In der heutigen digitalen Welt gewinnt die strukturierte Datenextraktion aus Webseiten und Dokumenten zunehmend an Bedeutung. Unternehmen, Entwickler und Datenanalysten stehen häufig vor der Herausforderung, relevante Informationen aus unstrukturierten oder semi-strukturierten Quellen wie HTML oder Markdown effizient und akkurat zu extrahieren. Hier setzt ein robuster LLM-Extractor in TypeScript an, der mithilfe von Large Language Models (LLMs) eine neue Ära der Datenextraktion einläutet und dabei höchste Flexibilität sowie Leistungsfähigkeit vereint. Die Grundlage des Extractors bildet die Fähigkeit, HTML-Inhalte zunächst in eine kontrollierte, sauber formatierte Markdown-Form umzuwandeln. Diese Zwischenschritt führt zu einer wesentlich LLM-freundlicheren Darstellung, die komplexe HTML-Strukturen vereinfacht und den Fokus auf den eigentlichen Textinhalt legt.
Optional kann sich der Prozess auf den Hauptinhalt einer Seite konzentrieren, wodurch irrelevante Navigationselemente, Footer und Header ausgefiltert werden. Dies ist besonders hilfreich bei der Analyse von Blogartikeln, Nachrichtenwebseiten oder Produktbeschreibungen, bei denen der zentrale Inhalt schnell verfügbar sein muss. Das eigentliche Herzstück bildet die Interaktion mit leistungsfähigen LLMs, wie beispielsweise Google Gemini oder OpenAI GPT-Modelle. Diese werden mit definierten Zod-Schemata angesteuert, die genau vorgeben, welche Datenstrukturen aus dem Text extrahiert werden sollen. Das ermöglicht eine hochpräzise und semantisch fundierte Gewinnung von Informationen, etwa Artikelüberschriften, Autoren, Datumsangaben, Produktpreisen oder Links.
Dabei ist der Extraktor nicht darauf angewiesen, dass die Webseiten eine standardisierte Struktur aufweisen, sondern versteht auch natürliche Sprachkontexte und unterschiedliche Formatanordnungen. Änderungen im Layout oder in der HTML-Struktur führen somit nicht sofort zum Ausfall der Extrahierung. Ein entscheidender Vorteil des LLM-Extractors ist seine eingebaute Methode zur JSON-Sanitierung. Da LLM-Generierungen gelegentlich unvollständig oder fehlerhaft ausfallen können, sorgt dieser Schritt dafür, dass nur valide und zum Schema passende Daten übernommen werden. Fehlerhafte Einträge werden automatisch korrigiert oder aussortiert, was die Robustheit und Zuverlässigkeit enorm steigert.
Besonders bei geschachtelten Datenstrukturen mit Arrays und verschachtelten Objekten kommt diese Funktion stark zum Tragen. Die Validierung und Behandlung von URLs ist ein weiterer integraler Baustein. Alle extrahierten Links werden auf ihre Gültigkeit überprüft. Auch besondere Fälle wie relative Pfade werden durch den zugehörigen Quell-URL-Kontext auf absolute Links erweitert. Selbst komplexe Fälle mit Markdown-escaped Sonderzeichen werden intelligent bereinigt.
Mit dieser Art der Linkvalidierung wird sichergestellt, dass extrahierte Webadressen tatsächlich verwendbar sind und keine fehlerhaften oder nicht existierenden Ressourcen referenzieren. Die Flexibilität des Systems spiegelt sich auch in der Unterstützung verschiedener Formate wider. Neben HTML können auch reine Markdown- oder Textquellen verarbeitet werden. Hierbei passt sich der Extraktor automatisch der Input-Art an und liefert stets das optimal strukturierte Ergebnis. So profitieren Entwickler von einem universellen Werkzeug, das unterschiedliche Content-Quellen bedient, ohne dass für jedes Format ein eigenes Tool benötigt wird.
