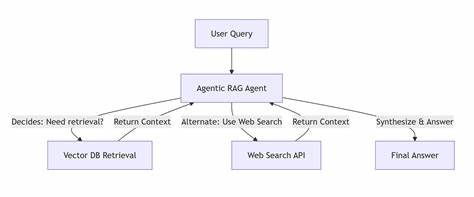
Retrieval Augmented Generation, kurz RAG, galt lange Zeit als ein vielversprechender Ansatz, um die Grenzen von Large Language Models (LLMs) zu überwinden, insbesondere im Bereich der autonomen Programmieragenten. In den Anfangstagen, als kontextuelle Fenster noch sehr eingeschränkt waren, bot RAG eine Möglichkeit, externe Informationen aus großen Datenbeständen zu ziehen und so die scheinbare Gedächtnisleistung von KI-Modellen zu erweitern. Doch die Erwartungen wurden zunehmend hinterfragt, und eine wachsende Zahl von Experten rät mittlerweile davon ab, RAG für autonome Coding Agents einzusetzen. Warum ist das so? Und welche Alternativen zeichnen sich ab? RAG basiert im Wesentlichen darauf, den Code oder Dokumentationen in kleine, handhabbare Abschnitte zu zerlegen, sogenannte Chunks. Diese werden mit Vektoren eingebettet und bei Bedarf mithilfe von Ähnlichkeitssuchen abgerufen, um so dem KI-Modell zusätzlichen Kontext zu liefern.
Während dies für einfache Anfragen oder kleinere Projekte eine kosteneffiziente und praktikable Lösung sein mag, geraten solche Systeme schnell an ihre Grenzen, sobald es um komplexe Aufgaben oder umfangreiche Codebasen geht. Experten wie Nik Pash, ein erfahrener Entwickler autonomer Agenten, weisen darauf hin, dass der Fokus auf RAG oft ein „mind virus“ ist – ein schädlicher Gedanke, der sich in der KI-Community festgesetzt hat und eine nahezu dogmatische Haltung gegenüber diesem Konzept fördert. Selbst etablierte Unternehmen, die ernsthaft daran interessiert sind, autonomen Agents nahe der Leistungsfähigkeit eines erfahrenen Softwareingenieurs zu entwickeln, unterschätzen die damit verbundenen Probleme. RAG kann eine Ablenkung sein, die wertvolle Ressourcen verschlingt und die Qualität des Endprodukts beeinträchtigt. Die fundamentale Kritik an RAG liegt darin, dass es oft nicht möglich ist, komplexe technische Fragen abschließend nur durch die Betrachtung isolierter Code-Snippets zu beantworten.
Ein senior Entwickler, der sich in einem neuen Code-Großprojekt zurechtfinden möchte, liest nicht einfach einzelne Codeteile, sondern betrachtet Zusammenhänge – die Ordnerstruktur, Abhängigkeiten, Imports, das Zusammenspiel von Modulen und die gesamte Architektur. Dieses natürliche explorative Vorgehen können einfache Retrieval-Systeme mit verstreuten Code-Fragmenten nicht nachbilden. Viele Unternehmen haben zwar RAG-basierte Systeme implementiert, jedoch meist ohne eine rigorose und qualitative Chunkerstellung oder detaillierte Erfolgsmessung. Die Folge sind häufig suboptimale Ergebnisse, die den Einsatz des Systems infrage stellen. Dies bestätigt auch die Beobachtung von Quinn Slack, CEO von Sourcegraph, der feststellt, dass ein Großteil der bisherigen RAG-Implementierungen nicht die Qualität und Tiefe erreichte, die tatsächlich gebraucht wird.
Die Einführung größerer Kontextfenster und verbesserter Modelle, wie Claude Sonnet 3.5, 3.7 und 4.0, öffnet neue Türen für autonome Agenten. Die Beschränkung der Kontextgröße ist nicht mehr das Hauptproblem.
Dennoch stößt die Qualität des Kontextes schnell an ihre Grenzen, wenn die zugrundeliegende Architektur sich weiterhin auf fragmentierte Informationsabrufe verlässt. Statt also Ressourcen in die Weiterentwicklung und Komplexitätssteigerung von RAG-Systemen zu stecken, setzen zunehmend innovative Teams auf alternative Methoden. Ein leuchtendes Beispiel ist Cline, ein Autonomer Programmieragent, der sich durch seinen menschenähnlichen Ansatz bei der Code-Analyse hervorhebt. Cline navigiert wie ein erfahrener Entwickler durch die Ordnerstruktur, verfolgt Importpfade und analysiert abstrakte Syntaxbäume (ASTs). Dieser agentische Ansatz erzeugt einen kontextreichen Zugang zum Code und ermöglicht dadurch ein tiefgründiges Verständnis, das über bloße Text-Suchmechanismen hinausgeht.
