In der Welt der natürlichen Sprachverarbeitung (NLP) spielen Sprachmodelle eine zentrale Rolle bei der Darstellung und Verarbeitung von Texten. Insbesondere Text-Embeddings, also die Umwandlung von Text in numerische Vektoren, die semantische Bedeutung erfassen, sind essenziell für verschiedenste Anwendungen wie Dokumentensuche, Textklassifikation und Fragebeantwortung. Während autoregressive Sprachmodelle wie GPT, die auf unidirektionaler Aufmerksamkeit basieren, lange als Standard galten, tritt mit zunehmender Forschung das Potenzial von Diffusionsmodellen hervor. Diese basieren auf einem völlig anderen paradigmatischen Ansatz und eröffnen spannende neue Möglichkeiten, insbesondere durch ihre bidirektionale Aufmerksamkeit. Diese Unterschiedlichkeit wirkt sich maßgeblich auf die Qualität der erzeugten Text-Embeddings aus und beeinflusst somit die Leistung in realen Anwendungsszenarien.
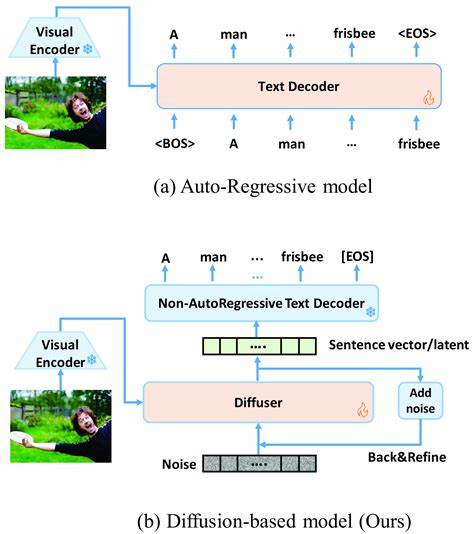
Autoregressive Modelle sind seit Jahren der Goldstandard in vielen NLP-Aufgaben. Ihre Architektur ist so konzipiert, dass sie das nächste Wort im Textsequenzverlauf vorhersagen, wobei die Aufmerksamkeit auf vorherige Tokens gerichtet ist. Dieses Prinzip bedingt eine unidirektionale Textverarbeitung, die zwar für generative Aufgaben ausgesprochen effektiv ist, aber bei der Erfassung des gesamten Kontexts eines Textes, insbesondere bei langen Dokumenten oder komplexen Texten, Schwächen zeigt. Für Aufgaben wie Text-Embedding, bei denen die Repräsentation eines Textes im Ganzen wichtig ist, erscheint dieser Fokus auf eine Text-Richtung als eine inhärente Einschränkung. Diffusionsmodelle hingegen zeichnen sich durch ihre bidirektionale Aufmerksamkeit aus, was bedeutet, dass sie den Text nicht sequenziell und nur in eine Richtung betrachten, sondern den Kontext sowohl vor als auch nach einem bestimmten Token einbeziehen können.
Diese Eigenschaft ist besonders wertvoll, wenn es darum geht, den globalen Kontext zu erfassen, der für ein tiefes Textverständnis entscheidend ist. In jüngsten Untersuchungen konnte gezeigt werden, dass Diffusionsmodelle bei Aufgaben mit langen Dokumenten oder anspruchsvollen reasoning-lastigen Retrievals deutlich bessere Ergebnisse erzielen als traditionelle LLM-basierte Embeddings. Die Verbesserung reicht hier von einem beachtlichen Zugewinn von 20 % bei der Langdokumentensuche bis hin zu etwa 8 % bei reasoning-intensiven Aufgaben. Ein weiterer Vorteil von Diffusionsmodellen ist ihre robuste Architektur, die durch den Prozess der schrittweisen Denoising-Simulation eine tiefere semantische Repräsentation generiert. Während autoregressive Modelle lediglich auf die Vorhersage der nächsten Token basieren, simulieren Diffusionsmodelle den Prozess, wie ein verrauschtes Eingabesignal Stück für Stück in den ursprünglichen, klaren Text zurückgeführt wird.
