Google Cloud Bigtable gehört zu den führenden NoSQL-Datenbanken weltweit und zeichnet sich durch Skalierbarkeit, hohe Performance und Kompatibilität mit Cassandra und HBase aus. Mit über 5 Milliarden Anfragen pro Sekunde und mehr als 10 Exabyte verwalteter Daten steht Bigtable für eine leistungsfähige, stabile und verlässliche Datenbasis in Unternehmen verschiedenster Branchen. Kürzlich wurden bedeutende Verbesserungen veröffentlicht, die eine Steigerung der Single-Row-Read-Durchsatzleistung um 70 % ermöglichen. Dieser enorme Fortschritt ist nicht nur eine technische Meisterleistung, sondern hat auch weitreichende Auswirkungen auf die Effizienz und Kostenstruktur von Bigtable-Anwendern. Doch wie genau wurde diese Leistungssteigerung realisiert und was bedeutet das für Entwickler sowie Unternehmen? Im Folgenden wird ein umfassender Überblick über die maßgeblichen Optimierungen, die zugrunde liegende Technik und konkrete Anwendungsbeispiele gegeben.
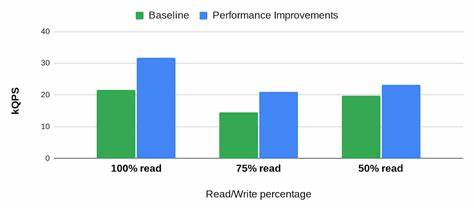
Die Bedeutung von Single-Row-Reads liegt in ihrer weitverbreiteten Nutzung. Viele Anwendungen und Dienste greifen punktgenau auf einzelne Zeilen einer Datenbanktabelle zu, weshalb eine effektive Verarbeitung dieser Zugriffe maßgeblich die Gesamtperformance beeinflusst. Bigtable hat durch kontinuierliche Forschung und Entwicklung bereits zuvor Verbesserungen von 20 bis 50 % bei der Single-Row-Leseleistung erzielt. Die jüngsten Innovationen ermöglichen nun eine zusätzliche Steigerung von 50 %, sodass die Gesamtverbesserung beim Durchsatz im Vergleich zu früheren Versionen beeindruckende 1,7-fach beträgt. Damit kann Bigtable heute bis zu 17.
000 Punktleseoperationen pro Sekunde ausführen – eine neue Benchmark für Datenbanken dieser Klasse, die ohne Mehrkosten für Endnutzer zur Verfügung steht. Zentrale Grundlage dieser Fortschritte ist ein vielschichtiger Ansatz, der mehrere Verbesserungsbereiche miteinander kombiniert. Ein wesentlicher Faktor ist die Weiterentwicklung des Caching-Systems, das bei Bigtable eine entscheidende Rolle bei der Reduzierung der Latenz und Steigerung der Durchsatzleistung spielt. Traditionell basierte das Caching darauf, Datenblöcke (SSTables) im Arbeitsspeicher zwischenzuspeichern, um die kostspieligen Zugriffe auf das Speichersystem Colossus zu verringern. Allerdings stellte sich heraus, dass diese Blockebene bei bestimmten Zugriffsmustern, wie häufig abgefragten einzelnen Zeilen oder bei Zeilen mit vielen Spalten über mehrere Blöcke verteilt, die Leistung begrenzt.
Die Verarbeitung der gesamten Datenblöcke verbraucht unnötig Rechenressourcen und Zeit. Die Einführung eines sogenannten Zeilen-Caches (Row Cache) verbessert diese Situation erheblich, indem Daten jetzt auf Zeilenebene zwischengespeichert werden. Im Gegensatz zum bisherigen Block-Cache enthält der Row Cache nur die tatsächlich abgefragten Daten innerhalb einer Zeile und minimiert so den Umfang der verarbeiteten Informationen. Dadurch reduziert sich der CPU-Verbrauch bei Punktleseanfragen um bis zu 25 %. Diese sparsame und gezielte Zwischenspeicherung ermöglicht eine schnellere Antwortzeit und entlastet die Hardware erheblich.
