Die Entwicklung von großen Sprachmodellen, auch bekannt als Large Language Models (LLMs), hat die Art und Weise revolutioniert, wie wir mit Informationen umgehen. Nutzer können komplexe Fragestellungen formulieren und auf erstaunlich präzise Antworten hoffen. Doch häufig bestehen Informationsquellen aus lokal gespeicherten Dokumenten, wie PDFs, die nicht ohne Weiteres in öffentliche Sprachmodelle eingebunden sind. Hier setzt das Thema an, lokale LLMs mit lokalen PDFs anzureichern, um Wissen aus eigenen Dateien nutzbar zu machen und eine individuelle, datenschutzkonforme Rechercheumgebung zu schaffen. Warum lokale LLMs mit PDFs anreichern? Viele Unternehmen und Privatpersonen besitzen umfangreiche Sammlungen von PDFs: Studienberichte, wissenschaftliche Paper, Handbücher, Verträge oder interne Dokumentationen.
Traditionelle Suchfunktionen innerhalb von PDF-Readern oder Betriebssystemen stoßen schnell an ihre Grenzen, wenn es darum geht, Zusammenhänge zu verstehen, kontextuell passende Auszüge zu liefern oder Inhalte klar zu interpretieren. Lokale LLMs bieten hier den großen Vorteil, dass sie nicht nur reine Suchergebnisse liefern, sondern in der Lage sind, dokumentenübergreifendes Wissen zu verknüpfen, Fragestellungen in natürlicher Sprache zu verstehen und präzise Antworten zu generieren. Die Anreicherung lokaler LLMs mit PDFs bedeutet in der Praxis, die Inhalte dieser PDFs in ein format zu bringen, das das Sprachmodell verarbeiten kann. Moderne Sprachmodelle arbeiten mit Textdaten, weshalb der erste Schritt meist das Extrahieren des Texts aus den PDF-Dokumenten ist. Dabei gilt es, auch Formatierungen, Tabellen oder Grafiken nach Möglichkeit so zu erhalten, dass wesentliche Informationen nicht verloren gehen.
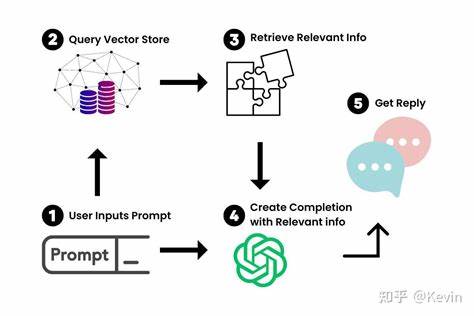
Im Anschluss werden diese Textdaten in einer Art Wissensdatenbank oder Index abgelegt, der eine schnelle Zugriffsmöglichkeit für das Modell ermöglicht. Technisch gesehen kommen für den Aufbau eines solchen Systems verschiedene Komponenten zum Einsatz. Zunächst benötigt man Tools zum PDF-Parsing und zur Textextraktion. Open-Source-Bibliotheken wie PyMuPDF, pdfplumber oder Apache PDFBox sind hierbei beliebte Optionen. Danach folgt oftmals eine semantische Indizierung der extrahierten Texte, meist mit Hilfe von Vektor-Datenbanken, die es ermöglichen, ähnliche Dokumentabschnitte anhand der Bedeutung zu finden, anstelle nur nach einfachen Schlagwörtern zu suchen.
Für diese Aufgabe sind Tools wie FAISS, Pinecone oder Weaviate weit verbreitet. Im letzten Schritt wird das eigentliche LLM angesteuert, um Fragen zu beantworten oder Informationen zusammenzufassen. Hierbei kann ein lokal gehostetes Modell genutzt werden, um volle Kontrolle über die Daten zu behalten, oder ein cloudbasierter Dienst, der zusätzliche Leistung und Aktualität mitbringt. Einige Open-Source-Modelle ermöglichen mittlerweile den Einsatz auch auf privaten Rechnern, was für sensible Daten besonders wichtig ist. Die Vorteile eines solchen Systems liegen auf der Hand.
