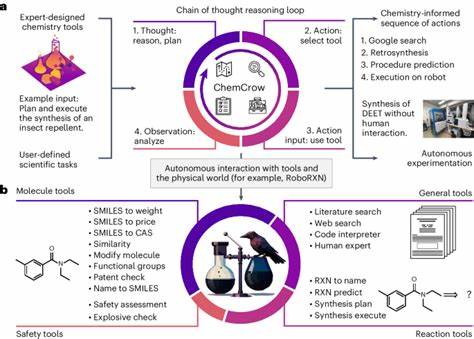
Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat das wissenschaftliche Umfeld nachhaltig verändert. Vor allem im Bereich der Chemie weckt die Fähigkeit dieser KI-Systeme, menschliche Sprache zu verarbeiten und komplexe Sachverhalte zu analysieren, großes Interesse. Experten, Studierende und Praktiker fragen sich zunehmend, inwiefern LLMs das Fundament chemischer Wissensvermittlung und Entscheidungsfindung verändern können und wie die Kompetenz dieser Modelle im Vergleich zu erfahrenen Chemikern einzuschätzen ist. Große Sprachmodelle basieren auf maschinellem Lernen und werden mit umfangreichen Textkorpora trainiert, die unter anderem wissenschaftliche Publikationen, Lehrmaterialien und Datenbanken einschließen. Durch aggressives Skalieren dieser Modelle konnten sie bemerkenswerte Fähigkeiten entwickeln, die es ihnen ermöglichen, nicht nur einfache Wissensfragen zu beantworten, sondern auch komplexe reasoningbasierte Aufgaben zu bewältigen.
Mit dem Aufkommen spezialisierter Evaluationsrahmen, wie dem kürzlich vorgestellten ChemBench, wurde die Leistungsfähigkeit der LLMs in der Chemie erstmals systematisch gemessen. ChemBench umfasst tausende sorgfältig kuratierte Frage-Antwort-Paare, die unterschiedliche Themen der Chemie abdecken und die Fähigkeiten der Modelle hinsichtlich Wissensabruf, logischem Denken, Berechnung und chemischer Intuition testen. Diese Fragen spiegeln realitätsnahe Probleme wider, die in Studium und Forschung auftreten und gehen dabei über einfache Multiple-Choice-Fragen hinaus und schließen auch offene Fragestellungen ein. Eine wichtige Erkenntnis aus den Evaluierungen mit ChemBench ist, dass die führenden Sprachmodelle im Durchschnitt besser abschneiden als menschliche Chemiker, die in einer vergleichbaren Studie getestet wurden. Dies überrascht zunächst und zeigt die enorme Rechen- und Datenverarbeitungsleistung moderner KI.
Besonders auf vielen Themengebieten, etwa der allgemeinen oder technischen Chemie, zeigen die Modelle eine beeindruckende Präzision. Gleichzeitig offenbaren sich aber deutliche Schwächen der Systeme, vor allem in Bereichen, die spezielles Wissen erfordern, wie etwa chemische Sicherheitsfragen, Toxizitätsbewertungen oder analytische Chemie. Dort sind die Sprachmodelle oft nicht in der Lage, korrekt und zuverlässig zu antworten. Ein Grund liegt darin, dass die Modelle in diesen Fällen kaum oder nur unzureichend trainierte Fakten verwenden können und auch externe Datenbanken, die spezifisches Expertenwissen beinhalten, bislang nicht integriert sind. Überraschend ist auch die Beobachtung, dass die Sprachmodelle Schwierigkeiten bei Aufgaben zeigen, die eine tiefgehende strukturelle Analyse chemischer Moleküle voraussetzen.
So können sie zum Beispiel nicht gut vorhersagen, wie viele Signale ein Molekül im Kernspinresonanzspektrum erzeugen wird, wenn lediglich seine SMILES-Darstellung (eine textuelle Form der Molekülbeschreibung) vorliegt. Diese Fähigkeit erfordert räumliches und topologisches Verständnis, das über reine Textinformationen hinausgeht. Menschliche Chemiker hingegen profitieren hier nicht nur von ihrem tiefen Verständnis, sondern oft auch von der Möglichkeit, chemische Strukturen visuell zu erfassen und intuitiv zu interpretieren. Die KI-Systeme müssen daher noch lernen, strukturelle Daten in für sie verständlicher Form zu verarbeiten. Auch bei der Abschätzung von chemischer Präferenz und Intuition, die zum Beispiel bei der Entwicklung von Wirkstoffen oder neuartigen Materialien eine Rolle spielt, liegen die Modelle meist deutlich hinter Experten zurück.
