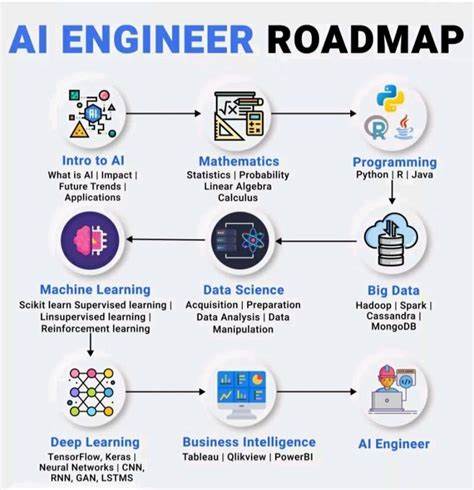
Die rasante Entwicklung im Bereich der Künstlichen Intelligenz hat insbesondere durch Große Sprachmodelle (Large Language Models, LLMs) eine neue Ära eingeleitet. Diese modernen KI-Systeme prägen inzwischen zahlreiche Anwendungen, von Chatbots über Textgenerierung bis hin zu komplexen Entscheidungsprozessen. Doch der Einstieg in das Lernen und Verstehen dieser Technologien ist komplex und erfordert eine systematische Herangehensweise. Eine strukturierte Lernroadmap kann helfen, die zugrundeliegenden Prinzipien, Techniken und Anwendungsmöglichkeiten von LLMs tiefgreifend zu erfassen und so kompetent mit der Technologie umzugehen.Zu Beginn steht das Verständnis der fundamentalen Bausteine von großen Sprachmodellen.
Tokenisierung ist eine der ersten Stufen, bei der Text in kleinere Einheiten zerlegt wird. Hier kommen Methoden wie Byte Pair Encoding (BPE) zum Einsatz, die es ermöglichen, Wörter und Wortbestandteile effizient zu kodieren. Der nächste essenzielle Schritt ist die Einbettung (Embedding) von Wörtern in einen mathematischen Raum, sodass semantische Beziehungen zwischen Begriffen modelliert werden können. Besondere Bedeutung kommt anschließend dem Attention-Mechanismus zu, der erlaubt, relevante Teile eines Textes kontextabhängig zu fokussieren. Varianten wie Multi-Head Attention (MHA) und Gated Attention (GQA) sorgen für noch bessere Modellierung komplexer Zusammenhänge.
Normierungsverfahren wie Layer Norm oder neuere Ansätze wie RMS Norm stabilisieren die Trainingsprozesse und verbessern die Leistung substantiell.Neben einzelnen Bausteinen prägt die Architektur des Modells und die Decodierungsstrategien den Erfolg eines LLMs entscheidend. Techniken wie Positional Encoding – mit Ansätzen wie Rotary Positional Encoding (RoPE) – vermitteln dem Modell ein Verständnis für die Reihenfolge von Token, was für natürliche Sprachverarbeitung von großer Bedeutung ist. Die Art und Weise, wie ein Modell beim Generieren von Texten vorgeht, lässt sich durch verschiedene Decoding-Strategien steuern, darunter Top-K Sampling, Top-P (Nucleus) Sampling und Temperature Scaling, die die Vielfalt und Kohärenz der erzeugten Texte beeinflussen.Das Vortraining (Pre-training) großer Sprachmodelle ist eine komplexe Phase, die oft auf riesigen Datenmengen basiert.
Ziel ist es, dem Modell grundlegende Sprachfähigkeiten beizubringen, die in vielen Anwendungsfällen wiederverwendet werden können. Verschiedene Scheduler und Trainingsmethoden helfen dabei, Effizienz und Effektivität zu maximieren. Wichtige Qualitätskontrollen erfolgen durch Evaluationsverfahren, die sicherstellen, dass das Modell nicht nur Muster lernt, sondern auch generalisierbar bleibt. Zusätzlich gibt es das Konzept des Continued Pre-training, bei dem Modelle nach der ersten Trainingsphase weitertrainiert werden, um neue Daten oder Domänen besser zu berücksichtigen.Nach dem Pre-training folgt die Post-Training-Phase, in der die Modelle finetuned und spezialisiert werden.
Supervised Fine-Tuning ermöglicht es, mit gelabelten Daten spezifische Fähigkeiten zu erlangen, während Verstärkendes Lernen, insbesondere Reinforcement Learning from Human Feedback (RLHF), eine Schlüsselrolle einnimmt, um Modelle noch menschennäher und anwendungsfreundlicher zu gestalten. Algorithmen wie Proximal Policy Optimization (PPO) verbessern die Lernstabilität, und neuere Verfahren wie Direct Preference Optimization (DPO) erweitern die Möglichkeiten, menschliches Feedback direkt in das Training einfließen zu lassen.Die Vielfalt der populären LLM-Modelle zeigt die breite Entwicklung und Spezialisierung im Feld. Modelle wie BERT und seine Varianten haben die Grundlagen gelegt, während GPT-Serie die Textgenerierung revolutioniert hat. Andere wie PaLM, LLaMA, GLM, Qwen und DeepSeek zeigen unterschiedliche Ansätze und Schwerpunkte, sei es bezüglich Modellgröße, Sprachabdeckung oder Anwendungsszenarien.
