Seit vielen Jahren träumte ich davon, GPU-Programmierung zu erlernen und endlich habe ich im April 2025 begonnen, mich intensiv mit CUDA auseinanderzusetzen. Warum erst jetzt? Die Antwort liegt in der vielschichtigen Entwicklung meiner Karriere und Interessen. Zunächst galt mein Fokus Webentwicklung, APIs und DevOps, und erst mit dem kometenhaften Aufstieg von Large Language Models (LLMs) und der wachsenden Bedeutung von maschinellem Lernen wurde mir bewusst, wie essenziell GPU-Computing für die Zukunft der Technik ist. Doch die Wurzeln meiner Motivation liegen viel tiefer – in der Faszination für Hardware, tiefere Systemebenen und dem simplen Vergnügen, Dinge zum Laufen zu bringen. Dieser Artikel fasst meine wichtigsten Erkenntnisse und Lernerlebnisse zusammen und bietet einen Einblick in die Welt der GPU-Programmierung mit CUDA.
GPU-Programmierung begann ursprünglich mit Grafikshadern. Diese Shader sind kleine Programme, die direkt auf der Grafikhardware ausgeführt werden und bestimmen, wie Grafiken auf dem Bildschirm dargestellt werden. Frühe Grafikkarten arbeiteten noch mit fest verdrahteten Pipelines, in denen jeder Schritt starr vorgegeben war – von der Vertex-Verarbeitung bis zur Farb- und Texture-Berechnung. Dies änderte sich mit der Einführung der Unified Shader-Architektur, die es der GPU erlaubte, vielfältigere Berechnungen auszuführen, nicht nur für Grafik, sondern für allgemeine Aufgaben. Nvidia führte mit der 8800 GTX eine programmierbare, flexible Pipeline ein.
Parallel dazu wandelte sich das Programmiermodell mit CUDA zu einem mächtigen Tool, das Entwicklern erlaubte, sogenannte Kernel zu schreiben – Funktionen, die direkt auf der GPU laufen und massiv parallel Berechnungen durchführen. Das frühere Verständnis von Shader-Programmen wie GLSL oder HLSL hilft beim Eintauchen in CUDA, da sich viele Konzepte und die zugrundeliegende Syntax ähneln. Doch CUDA öffnete die Tür zu viel breiteren Anwendungsspektren, darunter Bild- und Videobearbeitung, wissenschaftliche Simulationen, 3D-Rendering sowie maschinelles Lernen, das heute wohl die wichtigste Spielwiese für GPUs darstellt. Ein Schlüsselaspekt der GPU-Programmierung ist das Verständnis der Speicherbandbreite im Verhältnis zur Rechenleistung. Moderne GPUs wie die RTX 4090 verfügen zwar über beeindruckende Spitzenleistungen von bis zu 82 Teraflops, doch die Speicherbandbreite liegt mit etwa 1 Terabyte pro Sekunde deutlich darunter.
Das bedeutet, dass die Geschwindigkeit der Datenübertragung zum Flaschenhals wird. Wenn man beispielsweise zwei 32-Bit-Floating-Point-Zahlen addiert und das Ergebnis speichert, werden für diese eine Operation bereits etwa 12 Byte Speicher benötigt. Würde man die theoretische Rechenkapazität vollständig ausnutzen wollen, wäre ein Speicherbandbreitebedarf von fast 1000 Terabyte pro Sekunde nötig – eine Größenordnung, die aktuelle und künftige Speichertechnologien nicht erfüllen können. Diese Diskrepanz zeigt, wie wichtig es ist, Algorithmen so zu gestalten, dass sie möglichst viele Rechenoperationen pro Byte Speicherzugriff leisten. Die Effizienz der GPU hängt also stark davon ab, wie gut der Algorithmus die Speicherzugriffe minimiert und idealerweise wiederverwendet.
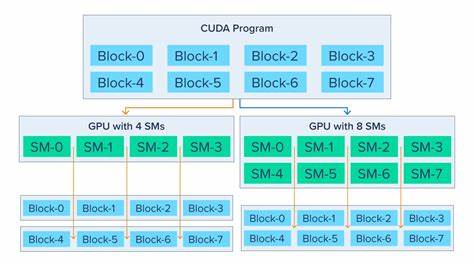
Hier kommen die speziellen Speicherhierarchien der GPU ins Spiel, vor allem das sogenannte Shared Memory auf Streaming Multiprocessoren. Dieses Shared Memory funktioniert ähnlich wie ein Cache und ermöglicht Threads innerhalb eines Blocks, Daten gemeinsam zu nutzen, ohne jeden Zugriff über den langsamen globalen Speicher laufen zu lassen. Ein gelungener GPU-Kernel profitiert davon, Daten zunächst in das Shared Memory zu laden und dort mehrfach zu nutzen, um die Geschwindigkeit der Ausführung zu maximieren. Die Programmierung auf der GPU erfordert auch ein Umdenken bei der Parallelisierung. Während auf klassischen CPUs oft nur wenige Threads gleichzeitig laufen, ist die GPU darauf ausgelegt, Tausende oder gar Millionen von Threads parallel auszuführen.