Menschliche Chemiker können auf Erfahrung und implizites Wissen zurückgreifen, während die KI oft nur auf statistische Wahrscheinlichkeiten basiert, die aus ihrem Trainingskorpus abgeleitet sind. Ein weiterer kritischer Punkt ist das Vertrauen in die Antworten der KI. Die Sprachmodelle sind oft übermäßig selbstsicher und können irreführende Ergebnisse liefern, ohne diese Unsicherheiten zu kennzeichnen. Die Fähigkeit der Systeme, ihre eigenen Grenzen zu erkennen und zu kommunizieren, ist begrenzt, was in sicherheitsrelevanten Bereichen wie der Chemie potenziell gefährlich sein kann. Hier besteht großer Bedarf an Verbesserungen, zum Beispiel durch Integration von Kalibrierungsmethoden oder Rückkopplungssystemen.
Neben den rein technischen Aspekten wirft der Einsatz von LLMs im chemischen Kontext auch pädagogische Fragen auf. Das bisherige Lernen in der Chemie liegt vielfach auf der Vermittlung von Faktenwissen, das jetzt von KI-Systemen leicht reproduziert und in einigen Fällen übertroffen wird. Das legt nahe, dass sich Lehr- und Prüfungsformen ändern müssen, um stärker auf kritisches Denken, kreatives Problemlösen und vertieftes Verständnis zu setzen. Die Zukunft der Chemieausbildung könnte daher in einer engeren Zusammenarbeit von Mensch und Maschine liegen, wobei LLMs als unterstützende „Co-Piloten“ dienen. Ebenso zeigen die Ergebnisse, dass trotz der gegenwärtigen Stärken der Sprachmodelle der Bedarf an maßgeschneiderten Trainingsdaten und Domain-spezifischer Einbindung von Fachwissen groß ist.
Im Gegensatz zu modellübergreifenden, generischen Daten sind wissenschaftliche Fakten oft in spezialisierten Nachschlagewerken, Datenbanken oder Laborergebnissen verankert, die noch effizienter für die KI nutzbar gemacht werden müssen. Dies schließt auch sichere und ethische Nutzungspraktiken ein, um Missbrauchspotenziale zu minimieren. Zahlreiche fortschrittliche Anwendungen stehen am Horizont: Von der schnelleren Literaturrecherche, der automatisierten Interpretation komplexer Messergebnisse bis hin zur autonomen Planung und Durchführung chemischer Synthesen kann KI die Arbeitswelt von Chemikern revolutionieren. Dennoch sind Modelle wie GPT-4 und Co. heute eher Werkzeuge mit beeindruckendem Potenzial als vollständig verlässliche Experten.
In der wissenschaftlichen Gemeinschaft besteht daher ein breites Interesse an der Weiterentwicklung und offenen Bewertung dieser Technologien. Frameworks wie ChemBench sind hierbei essenziell, da sie Vergleichbarkeit ermöglichen, Fortschritte sichtbar machen und die Kommunikation zwischen KI-Entwicklern, Chemikern und Pädagogen fördern. Zusammenfassend lässt sich sagen, dass große Sprachmodelle die Chemie bereits heute auf vielen Gebieten unterstützen können und oft auf dem Niveau erfahrener Fachleute performen. Ihre Stärken liegen im umfassenden Zugriff auf Informationen und der schnellen Verarbeitung. Andererseits zeigen sie Schwächen bei strukturellem Verständnis, spezialisierter Wissensanwendung und der Einschätzung der eigenen Verlässlichkeit.
Für die praktische Anwendung, Forschung und Ausbildung bedeutet dies, dass KI-gestützte Systeme zwar mächtige Helfer sind, menschliche Expertise aber weiterhin unverzichtbar bleibt. Die Zukunft der Chemie wird daher durch eine enge Symbiose von maschinellem Lernen und menschlichem Denken geprägt sein. Diese Partnerschaft birgt enormes Potenzial, nicht nur die Produktivität und Kreativität zu steigern, sondern auch neue Wege der Wissensgenerierung zu eröffnen, die bislang undenkbar waren. Kritisches Denken, ethische Verantwortung und technische Innovation müssen dabei Hand in Hand gehen, um das volle Potenzial dieser faszinierenden Technologie zu entfalten.