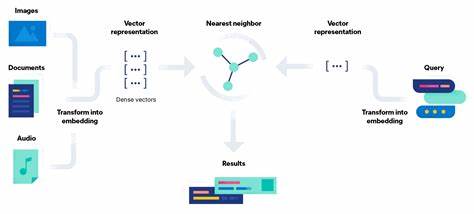
Die Suche in Datenbanken mit Milliarden von hochwertigen Vektor-Embeddings war lange eine Herausforderung, die große Rechenressourcen und komplexe Infrastruktur erforderte. Mit wachsender Bedeutung von künstlicher Intelligenz und maschinellem Lernen ist die effiziente Verarbeitung enormer Datenmengen allerdings zu einem zentralen Erfolgsfaktor geworden. CoreNN, ein neues Open-Source-Tool, präsentiert sich als bahnbrechende Lösung, die es erlaubt, eine Milliarde Vektoren auf einer einzigen Maschine in beeindruckenden 15 Millisekunden zu durchsuchen – und das unter Einsatz von kostengünstigem Flash-Speicher statt teurem RAM. Dieses Konzept eröffnet völlig neue Möglichkeiten für Unternehmen und Entwickler, die leistungsfähige semantische Suchsysteme realisieren wollen, ohne dafür teure Serverfarmen betreiben zu müssen. Traditionell basieren viele Vektor-Datenbanken auf Algorithmen wie HNSW (Hierarchical Navigable Small World Graphs), die zwar in Sachen Performance überzeugend sind, aber erhebliche Einschränkungen mit sich bringen.
Eine Milliarde Embeddings im gängigen 768-dimensionalen Format beanspruchen dabei ungeheure 2,8 Terabyte an RAM. Das Manipulieren, Updaten oder Löschen von Daten ist meist nur als nachträgliche Filterung möglich, was dazu führt, dass Indices immer weiter wachsen und der Speicherverbrauch sowie die Komplexität der Infrastruktur dramatisch zunehmen. CoreNN verfolgt einen völlig anderen Ansatz, der nicht nur die Speicherkosten drastisch senkt, sondern auch die Flexibilität im Umgang mit Daten und Abfragen deutlich erhöht. Der Schlüssel zum Erfolg von CoreNN liegt im konsequenten Einsatz von Flash-Speicher anstelle von volatilen und teuren DRAM-Modulen. Die Kosten für Flash-Speicher sind um ein Vielfaches günstiger – zwischen 40- bis 100-mal im Vergleich zu klassischen RAM-Installationen.
Dabei ermöglicht CoreNN, dass die gesamte Datenbank von einer einzigen Maschine verwaltet werden kann, ohne an Geschwindigkeit einzubüßen. Die Technologie baut auf einem nachhaltig optimierten Graph-Suchalgorithmus namens Vamana auf, sowie auf den in den wissenschaftlichen Arbeiten DiskANN und FreshDiskANN vorgestellten Konzepten. Die Architektur von CoreNN ist dabei so gestaltet, dass sowohl die Vektoren als auch ihre Verbindungen (Nachbarschaftsdaten) effizient und dauerhaft in einem Key-Value-Datenbanksystem namens RocksDB gespeichert werden. RocksDB bietet eine robuste und performante Basis, um komplexe Datenstrukturen auf der Festplatte abzulegen, ohne die Abfragegeschwindigkeit zu stark zu beeinträchtigen. Im Gegensatz zu Alternativen wie LMDB punktet es hier durch geringere Speicherüberkopfkosten und stabile API-Implementierung, die gut skaliert.
CoreNN nutzt dabei eine smarte Speicherverwaltung, die zwischen zwei Betriebsmodi wechselt. Im ersten Modus werden alle Vektoren und Knoten vollständig im RAM gehalten, was optimale Abfragegeschwindigkeit und Genauigkeit ermöglicht. Sobald allerdings die Größe an Speichergrenzen stößt, wechselt das System automatisch und nahtlos in den On-Disk-Modus, bei dem die Daten primär von der Festplatte gelesen werden. Dabei verbleiben jedoch komprimierte Versionen der Vektoren im Speicher, um eine möglichst schnelle Distanzberechnung während der Suche zu gewährleisten. Dieser duale Ansatz erlaubt es CoreNN, sowohl kleine als auch extrem große Datensätze mit gleicher Qualität zu bedienen, ohne dass die Nutzer manuell eingreifen oder komplizierte Konfigurationen vornehmen müssen.
