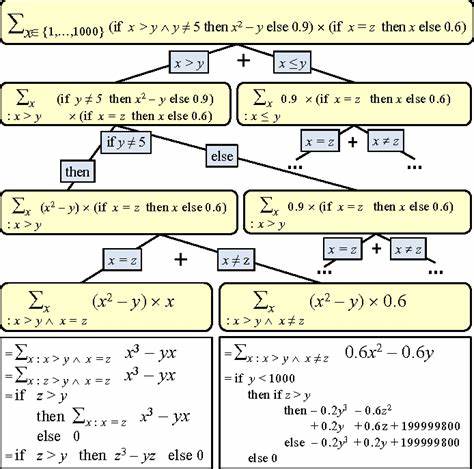
Die Informationstheorie, wie sie ursprünglich von Claude Shannon Mitte des 20. Jahrhunderts formuliert wurde, bildet die Grundlage für die digitale Kommunikation und Datenübertragung unserer Zeit. Ihre Konzepte von Entropie, Informationsgehalt und Signalübertragung haben die Art und Weise revolutioniert, wie wir mit Daten umgehen. Doch mit dem Aufkommen großer Sprachmodelle (Large Language Models, LLMs) steht eine neue Ära bevor, die sowohl die theoretischen Grundlagen als auch die praktische Anwendung von Informationstheorie auf spannende Weise herausfordert und erweitert. Die klassischen Definitionen von Informationsgehalt und Entropie basieren auf der Wahrscheinlichkeit von Ereignissen innerhalb eines bestimmten Signals oder Datenstroms.
Entropie misst dabei die Unvorhersehbarkeit oder Komplexität der Information. Allerdings arbeitet Shannon in seinem Modell hauptsächlich auf der Ebene von Symbolen und deren statistischen Verteilungen, ohne jedoch die semantische Bedeutung dieser Symbole ausdrücklich zu berücksichtigen. Hier setzen LLMs an und eröffnen eine bislang wenig erforschte Dimension zwischen reiner Datenverarbeitung und der Interpretation von Bedeutung. Große Sprachmodelle, wie beispielsweise GPT-Modelle oder BERT, basieren auf tiefen neuronalen Netzwerken, die mit enormer Datenmenge trainiert wurden. Sie erfassen nicht nur die statistischen Muster in Texten, sondern können auf eine Art Kontext und semantische Zusammenhänge zugreifen, die über klassische Wahrscheinlichkeitsrechnung hinausgehen.
In diesem Sinne erweitern LLMs die Informationstheorie in Richtung semantischer Information, was ein lang diskutiertes und wenig befriedigend gelöstes Problem im Bereich der Informationswissenschaften ist. Ein zentrales Thema dabei ist die Korrelation zwischen der Menge des Trainingsmaterials und der Leistungsfähigkeit der Modelle. Klassische Informationstheorie betont, dass je höher die Entropie eines Signals, desto mehr Information enthalten ist, und dass eine präzise Kommunikation eine Minimierung von Unsicherheit voraussetzt. LLMs zeigen allerdings, dass gigantische Mengen an Trainingsdaten nicht nur die Genauigkeit der Output-Texte verbessern, sondern auch die Fähigkeit, komplexe Bedeutungsstrukturen zu generieren, die weit über einfache Wahrscheinlichkeitsverteilungen hinausgehen. Dabei ist es bemerkenswert, wie sich mit steigendem Volumen und Vielfalt an Daten die Qualität und Kohärenz der erzeugten Sprache exponentiell steigert.
Darüber hinaus fordern große Sprachmodelle traditionelle Konzepte der Kommunikation heraus, indem sie als Vermittler zwischen menschlicher Intuition und maschineller Verarbeitung fungieren. Kommunikation war klassisch als Sender-Empfänger-Modell definiert, bei dem Informationen möglichst verlustfrei übertragen werden sollten. LLMs erzeugen jedoch Inhalte, die nicht bloß übertragen, sondern auch neu generiert und interpretiert werden. Das bedeutet, dass Information nicht als starres Element verstanden werden kann, sondern als dynamischer Prozess, der aktiv vom Modell mitgedeutet wird. Diese Entwicklung könnte die Art und Weise verändern, wie wir über Informationsübertragung in digitalen Netzwerken denken.
