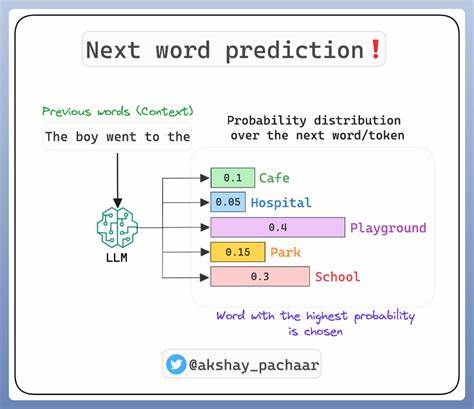
Die Bewertung von großen Sprachmodellen (Large Language Models, kurz LLMs) wird zunehmend komplexer, da klassische Bewertungsmechanismen an ihre Grenzen stoßen. Dabei spielt die präzisionsbasierte Stichprobenziehung eine entscheidende Rolle, um einerseits verlässliche Ergebnisse zu gewährleisten und andererseits die Kosten und den zeitlichen Aufwand bei der Evaluierung zu minimieren. Aufgrund der inhärenten Unsicherheit und Variabilität bei der Nutzung von LLMs als juristische oder qualitative Bewertungsexperten, ist ein fundiertes Verständnis und eine systematische Anwendung statistischer Verfahren von größter Bedeutung. LLM-Juroren oder Evaluatoren sind von Natur aus stochastisch, was bedeutet, dass bei wiederholten Bewertungen desselben Inputs unterschiedliche Resultate entstehen können. Ein exemplarisches Szenario zeigt, dass mehrere Bewertungen eines Sprachmodellausgangs in Form von Punktzahlen bezüglich Verständlichkeit, Qualität oder inhaltlicher Korrektheit variieren.
Diese Variabilität kann beispielsweise durch subjektive Unterschiede in der Interpretation der Bewertungsdimensionen, die Granularität der Skalen oder die inhärente Komplexität der Kriterien begründet sein. Ein wichtiger Schritt zur Gewährleistung zuverlässiger Ergebnisse ist die Erfassung ausreichender Stichprobengrößen, um den Mittelwert der Bewertungen mit hoher statistischer Sicherheit zu bestimmen. An dieser Stelle kommt die präzisionsbasierte Stichprobenziehung ins Spiel, welche sich auf die Berechnung von Konfidenzintervallen stützt und dynamisch die Anzahl der notwendigen Evaluationswiederholungen anpasst. Die Grundidee hinter der Methode ist, die Stichprobengröße so lange zu erhöhen, bis das halbseitige Konfidenzintervall jederzeit eine vorgegebene Genauigkeit erreicht. Die Breite dieses Intervalls beschreibt die Unsicherheit des geschätzten Mittelwerts, wodurch sich definieren lässt, wie präzise die endgültige Bewertung sein soll.
Dabei wird nicht blind eine fixe Anzahl von Bewertungen angesetzt, sondern die Stichprobe adaptiv erweitert, was Ressourcen und Zeit spart. Die Rolle der Skalenlänge sowie der Anzahl der Bewertungsstufen ist dabei nicht zu unterschätzen. Werden beispielsweise Likert-Skalen mit fünf Klassen verwendet, so steigt mit wachsender Granularität die Anzahl an benötigten Samples quadratisch an. Dies liegt daran, dass eine feinere Unterteilung höhere Präzision erfordert, um die verschiedenen Klassen sauber voneinander abzugrenzen. Als Faustregel dient die sogenannte Ein-Drittel-Methode, die empfiehlt, dass das Konfidenzintervall maximal ein Drittel der Breite einer Bewertungsstufe einnehmen sollte, um Überschneidungen zu vermeiden.
Ein weiterer wesentlicher Parameter ist die Normalisierung der Standardabweichung der Bewertungsdaten. Durch die Skalierung mit dem Wertebereich erhält man eine dimensionslose Kennzahl, die Auskunft über die Streuung der Evaluierungen im Verhältnis zur Gesamtskala gibt. Je höher die Normalisierte Standardabweichung, desto mehr Variabilität liegt vor, was wiederum zu einem quadratischen Anstieg der benötigten Bewertungen führt. Die Formeln, die diese Zusammenhänge ausdrücken, zeigen, dass die notwendige Stichprobengröße proportional zur Quadratwurzel des Z-Werts für den gewünschten Konfidenzgrad, zur Anzahl der Klassen im Quadrat und zum Quadrat der normalisierten Standardabweichung ist. Praktisch bedeutet dies, dass eine Erhöhung des Vertrauensniveaus von etwa 90 auf 95 Prozent den Aufwand moderat steigert, während eine höhere Klassenanzahl und größere Variabilität deutlich stärkere Effekte besitzen.