Im Gegensatz zur gewohnten CPU-Programmierung, bei der ein einzelner Thread eine relativ große Menge Arbeit erledigt, sind GPU-Threads oft sehr leichtgewichtig und übernehmen einen winzigen Teil der Gesamtrechnung. Ein Beispiel hierfür ist die Matrixmultiplikation: Wo man auf einem CPU einen Thread mit der gesamten Berechnung eines Elements beauftragt, hat man auf der GPU für jeden einzelnen Ausgabewert einen eigenen Thread, der die notwendigen Teilschritte ausführt. Um die Effizienz zu steigern, wird die Berechnung oft in Kacheln (Tiling) gegliedert. Dabei laden Threads portionsweise Datenstücke aus den beiden Ausgangsmatrizen in das Shared Memory, führen ihre lokale Berechnung durch und summieren dann die Ergebnisse auf. Dieses Vorgehen ermöglicht es, den Speicherzugriff zu optimieren und die Parallelität maximal auszunutzen.
Das Konzept des Tiled Matrix Multiplication zeigt auch, wie stark ein Umdenken erforderlich ist. Anstatt von den Eingabedaten zu den Ausgabedaten zu denken, sollte man sich beim GPU-Programming an den Ausgangspunkt, also die Output-Threads, orientieren und so die Berechnung rückwärts herunterbrechen. Dadurch lassen sich nicht nur viele Parallelisierungsfallen vermeiden, sondern auch clever Speicherzugriffe planen. Mein Lernweg im Bereich CUDA war stark praxisorientiert. Ich nutzte Plattformen wie Tensara, eine Art LeetCode für Machine Learning und GPU-Problemstellungen, um kleine CUDA-Kernel zu schreiben und zu testen.
Die Herausforderung war oft, dass Fehler in solchen parallelen Umgebungen schwer zu debuggen sind und man durch Fehlermeldungen oder nur stichprobenhafte Testausgaben limitiert ist. Trotzdem bringt gerade das Experimentieren mit vielen einfachen Problemen einen enormen Lernerfolg. Neben Tensara entdeckte ich LeetGPU, das zwar noch eine kleinere Sammlung an Problemen besitzt, aber mit erweiterten Features punkten kann, wie etwa Lösungskommentaren und Performancevergleichen. Diese Angebote bauen auf der Sammlung „KernelBench“ auf, wo eine Reihe teils hochkomplexer Aufgaben aus dem Bereich Machine Learning und GPU-Computing angeboten werden. Das Lösen dieser Aufgaben bietet eine exzellente Trainingsmöglichkeit, um seine Fähigkeiten sowohl im Parallelprogrammieren als auch im Verstehen moderner KI-Architekturen auszubauen.
Eine besondere Empfehlung ist der Blick auf Projekte wie HipScript. Dieses faszinierende Projekt von Ben Schattinger ermöglicht es, CUDA-Code im Browser auszuführen, indem es CUDA-Kerne mittels AMDs HIP-Toolchain in plattformübergreifenden Code übersetzt. Das zeigt eindrucksvoll, wie vielseitig und offen die GPU-Entwicklung mittlerweile geworden ist und bietet gleichzeitig spannende neue Wege, CUDA zu erlernen, ohne auf teure Hardware angewiesen zu sein. Als wichtige Literaturquellen kann ich den "Orange Book" empfehlen, offiziell bekannt als „Programming Massively Parallel Processors“. Dieses Buch bietet eine fundierte Einführung in verschiedene parallele Programmiermuster und deckt neben praktischen Algorithmen wie Kachel-Matrixmultiplikation auch Themen wie parallele Reduktion und effiziente Nutzung der Hardware ab.
Ein Manko des Buchs ist, dass es oft wenig konkrete Hilfe bei der Berechnung von Grid- und Blockgrößen gibt, ein essenzieller Punkt, um CUDA-Programme korrekt zu starten und die maximale Performance herauszuholen. Trotzdem ist das Buch ein unverzichtbarer Begleiter. Ein weiteres gutes Werk ist „Professional CUDA C Programming“, das mehr Details zur Schnittstelle und den APIs liefert, die man zum Steuern der GPU benötigt. Während ich nach wie vor mit Raspberry Pis und anderen Spielzeugen zu Hause experimentiere, plant meine weitere Lernreise, intensiver auf größeren GPUs (möglicherweise GPU-basierten Notebook oder Cloud-VMs) zu arbeiten. Dabei möchte ich mindestens die Hälfte der Aufgaben bei Tensara meistern, um sicherzustellen, dass ich ausreichend Praxis gesammelt habe.
Abschließend lohnt sich auch der Blick in die Forschung, insbesondere auf Architektur- und Software-Lösungen für High Performance Computing (HPC). Dabei sticht die Fire-Flyer HPC Architektur hervor, einer innovativen, chinesischen Entwicklung, die durch effiziente Kommunikationsmechanismen in Multi-GPU-Setups neue Maßstäbe setzt. Solche Entwicklungen zeigen, wie global die GPU-Entwicklung heute ist und illustrieren, dass Fortschritt vor allem durch jahrelange Forschung und ingenieurtechnisches Know-how entsteht. GPU-Programmierung mit CUDA zu lernen bedeutet nicht nur, C-ähnlichen Code zu schreiben, sondern einen ganz neuen Denkstil zu verinnerlichen. Das Auseinandernehmen komplexer Berechnungen in winzige, parallele Aufgaben, das Optimieren von Speicherzugriffen und das Verstehen der speziellen Hardwarearchitektur sind dabei zentrale Bausteine.
Mein April 2025 Lernmonat war ein Schritt auf diesem Weg, der sicherlich noch viele weitere spannende Herausforderungen bereithält.




![Programming Without Pointers [video]](/images/CDD79BDF-8ABF-4398-B47B-5E8A66FD9131)