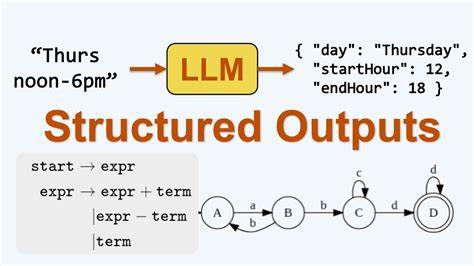
Große Sprachmodelle (Large Language Models, LLMs) haben die Art und Weise revolutioniert, wie Maschinen natürliche Sprache verstehen und erzeugen. Mit zunehmender Verbreitung dieser Modelle wächst auch das Bedürfnis nach kontrollierten und strukturierten Ausgaben, um die Qualität und Anwendbarkeit der Resultate zu erhöhen. Gerade in Anwendungen, in denen die Ergebnisse weiterverarbeitet, validiert oder in Datenbanken gespeichert werden müssen, sind strukturierte Ausgaben essenziell. Doch wie funktioniert diese strukturierte Ausgabe unter der Haube wirklich? Welche Mechanismen sorgen dafür, dass ein LLM nicht nur freien Text liefert, sondern genau einem bestimmten Format folgt? Diese Fragen beantworten wir eingehend. Das Prinzip der strukturierten Ausgabe von LLMs basiert auf der kontrollierten Steuerung des Generierungsprozesses.
Klassisch generieren Sprachmodelle Text zeichen- oder tokenweise sequenziell, wobei sie basierend auf dem bisher erzeugten Text Wahrscheinlichkeiten für die nächsten Zeichen ermitteln. Für freie Texteingaben stellt das keinerlei Problem dar, doch wenn es darum geht, eine exakt definierte Struktur einzuhalten, etwa ein JSON-Format, entsteht eine Herausforderung. Schließlich ist das Modell von Haus aus darauf trainiert, kohärente Sprache zu erzeugen, nicht aber spezifisch formatierte digitale Datasets. Eine gängige Lösung in diesem Kontext ist die sogenannte Prompt-Engineering-Technik. Dabei wird das Modell mit einem sorgfältig gestalteten Eingabe-Prompt versorgt, der ihm die gewünschte Struktur vorgibt.
Wenn der Prompt etwa ein Beispiel für ein JSON-Objekt enthält oder explizite Anweisungen, dass die Antwort als bestimmte Modelldefinition auszugeben ist, „entscheidet“ das Modell aufgrund seiner trainierten Wahrscheinlichkeiten, eine Antwort zu erzeugen, die diesem Format entspricht. Doch dies ist keine Garantie für perfekte Einhaltung. Das Modell kann zwischendurch Syntaxfehler machen oder vom vorgegebenen Muster abweichen. Die Integration von Typisierungstools wie Pydantic, insbesondere in Python-Umgebungen, bringt hier eine weitere Ebene ins Spiel. Pydantic definiert Datenmodelle mit klaren Typen und Validierungsregeln.
Entwickler können diese Modelle nutzen, um zu definieren, wie die Ausgabe eines LLM aussehen soll – etwa welche Schlüssel ein JSON haben muss, welche Werte erwartet werden und wie diese zu validieren sind. Das Modell selbst generiert aber weiterhin Text. Im Zusammenspiel bedeutet das, dass man das LLM auffordert, eine Antwort im JSON-Format zu liefern, die dann durch Pydantic validiert wird. Misslingt die Validierung, kann eine erneute Abfrage erfolgen oder die Antwort korrigiert werden. Interessanterweise wird die eigentliche Einschränkung oder Formatbindung nicht allein durch das LLM selbst erzwungen.
Stattdessen ist es ein Zusammenspiel von Prompt-Design, Nachbearbeitung und Validierung, das strukturierte Ausgabe möglich macht. Einige modernere Implementierungen und Frameworks wie OpenAI’s Funktion zum „structured output“ versuchen diesen Prozess zu optimieren, indem sie dem Modell explizit Beispielausgaben geben, die Formatregeln verdeutlichen. Zusätzlich kann man der API anweisen, die Ausgabe strukturierter und weniger fehleranfällig zu gestalten durch systematische Steuerbefehle oder spezielle Tokens, die das Ausgabeformat begrenzen. Darüber hinaus existieren innovative Ansätze, bei denen strukturierte Daten direkt in den Kontext des Modells eingebettet werden. Das können etwa aufgebaute JSON-Strukturen sein, die als Vorlagen dienen, in welche das Modell dann gezielt Befüllungen vornehmen soll.
So wird die Wahrscheinlichkeit erhöht, dass die Ausgabe dem gewünschten Format entspricht, weil das Modell weniger Freiraum hat, kreativen oder freien Text zu erzeugen und stattdessen Muster vervollständigt. Zusammengefasst ist das Konzept der strukturierten Ausgabe komplex und erfordert oft eine mehrschichtige Herangehensweise. Das LLM selbst produziert textuelle Antworten, die durch präzise Prompts, Modellierung von Datenstrukturen und externe Validierung auf das gewünschte Format eingedampft werden. Die Technologie entwickelt sich kontinuierlich weiter, um den Grad der strukturellen Kontrolle zu erhöhen und gleichzeitig die Leistungsfähigkeit natürlicher Sprachmodelle nicht zu beeinträchtigen. In der Praxis zeigen sich viele Anwendungsfälle, in denen strukturierte Ausgaben unverzichtbar sind – beispielsweise in Chatbots, die Buchungen vornehmen, oder Systemen, die Informationen automatisch in Datenbanken speichern.
Dort ist nicht nur wichtig, dass die Antwort sinnvoll ist, sondern dass sie exakt den erwarteten Datenanforderungen genügt. Der Fortschritt in der Verbindung von LLM-Technologie und strukturierten Datenschemata verspricht, Softwarelösungen neu zu definieren, Kommunikation effizienter zu gestalten und Automatisierung intelligenter zu machen. Zusätzlich zu JSON ist das Prinzip auf andere strukturierte Formate übertragbar, etwa XML oder proprietäre Objektdarstellungen. Es bleibt spannend zu beobachten, wie sich die Methoden weiterentwickeln, um den Spagat zwischen kreativem Texteinsatz und präziser Datenstruktur zu meistern. Neue Forschungsansätze im Bereich kontrolliertes Textgenerieren und der Einsatz von formalen Grammatikregeln in der Modellarchitektur könnten künftig noch strengere und fehlerfreie Ausgaben gewährleisten.