Cline stellt die aktive Exploration in den Mittelpunkt und nutzt somit die Fähigkeiten moderner großer Modelle effektiver aus. Diese neue Generation autonomer Agenten zeigt, dass man sich von der passiven Repetition fragmentierter Informationen lösen kann. Stattdessen braucht es aktive, kontextbewusste Arbeitsschritte, die flexibel auf unterschiedliche Strukturen und Herausforderungen reagieren. Damit geht einher, dass man die Komplexität im System reduziert und klassische „Scaffolds“ wie aufwändige RAG-Infrastrukturen eliminiert. Auch in der Praxis führt diese Strategie zu besseren Ergebnissen und einer höheren Effizienz.
Anstatt auf immer größere, wartungsintensive Retrieval-Systeme zu setzen, konzentrieren sich Entwickler darauf, ihrem Agent Tools und Zugriffsrechte zu geben, wie sie auch menschliche Experten nutzen – etwa direkte Code-Analysen, dynamische Exploration und kontextbezogene Priorisierung. Ein weiterer Vorteil dieses Ansatzes ist die bessere Wartbarkeit und Skalierbarkeit. Viele RAG-Systeme erfordern aufwendige Integrationen und kontinuierliche Pflege, um mit der Entwicklung des Codebestands Schritt zu halten. Dies bindet Entwicklerressourcen langfristig und erzeugt technische Schulden. Die aktiv-agents-basierte Herangehensweise ermöglicht dagegen eine robustere und langfristig stabilere Architektur.
Trotz aller Kritik ist RAG nicht komplett überflüssig. In bestimmten Anwendungsfällen, etwa bei Supportbots oder für Fragen zu Dokumentationen, kann Retrieval Augmented Generation nach wie vor sinnvoll sein. Die Filterung von Faktenwissen aus unstrukturierten Texten oder das Beantworten von häufig wiederkehrenden Fragen stellen typische Anwendungsfelder dar. Doch sobald es um die komplexe, mehrstufige Problemlösung in einem dynamischen Codeumfeld geht, zeigt sich RAG als hinderlich und oft kontraproduktiv. Die Zukunft autonomer, selbstlernender Programmieragenten liegt daher in der Kombination aus großem Kontextverständnis, aktiver Exploration und der Fähigkeit, die Komplexität eines Codebasissystems ganzheitlich zu erfassen.
Neue Architekturen, wie etwa Memory-Centric Processing (MCP), versprechen ebenfalls eine innovative Alternative und tragen dazu bei, dass Agenten kontextbewusst und effizient agieren können, ohne dass sie sich in einem Daten-Dschungel von Chunks verlieren. Zusammenfassend lässt sich sagen, dass die Ära von RAG als Allheilmittel für autonome Programmieragenten zu Ende geht. Wer qualitativ hochwertige, agile und menschenähnliche Agenten bauen möchte, sollte den Blick weiten und sich auf kontextorientierte, aktive und nachhaltige Ansätze konzentrieren. Die technische Evolution und die Remarkable-Fortschritte im Bereich der LLMs eröffnen heute Möglichkeiten, die vor wenigen Jahren noch Zukunftsmusik waren. Für Entwickler und Unternehmen bedeutet dies, ihre Strategie zu hinterfragen, mutig neue Wege zu gehen und Gewohnheiten abzulegen, die auf alten Konzepten basieren.
Die Investition, die heute in innovative, kontextsensitive Speicher- und Analysemethoden fließt, wird morgen den Unterschied zwischen einem mittelmäßigen Tool und einem echten Wettbewerbsvorteil ausmachen. Der Weg zu autonomen Programmieragenten, die ein tiefes Verständnis und Flexibilität an den Tag legen, führt nicht über das Ausquetschen von statischen Informationsteilen, sondern über die Abbildung menschlichen Denkens und Arbeitens im Kontext von Softwareentwicklung. Dieses Paradigma ist komplex, aber entfesselt das wahre Potenzial moderner KI. Die Tage, an denen RAG das Nonplusultra war, gehören der Vergangenheit an – eine neue Ära der autonomen Programmierung hat begonnen.