Ein intelligenter Algorithmus für sequentielle Stichproben kann diesen Prozess effektiv steuern. In einem ersten Schritt wird mit einer kleinen Pilotstichprobe begonnen, um einen ersten Schätzwert der Varianz zu erhalten. Daran anschließend wird dynamisch entschieden, wie viele weitere Bewertungen einzuholen sind, um die gewünschte Präzision zu erreichen. Somit wird die Datenmenge bedarfsgerecht erhöht und Über- oder Unterbewertungen vermieden. Auf technischer Ebene erfolgt häufig eine parallele Bearbeitung der Bewertungen, häufig in einer Größenordnung von etwa fünf bis zehn parallelen API-Aufrufen.
Das unterstützt eine effiziente Nutzung der Ressourcen bei der Verarbeitung, ohne dass die Latenz durch zu viele gleichzeitige Anfragen über Gebühr steigt. Die Herausforderung, dass einzelne Evaluatoren eine große Varianz aufweisen können, lässt sich durch die sogenannte Mixed-Expert Sampling Technik adressieren. Hierbei werden mehrere verschiedene LLM-Juroren genutzt, deren Bewertungen als unabhängige Stichproben behandelt werden. Dadurch wird das Ergebnis robuster gegenüber Fehlern einzelner Modelle und die Gesamtpräzision der Bewertung verbessert. Die Verwendung von unterschiedlichen Modellen mit abgestimmten Prompts sorgt zudem für eine bessere Generalisierbarkeit und minimiert individuelle Verzerrungen.
Weitreichende Implikationen ergeben sich für die Evaluierungsprozesse hinsichtlich Zeit, Kosten und Qualität. Die Kosten steigen linear mit der Anzahl der gesammelten Bewertungen beziehungsweise Anfragen an die Modelle. Die Latenz hängt sowohl von der Stichprobengröße als auch von der durchschnittlichen Batch-Größe der parallelen Anfragen ab. Um die Effizienz zu maximieren, sind kleinere und adaptive Batch-Größen zu empfehlen, da sehr große parallele Anfragen die Antwortzeiten signifikant verlängern können. Die Qualität der Bewertung verbessert sich mit höherer statistischer Sicherheit (also einem kleineren Alpha-Wert für das Konfidenzintervall) und mit einer feineren granulierten Klassifikation.
Dennoch sind hier Kompromisse notwendig, um die Kosten im Rahmen zu halten. Beispielsweise kann durch eine Reduktion der Anzahl der Bewertungsstufen eine quadratische Einsparung bei der benötigten Stichprobengröße erzielt werden, während ein weniger strenger Konfidenzgrad die Kosten nur mäßig reduziert. Aus praktischer Sicht empfiehlt es sich, zunächst mit ausreichenden Pilottestläufen (etwa zehn Bewertungen) einen ersten Schätzwert der Streuung zu erhalten. Falls historische Daten vorliegen, sollten diese genutzt werden, um initial möglichst präzise Startwerte für den Algorithmus zu gewinnen. Die Flexibilität dieses Ansatzes erlaubt es zudem kontinuierlich die Evaluierung anzupassen, sodass mit steigendem Wissen die Effizienz verbessert wird.
Zusammenfassend bietet die präzisionsbasierte Stichprobenziehung von LLM-Juroren eine fundierte und wirtschaftliche Methodik, um die Ungewissheit in Bewertungen großer Sprachmodelle zu reduzieren. Die Kombination aus statistischen Grundlagen, adaptiven Algorithmen und modernen Computertechnologien erlaubt es, verlässlichere Aussagen über die Leistungsfähigkeit von KI-Agenten zu treffen und gleichzeitig den Aufwand für Zeit und Kosten zu minimieren. Zukünftig lässt sich mit weiteren Optimierungen, wie der Integration zusätzlicher Expertenmodelle und der Verfeinerung der Bewertungsrubriken, die Genauigkeit und Robustheit nochmals erhöhen. Ebenso können durch eine automatisierte Analyse und Priorisierung besonders unsicherer Bewertungskriterien gezielt weitere Ressourcen eingesetzt werden. Mit der steigenden Verbreitung von LLMs in unterschiedlichsten Anwendungsbereichen wird die Bedeutung präziser, schneller und nachvollziehbarer Bewertungssysteme weiter zunehmen.
Förderlich sind dabei offene Ansätze und zugängliche Code-Repositories, die eine transparente Nachvollziehbarkeit ermöglichen und den Einstieg für neue Projekte erleichtern. Im Endeffekt profitieren Entwickler, Unternehmen und Endnutzer gleichermaßen von einer objektiven und belastbaren Evaluierung, die die Qualität der KI-Anwendungen sichert und das volle Potenzial moderner Sprachmodelle erschließt.


![Google Data Center Security [video] (2020)](/images/3E92BEAD-1FB7-4659-B0DB-C5FD17877246)


![Starship Flight 9 launches successfully, booster explodes on impact [video]](/images/DCE9CFAF-D04C-46A0-8E4C-8C3CC5434D6C)