Damit der Extraktionsprozess möglichst präzise und kontextsensitiv erfolgt, bietet das Tool die Möglichkeit, einen zusätzlichen Extraktionskontext einzubringen. Dieser Kontext kann neben Metadaten wie URL, geografischem Standort oder Zeitstempeln auch teilweise bekannte Strukturdaten umfassen. Das LLM kann so basierend auf ursprünglichem Content plus Kontextdaten weitere fehlende Informationen ergänzen oder bestehende Einträge verfeinern. Dieses Feature eröffnet Anwendern die Chance, komplexe Use Cases abzudecken, bei denen mehrere Datenquellen miteinander verbunden und angereichert werden sollen. Ein weiteres wesentliches Merkmal ist die optionale Anpassung des zugrunde liegenden LLM-Anbieters sowie die Steuerung der Tokenbegrenzung.
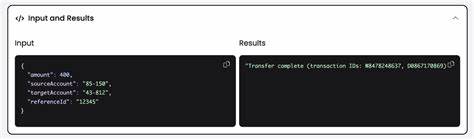
Tokenlimits sind wichtig, um Kosten zu kontrollieren und die maximale Eingabekapazität der Modelle nicht zu überschreiten. Die Entwickler können somit selbst steuern, wie umfangreich der gesendete Text sein darf, und zwischen verschiedenen Anbietern wie Google Gemini oder OpenAI wechseln. Durch die Unterstützung von Umgebungsvariablen und direkten API-Schlüsseln werden Sicherheit und Flexibilität in der Produktivumgebung bestmöglich gewährleistet. Der praktische Einsatz des Tools ist einfach und intuitiv. In wenigen Zeilen Code definieren Entwickler ein Zod-Schema, übergeben den zu analysierenden HTML- oder Markdown-Content, und erhalten als Antwort ein valides, strukturiertes JavaScript-Objekt, ergänzt um Tokenverbrauchsstatistiken.
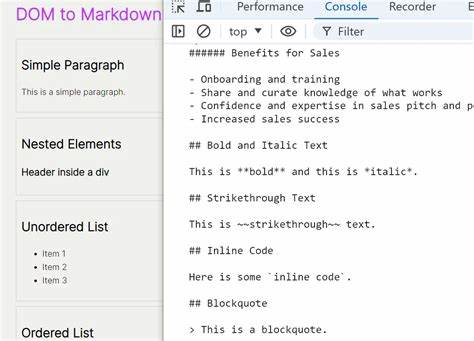
So lassen sich beispielsweise Blogartikel inklusive Titel, Autoren, Tags und Links auslesen oder Produktlisten mit Preisen, Verfügbarkeiten und Bildern erfassen. Selbst komplexe Fälle, in denen nur Teile der Daten initial bekannt sind, lassen sich durch die Kontextoption elegant umsetzen. Darüber hinaus ermöglicht die Bibliothek die direkte Konvertierung von HTML zu Markdown ohne Extraktionsschritt. Diese Funktion ist nützlich, wenn Entwickler einfach eine saubere Markdown-Basis benötigen, um sie in andere Systeme einzuspeisen oder weiterzuverarbeiten. Optionen erlauben es, mit oder ohne Bilder zu konvertieren und gleichzeitig relative URLs in absolute umzuwandeln.
Damit bleibt man flexibel und kann die gleiche Codebasis vielseitig nutzen. Für professionelle Anwendungen existieren umfassende Testsuites, die sowohl Unit- als auch Integrationstests umfassen. Letztere prüfen die Funktionalität mit echten LLM-APIs und stellen die Kompatibilität zwischen Google Gemini und OpenAI sicher. Die Tests gehen bis ins Detail, beispielsweise bei der HTML-zu-Markdown-Konvertierung mit und ohne Bilder oder bei der Validierung der Schrittabläufe. Dies gewährleistet eine langfristige Stabilität und Zuverlässigkeit der Lösung, auch wenn APIs oder Modelle sich weiterentwickeln.
Wer den Sprung in produktivere Umgebungen machen möchte, kann die Lösung auch in Kombination mit dem Cloud-Service lightfeed.ai verwenden. Dieser bietet erweiterte Features wie dedizierte Datenbanken, automatische Dubletten-Erkennung, KI-gestützte Datenerweiterung und automatisierte Workflow-Pipelines. Das Produkt richtet sich an Unternehmen, die strukturierte Webdaten in großen Mengen verwalten und analysieren möchten. Zusammenfassend ist der robuste LLM-Extractor für HTML und Markdown in TypeScript ein innovatives und zeitgemäßes Werkzeug, das viele Herausforderungen der modernen Datenextraktion löst.