Diese Methode führt zu einem ganzheitlichen Verständnis des Textes und hilft dabei, semantische Verschachtelungen und komplexe Zusammenhänge besser zu erfassen. Die praktischen Auswirkungen dieser theoretischen Vorteile zeigen sich vor allem im Bereich des Dokumentenretrievals und der Informationssuche. Herkömmliche embedding-Modelle können bei kurzen Texten oder klar strukturierten Aufgaben bereits überzeugende Leistungen erzielen, treffen aber bei umfangreichen Dokumenten häufig an ihre Grenzen. Die bidirektionale Aufmerksamkeit der Diffusionsmodelle erlaubt es, wichtige Informationen, die an verschiedenen Stellen über das Dokument verteilt sind, gleichzeitig zu gewichten und in die Vektor-Repräsentation einzubeziehen. Dies erhöht die Treffgenauigkeit bei der Suche erheblich und erleichtert das Auffinden relevanter Informationen in großen, unstrukturierten Textsammlungen.
Allerdings sind Diffusionsmodelle nicht nur in Sachen Performance interessant, sondern auch hinsichtlich des Trainings- und Modellierungsprozesses. Die unidirektionale Struktur autoregressiver Modelle eignet sich gut für sequenzielle Trainingsstrategien und einfache Dekodierverfahren, was sie für viele Entwickler attraktiv macht. Diffusionsmodelle erfordern hingegen eine komplexere Trainingsphase, die den Prozess des Hinzufügens und anschließenden Entfernens von Rauschen simuliert. Dies führt zu einem höheren Rechenaufwand und stellt technische Herausforderungen dar, die im Hinblick auf Skalierbarkeit und Effizienz noch zu lösen sind. Trotz dieser Herausforderungen sind Diffusionsmodelle ein aufstrebender Ansatz, der gerade bei anspruchsvollen NLP-Anwendungen vielversprechend ist.
Die jüngsten Studien haben gezeigt, dass sie nicht nur mit den besten autoregressiven Modellen konkurrieren können, sondern in spezifischen Nischen, wie etwa bei reasoning-basierten Textretrievals, klare Vorteile aufweisen. Dies kann ein Wendepunkt sein, der die Art und Weise, wie Text-Embeddings konzipiert und genutzt werden, nachhaltig verändert. Die Zukunft der Text-Embedding-Technologie scheint daher zunehmend von hybriden Ansätzen geprägt zu sein, die die Vorteile beider Modelltypen kombinieren. Während autoregressive Modelle weiterhin ihre Stärke bei der Textgenerierung und -vervollständigung ausspielen, könnten Diffusionsmodelle die bessere Wahl für das Erfassen tiefgehender semantischer Beziehungen in umfangreichen und komplexen Texten sein. Fortschritte in der Modelloptimierung und verbessertes Verständnis der architektonischen Besonderheiten werden die Performance- und Effizienzkluft zwischen diesen Methoden weiter verringern.
Für Forscher, Entwickler und Unternehmen bedeutet dies, dass es wichtig ist, die jeweiligen Stärken der Modelle präzise zu evaluieren und sie in Abhängigkeit von der konkreten Anwendung auszuwählen. Insbesondere für Aufgaben mit Fokus auf Dialogsysteme oder kreative Textproduktion bleiben autoregressive Modelle weiterhin erste Wahl. Werden jedoch langformatige Texte analysiert oder semantisch komplexe Such- und Retrievalsysteme entwickelt, gewinnen Diffusionsmodelle zunehmend an Bedeutung. Abschließend lässt sich festhalten, dass die Gegenüberstellung von Diffusions- und autoregressiven Sprachmodellen aus Sicht der Text-Embeddings eine spannende Entwicklung im Bereich der KI darstellt. Die bidirektionale Architektur der Diffusionsmodelle ergänzt traditionell eingesetzte Methoden durch ein besseres Erfassen globaler Zusammenhänge, was für die zukünftige Forschung und Praxis einen Mehrwert erzeugt.
Die Wahl des richtigen Modells ist dabei entscheidend, um die jeweiligen Anforderungen optimal zu erfüllen und die bestmögliche Leistung zu erzielen. Die Kombination aus theoretischem Fortschritt und praktischen Anwendungsmöglichkeiten macht dieses Forschungsfeld zu einem der dynamischsten und innovativsten in der Welt der natürlichen Sprachverarbeitung.