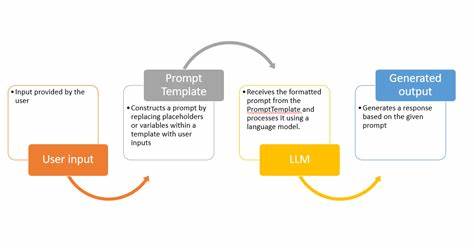
Auch sparsames Modelltraining mit Mixture of Experts (MOE) zeigt innovative Wege, Effizienz bei großen Modellen zu erreichen.Anwendungsbereiche für große Sprachmodelle sind heute vielfältig und beeinflussen viele Branchen. Die Kunst des Prompt Engineerings ist dabei zentral, da die Wahl und Gestaltung von Eingabeaufforderungen die Qualität der Ausgabe maßgeblich bestimmt. LLM-basierte Agenten erweitern die Einsatzmöglichkeiten, indem sie eigenständige Aufgaben im Dialog oder in komplexeren Abläufen übernehmen können. Auch Retrieval-Augmented Generation (RAG) verbindet Sprachmodelle mit externen Wissensquellen, um bessere und aktuellere Antworten zu liefern.
Besonders im Enterprise-Umfeld gewinnt diese Technologie durch praktische Implementierungen an Relevanz, da Unternehmen damit ihre internen Daten effizienter nutzbar machen können.Effizienz und Optimierung spielen eine große Rolle, da der Betrieb großer KI-Modelle hohe Anforderungen an Hardware und Software stellt. GPU-Nutzung und Latenzanalyse helfen dabei, Engpässe zu identifizieren und zu beheben. Innovationen wie FlashAttention verbessern die Berechnung der Aufmerksamkeitsmechanismen drastisch, während PagedAttention und Packing-Techniken das Training und die Inferenz noch ressourcenschonender gestalten. Parameter-Effizientes Fine-Tuning (PEFT) ermöglicht gezielte Anpassungen der Modelle mit deutlich reduzierter Rechenlast, was den Einsatz für kleinere Teams und Unternehmen erleichtert.
Neben Optimierung ist die Kompression von Modellen ein wichtiger Hebel, um Speicherbedarf und Laufzeitkosten zu reduzieren. Methoden wie Quantisierung, Pruning und Wissensdistillation komprimieren Modelle, ohne signifikant auf Leistung verzichten zu müssen. Dies macht den Einsatz von LLMs auch auf Edge-Geräten oder in ressourcenbeschränkten Umgebungen möglich.Praxisorientiertes Lernen ist für das Verständnis unverzichtbar. Open-Source-Lösungen wie nanoGPT bieten die Möglichkeit, von Grund auf ein GPT-Modell zu trainieren und tief in die Architektur einzutauchen.
Projekte wie das Instruction Fine-Tuning an kleineren Qwen-Modellen zeigen, wie sich LLMs spezifisch an Aufgaben anpassen lassen. OpenRLHF öffnet den Zutritt zu modernsten Trainingsverfahren mit menschlichem Feedback, anhand von Tutorials und Code-Analysen. Diese Hands-On-Erfahrungen sind unentbehrlich, um theoretisches Wissen in konkrete Fähigkeiten zu verwandeln und die Feinheiten moderner KI-Technologien zu begreifen.Literatur und technische Fachartikel zu LLMs bieten einen Fundus an tiefergehenden Erkenntnissen. Das Verständnis der technischen Berichte ermöglicht es, Innovationen wie neue Architekturvarianten, Trainingsverfahren oder Optimierungsansätze nachzuvollziehen und eigene Projekte entsprechend zu gestalten.
Durch das kontinuierliche Studium der neuesten Entwicklungen im Forschungsbereich bleiben Lernende up-to-date und können so die Potentiale der Künstlichen Intelligenz voll ausschöpfen.Abschließend lässt sich festhalten, dass der strukturierte Lernweg in die Welt der Großen Sprachmodelle ein vielseitiges Feld eröffnet, das sowohl theoretisches Fundament als auch praktische Anwendungen umfasst. Die Kombination aus grundlegenden Konzepten, aktuellen Trainings- und Optimierungsmethoden sowie praxisnahen Projekten bildet den Schlüssel, um moderne KI-Systeme nicht nur zu verstehen, sondern selbst aktiv gestalten und einsetzen zu können. Diese systematische Herangehensweise ist besonders wertvoll, um im dynamischen Umfeld der Künstlichen Intelligenz den Anschluss zu behalten und kompetent an der Zukunftstechnologie mitzuarbeiten.