Zum einen wird der Datenschutz gewahrt, da keine sensiblen Dokumente den eigenen Server oder die eigene Infrastruktur verlassen. Zum anderen kann die Suche tiefer und kontextsensitiver erfolgen: Statt stumpfer Stichwortsuche versteht das Modell Zusammenhänge und kann auch komplexe Fragen beantworten. Auch lassen sich personalisierte Wissensdomänen aufbauen, die optimal auf die Bedürfnisse eines Unternehmens oder Forschungsteams abgestimmt sind. Ein Beispiel aus der Praxis: Ein Forschungsinstitut, das hunderte wissenschaftliche Artikel lokal vorliegen hat, möchte regelmäßig neue Erkenntnisse für interne Projekte extrahieren. Mit einer Lösung, die PDF-Inhalte in das lokale LLM einspeist, können Forscher direkt mit einer Chat-ähnlichen Oberfläche kommunizieren, Fragen auf Basis aller Dokumente stellen und Auszüge erhalten, die sie zitieren oder als Grundlage für weitere Analysen nutzen können.
Momentan gibt es einiges an Open-Source-Projekten und kommerziellen Tools, die sich genau dieser Herausforderung annehmen. Projekte wie LangChain oder Haystack sind Frameworks, die die Erstellung von Wissensdatenbanken für LLMs erleichtern. Sie unterstützen den Import verschiedener Dokumentformate, darunter PDFs, sowie die Anbindung an Vektor-Datenbanken und Modelle. Kommerzielle Anbieter bieten ebenfalls Komplettlösungen an, wobei der Fokus oft auf Benutzerfreundlichkeit und skalierbare Cloud-Infrastruktur gelegt wird. Dennoch stehen Nutzer vor einigen Herausforderungen.
Die Textqualität der PDFs kann variieren, was die Extrahierung erschwert. Insbesondere bei gescannten oder handschriftlichen Dokumenten ist eine vorhergehende Texterkennung (OCR) nötig, die mit Fehlern behaftet sein kann. Auch die laufende Pflege der Wissensdatenbank und die regelmäßige Aktualisierung der Datenbestände erfordern organisatorischen Aufwand. Technologisch wandelt sich das Feld rasant. Die Leistungsfähigkeit von lokalen LLMs verbessert sich kontinuierlich, und es zeichnen sich Wege ab, größere Modelle auch mit begrenzten Rechnerressourcen effektiv einzusetzen.
Gleichzeitig werden Workflows zur Integration von PDFs und anderen Dokumentarten immer benutzerfreundlicher gestaltet. Nutzer, die heute Zeit und Ressourcen in den Aufbau einer solchen Infrastruktur investieren, können zukünftig von deutlich effizienteren Arbeitsprozessen profitieren. Die Zukunftsperspektiven einer solchen Lösung weisen ebenfalls auf eine Verschmelzung unterschiedlicher Technologien hin. Die Kombination von KI-gestützter Dokumentenanalyse mit kollaborativen Plattformen und Workflows kann das Potenzial von Wissen in Unternehmen und Forschungseinrichtungen enorm steigern. Zusätzlich schafft die Möglichkeit, Daten lokal und geschützt zu halten, Vertrauen und Sicherheit – zwei Aspekte, die in einer zunehmend datengetriebenen Welt zentral sind.
Abschließend lässt sich sagen, dass die Anreicherung lokaler LLMs mit lokalen PDFs ein vielversprechender Weg ist, aus bislang unstrukturierten und schwer zugänglichen Dokumentensammlungen wertvolles Wissen nutzbar zu machen. Wer sich mit den Kerntechnologien vertraut macht, kann individuelle Lösungen entwickeln und so die digitale Wissensarbeit auf ein neues Level heben. Die Kombination aus den Stärken von LLMs und der lokalen Kontrolle über sensible Informationen macht dieses Vorgehen zu einer zukunftssicheren Investition in die Effizienz und Qualität der eigenen Informationsverarbeitung.