Der Row Cache verwendet zudem eine clevere Speicheroptimierung, die Berücksichtigung der Zeilengröße und ein innovatives Auslagerungsverfahren umfasst, um eine hohe Trefferquote auch bei variierenden Anfragen zu gewährleisten. Neben der Caching-Lösung wurden auch die Abläufe innerhalb der Single-Row-Read-Pfade optimiert, um die Effizienz weiter zu erhöhen. Da Single-Row-Leseanfragen speziell von einem einzelnen Knoten bearbeitet werden, konnten hier unnötige Komplexitäten reduziert werden, die bei Bereichsabfragen entstehen. Optimierungen im Abfrageverarbeitungspfad und eine neue Zwischenschicht zur effizienteren Filterauswertung führten dazu, dass Filteroperationen zu etwa 50 % besser verarbeitet werden. In Kombination mit verbesserten Algorithmen und ressourcenschonenden Berechnungsmethoden ergab sich so eine deutliche Steigerung der Verarbeitungskapazität um ca.
12 %. Eine weitere Schlüsselinnovation betrifft die Priorisierung und das Scheduling der Anfragen. Bigtable unterstützt jetzt durch das Konzept der Anforderungsprioritäten (Request Priorities) eine fein abgestufte Steuerung, welche Anfragen mit höherer Dringlichkeit bevorzugt behandelt werden können. Anwender können für unterschiedliche Anwendungen oder Dienste Prioritäten zwischen hoch, mittel und niedrig vergeben. Dies führt insbesondere bei gemischten Workloads, wie Hybrid Transactional/Analytical Processing (HTAP), zu einer entscheidenden Verbesserung der Latenz und Durchsatzstabilität.
Transaktionale Einzelzeilenzugriffe, die in der Regel besonders schnell verarbeitet werden müssen, profitieren dabei von einer bevorzugten Ressourcenverteilung gegenüber komplexeren, langlaufenden analytischen Anfragen. Diese ausgewogene Ressourcenverteilung basiert darauf, dass besonders langlaufende Operationen an definierten Punkten unterbrochen und kurzzeitig zurückgestellt werden, um zeitkritischeren Punktanfragen ausreichend CPU-Zeit zu sichern. So wird verhindert, dass aufwändige Analysen die Reaktionszeit wichtiger Echtzeitzugriffe negativ beeinflussen. Das Scheduling passt sich kontinuierlich an das aktuelle Anfrageprofil an und kann dadurch dynamisch auf veränderte Anforderungen reagieren. Die Kombination dieser technischen Verbesserungen macht Bigtable in der Praxis flexibler und leistungsfähiger.
Unternehmen, die große Mengen strukturierter Daten nahezu in Echtzeit verarbeiten müssen, profitieren direkt von den neuen Möglichkeiten. Der zum Beispiel im Bereich Cybersecurity tätige Spezialist Stairwell managt mit Bigtable Tabellen mit über 328 Millionen Zeilen und bis zu 10.000 Spalten. Dabei gelingt es, eine durchschnittliche Leselatenz von nur 1,9 Millisekunden zu halten, während Spitzenlatenzen bei 4 Millisekunden liegen. Dies verdeutlicht die Effizienz und Skalierbarkeit der zugrunde liegenden Verbesserungen.
Auch Spotify, ein weiterer prominenter Anwender, berichtet von messbaren Vorteilen. Durch kontinuierliche Performance-Verbesserungen konnte die Anzahl der benötigten Knoten reduziert werden, was unmittelbar zu Kosteneinsparungen führt. Gleichzeitig profitieren ihre KI-basierten Empfehlungssysteme von der schnellen Datenverfügbarkeit, was die Nutzererfahrung deutlich steigert. Solche Praxisbeispiele unterstreichen den Mehrwert der technischen Fortschritte. Für Datenbankadministratoren und Entwickler bedeutet die Steigerung der Single-Row-Read-Durchsatzleistung, dass Anwendungen mit höherem Datenvolumen und mehr gleichzeitigen Zugriffen betrieben werden können, ohne dass weitere Hardware notwendig ist.
Die Möglichkeit, präzise Priorisierungen zu vergeben, erhöht zudem die Kontrolle und Ausfallsicherheit bei heterogenen Workloads. Mit Bigtable lassen sich Workloads heute flexibler gestalten und besser an die jeweiligen Anforderungen anpassen. Die Innovationskraft hinter diesen Fortschritten liegt in der stetigen Performance-Forschung bei Google. Anhand von umfangreichen Benchmarks, Analysen mit Profiling-Tools und realen Anwendungsfällen werden fortlaufend potenzielle Engpässe identifiziert und adressiert. Durch diesen iterativen Verbesserungsprozess werden sowohl neue als auch bestehende Features kontinuierlich optimiert, um eine zukunftssichere Infrastruktur zu gewährleisten.