End GPUs wie Nvidia H100 realisierbar waren. Ein wesentlicher Mehrwert von ART liegt zudem in seiner Schnittstellengestaltung. An Stelle starre und oftmals komplizierte Integrationsmechanismen zu verlangen, bietet ART eine OpenAI API-kompatible Endpunktarchitektur an. Das bedeutet, Entwickler können ART nahtlos als Drop-in-Alternative für zahlreiche bestehende proprietäre APIs nutzen.
Dadurch entfällt ein großer Teil der Anpassungsarbeit und die Flexibilität steigt maßgeblich. Ein nahtloser Austausch zwischen bestehendem Agentencode und der Trainingsumgebung gewährleistet eine durchgängige Praxisanwendbarkeit und beschleunigt den Entwicklungsprozess erheblich. Beim Training mit ART gestaltet sich die Belohnungslogik besonders anpassbar. Anders als bei Supervised Fine-Tuning (SFT), das auf das Lernen vorher definierter Ausgabesequenzen trainiert, fokussiert sich Reinforcement Learning auf die Optimierung einer definierten Belohnungsfunktion. Das heißt, anstatt dem Modell exakt vorzugeben, welche Ausgaben es zu liefern hat, lernt es, gute von schlechten Resultaten zu unterscheiden und seine Strategien entsprechend anzupassen.
Dies eröffnet zahlreiche Anwendungsmöglichkeiten, vor allem in Szenarien, in denen eine klare Lösung zwar messbar, aber nicht zwingend bekannt ist. Ein anschauliches Beispiel hierfür ist die Entwicklung eines Agenten, der als E-Mail-Forschungsassistent fungiert. Während es zwar einfach ist, den Erfolg anhand der Relevanz der gefundenen E-Mails zu bewerten, ist es deutlich schwieriger, den genauen Suchprozess vorzugeben. ART ermöglichte es, einen Agenten so zu trainieren, dass er eigenständig lernte, welche Schlüsselwörter am besten geeigneten Ergebnissen führen. Dieser Lernprozess basiert ausschließlich auf der Rückmeldung, ob das Ergebnis die Erwartungen erfüllt, ohne dass ein menschlicher Experte den Suchweg explizit definieren muss.
Die Community reagiert auf ART mit großem Interesse. Entwickler schätzen besonders die offene Struktur und den einfachen Zugang zum Framework, verbunden mit der Möglichkeit, es auf ihre individuellen Bedürfnisse zuzuschneiden. Die Möglichkeit, Modelle sukzessive mit eigenen Belohnungsfunktionen zu trainieren und den Prozess so lange zu wiederholen, bis eine zufriedenstellende Leistung erreicht wird, stellt ein kraftvolles Werkzeug dar. Ebenso wird die Transparenz im Trainingsprozess als großer Vorteil bewertet. Die API ermöglicht es, Trainingsfortschritte nahezu in Echtzeit nachzuvollziehen.
Für Entwickler bedeutet das, Fehlentwicklungen frühzeitig zu erkennen und gezielt gegenzusteuern. Obwohl die API-Endpunkte momentan noch weiterentwickelt werden, besteht bereits jetzt die Möglichkeit, Trainingszustände mittels Streaming von JSON-Daten zu verfolgen, was bei der Optimierung und Analyse des Trainingsprozesses hilft. Nicht zuletzt unterstreicht ART auch die Bedeutung von Open-Source im Bereich der KI-Entwicklung. Die freie Verfügbarkeit und die Einladung zur Community-Beteiligung schaffen einen Raum für eine schnelle Weiterentwicklung und gegenseitigen Wissensaustausch. Gerade auf dem Feld des Reinforcement Learning, das sowohl kompliziert als auch ressourcenintensiv ist, bietet ein gemeinsamer Austausch potenziell enorme Fortschritte in Qualität und Anwendbarkeit.
Die Zukunft von ART ist vielversprechend. Die Entwickler planen eine fortlaufende Verbesserung der API-Schnittstellen, besseren Support für noch komplexere Multi-Turn-Dialoge und noch effizientere Nutzung der verfügbaren Hardware. Dabei bleibt das Ziel, die Ausbildung von intelligenten Agenten so einfach und effektiv wie möglich zu gestalten. Für Unternehmen, die eigene maßgeschneiderte Agenten einsetzen möchten, bietet ART ein leistungsfähiges Werkzeug, um dieses Vorhaben realistisch und nachhaltig umzusetzen. Zusammenfassend stellt ART einen bedeutenden Schritt in der Entwicklung von Frameworks für Reinforcement Learning dar.
Indem es praktische Herausforderungen löst, die bisherige Lösungen einschränkten, eröffnet es neue Möglichkeiten für die Ausbildung hochperformanter und vielseitiger KI-Agenten. Die Kombination aus Offenheit, Flexibilität und Effizienz macht ART zu einer wertvollen Ressource für Entwickler, Forscher und Unternehmen, die sich auf dem zunehmend wettbewerbsintensiven Feld der KI weiter etablieren wollen.



![Eric Barone Talks Stardew Valley and Haunted Chocolatier [video]](/images/6C48A610-5A4F-4621-A6B5-37228636C43B)