Eine der größten Herausforderungen bei datenbankgestützter Vektorsuche sind sogenannte Backedges – also Rückkanten, die während der Aktualisierung und Einfügung von neuen Vektoren den Index komplizierter machen und zu einer Vervielfachung der Schreiboperationen führen können. Während Studien wie FreshDiskANN vorgehen, indem sie temporäre In-Memory-Grafen erzeugen, die nach und nach zusammengeführt werden, verfolgt CoreNN einen effizienteren Weg: Damit Schreibaufwände nicht explodieren, werden zusätzliche Nachbarn separat gespeichert. Dieses clevere Delta-System verhindert das häufige Komplett-Umschreiben von Nachbarschaftslisten und schont so die begrenzte Anzahl von IOPS (Input/Output Operations Per Second) einer Festplatte. Eine dynamische Obergrenze für die Anzahl von Nachbarn ermöglicht es außerdem, den Rechenaufwand für Optimierungen zu steuern, ohne dass dies negative Folgen für die Trefferqualität bei der Suche nach sich zieht. Wichtige Grundlage für die Gedächtniseffizienz von CoreNN bilden sogenannte Produkt-Quantisierungstechniken.
Dabei werden die hochdimensionalen Float-Vektoren in kleinere Teilbereiche zerlegt und anschließend jeweils in Cluster gegliedert. Statt die originalen 32-bit Fließkommadaten zu speichern, reicht ein Index auf den entsprechenden Cluster, was den Speicherbedarf drastisch verringert. So können Vektoren um den Faktor 32 komprimiert werden und dennoch entfallen die wesentlichen semantischen Eigenschaften, die für eine erfolgreiche Ähnlichkeitssuche nötig sind. Diese Kompressionsmethode wird kombiniert mit Unterstützung für niedrigere Genauigkeitsformate wie float16 und sogar binäre Quantisierung, die trotz reduzierter Präzision überraschend gute Ergebnisse bei Text-Embeddings erzielen. Die geringere Grundgenauigkeit wird dabei durch die hohe Anzahl von Dimensionen und die smarten Algorithmen ausgeglichen.
Ein weiterer Vorteil von CoreNN liegt in der einfachen und ubiquitären Nutzbarkeit. Als einzelnes Binary mit einer REST-API kann die Lösung kinderleicht in unterschiedlichste Anwendungen integriert werden – von embedded Bibliotheken für Forschung und schnelle Prototypen bis hin zu stabilen Produktivsystemen in der Cloud oder auf Firmeninfrastruktur. Programmiersprachen wie Node.js, Python und Rust sind derzeit unterstützt, weitere Bindings befinden sich in Entwicklung. Diese Flexibilität macht CoreNN zum SQLite der semantischen Suche, das im Vergleich zu komplexen und fragmentierten Multi-Maschinen-Clustern deutlich schlanker und wartungsärmer daherkommt.
Bei der Implementierung verzichtet CoreNN bewusst auf den anfänglichen Plan, komplett asynchron in Rust zu arbeiten. Da RocksDB eine native C++-Bibliothek ist, entstehen durch asynchrone Abstraktionen häufig Ineffizienzen und Schwierigkeiten bei der Fehlerdiagnose oder Profilanalyse. Stattdessen setzt CoreNN auf eine optimierte synchrone Programmierung, die sich besser in Monitoring- und Debugging-Werkzeuge integrieren lässt und so Performance-Engpässe schneller identifizierbar macht. Durch die Kombination aus kosteneffizientem Storage, smarter Quantisierung, einem robusten Graphenmodell und innovativen Update-Strategien demonstriert CoreNN, dass es keine Unmöglichkeit ist, semantische Suche über eine Milliarde von Embeddings mit Spitzenlatenz auf einer einzigen, vergleichsweise bescheiden ausgestatteten Maschine durchzuführen. Für Entwickler und Unternehmen, die beispielsweise Social Media Analysen, Produktempfehlungen, oder KI-gestützte Suchmaschinen realisieren wollen, eröffnen sich hier völlig neue Horizonte ohne immense Hardware-Anschaffungen und kompliziertes Management.
Die Open-Source-Community ist eingeladen, an CoreNN mitzuwirken und das Projekt weiter voranzutreiben. Die offene Architektur und sorgfältig dokumentierte Codebasis helfen dabei, das System an individuelle Anwendungsfälle anzupassen oder neue Features zu entwickeln. So kombiniert CoreNN neueste Forschungserkenntnisse mit praktischer Nutzbarkeit und definiert die Messlatte für skalierbare, performante Vektor-Datenbanken neu. Zusammenfassend markiert CoreNN einen Paradigmenwechsel bei der Verarbeitung und Suche in hochdimensionalen Datensätzen im Bereich künstlicher Intelligenz. Die Technologie zeigt, dass Effizienz, Skalierbarkeit und Nutzerfreundlichkeit keine Gegensätze sein müssen.
Stattdessen können sie Hand in Hand gehen und so Innovationen ermöglichen, die bisher nur mit großem technischem Aufwand erreichbar waren. Die Fähigkeit, Milliarden von Vektoren mit minimalem Hardwareaufwand zu handhaben, wird Auswirkungen auf viele Bereiche haben – von der Forschung über die Datenanalyse bis zu kommerziellen KI-Anwendungen – und die Art und Weise, wie wir Informationen suchen und finden, grundlegend verändern.