Zusätzlich wird die Rolle der Entropie in der Modellarchitektur neu gewichtet. LLMs tragen zur Debatte bei, ob Entropie allein als Maß für Informationstiefe genügt oder ob zusätzliche, semantisch orientierte Maße notwendig sind. Die Fähigkeit der Modelle, Unterschiede zwischen bedeutungstragenden und redundanten Inhalten zu erkennen und zu generieren, zeigt, dass die reine quantitative Betrachtung der Entropie einer qualitativen Betrachtungsweise weichen muss. Damit werden traditionelle Grenzen der Informationstheorie verschoben und eröffnen Forschungsfelder, in denen Wahrscheinlichkeit, Semantik und Kontext auf neue Weise zusammenwirken. Auch die Analyse von Fehlern und Unsicherheiten bekommt eine neue Dimension.
Während klassische Informationstheorie Vorhersagen über Fehlerraten und korrigierende Codes trifft, gehen LLMs einen Schritt weiter, indem sie Unsicherheiten im Ausdruck von Bedeutung und Kontext mitberücksichtigen. Dies führt zu Modellen, die nicht nur robust gegenüber Datenrauschen sind, sondern auch mit ambivalenten oder mehrdeutigen Informationen umgehen können – eine Fähigkeit, die bei klassischen codierenden Systemen nicht vorgesehen ist. Die Auswirkungen auf die Praxis sind vielfältig. In der automatisierten Textgenerierung, der maschinellen Übersetzung oder der Verarbeitung natürlicher Sprache ermöglichen LLMs präzisere, kontextbewusstere und menschlichere Interaktionen. Das wiederum stellt Anforderungen an die Informationstheorie, solche Ergebnisse theoretisch zu untermauern und neue, umfassendere Modelle zu entwickeln, die Fähigkeit und Grenzen dieser neuen Technologien abbilden.
Auf gesellschaftlicher Ebene werfen diese Entwicklungen Fragen nach dem Umgang mit Information, Bedeutung und Vertrauen auf. Die Fähigkeit von LLMs, Texte nicht nur zu erkennen, sondern auch zu generieren, beeinflusst Kommunikationsprozesse in sozialen Medien, Bildung oder Journalismus. Dies wiederum verlangt nach einer genaueren Betrachtung von Informationsqualität und der Rolle von Entropie in digitalen Kontexten, um Desinformation und Manipulation besser verstehen und kontrollieren zu können. In der Forschung spiegelt sich diese Dynamik in einem intensiveren Diskurs über sogenannte synthetische Information wider – jene Art von Informationen, die von Künstlicher Intelligenz geschaffen wird. Es entsteht ein Paradigmenwechsel, der von der reinen Übertragung hin zu einer Kombination aus Übertragung und Generierung reicht.
Dabei steht die Frage im Raum, wie klassische Modelle der Informationstheorie erweitert oder angepasst werden können, um die „bedeutungsvolle Information“ als eigenständigen Begriff zu fassen. Zum Abschluss lässt sich festhalten, dass große Sprachmodelle einen bedeutenden Impuls für die Weiterentwicklung der Informationstheorie darstellen. Indem sie klassische Begriffe wie Entropie, Kommunikation und Information um die Dimension der Semantik und Kontextualität erweitern, schaffen sie neue Perspektiven auf ein altbewährtes Feld. Die Herausforderung liegt nun darin, diese Potenziale theoretisch zu erfassen und praktisch zu nutzen, um das Verständnis von Information im digitalen Zeitalter grundlegend zu vertiefen und zukunftsfähig zu gestalten.