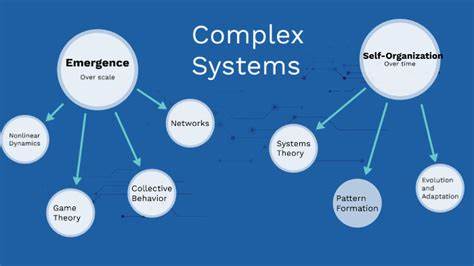
Im heutigen Zeitalter, in dem Technologien rasant wachsen und Systeme immer umfangreicher werden, gewinnt das Arbeiten mit komplexen Systemen zunehmend an Bedeutung. Aus meiner Erfahrung als Site Reliability Engineer (SRE) bei Google habe ich wertvolle Erkenntnisse gewonnen, die zeigen, wie man effektiv mit der scheinbaren Unvorhersehbarkeit und Vielschichtigkeit von komplexen technischen Umgebungen umgeht. Die Herausforderung besteht dabei weniger darin, wiederkehrende Prozesse zu automatisieren oder strukturierte Probleme zu lösen – vielmehr verlangt die Komplexität ein tiefes Verständnis der Dynamiken, die solche Systeme prägen, und ein Umdenken hinsichtlich üblicher Lösungsansätze. Ein grundlegender Schritt besteht darin, den essenziellen Unterschied zwischen komplizierten und komplexen Problemen zu verstehen. Komplizierte Probleme sind durch definierte Abläufe gekennzeichnet, die zwar technisch anspruchsvoll sein können, jedoch mit wiederholbaren und vorhersehbaren Methoden bewältigbar sind.
Ein Beispiel hierfür wäre das Einreichen von Steuererklärungen oder gewisse Optimierungen im Bereich der Routenplanung bei Fahrdiensten, wie ich sie zuvor bei einem Uber-Konkurrenten mitgeoacht habe. Die Herausforderungen hier sind hoch, aber das Gebiet ist begrenzt und gemessen an den Ergebnissen stabil reproduzierbar. Komplexe Probleme hingegen zeichnen sich durch Vielfalt, Einzigartigkeit und oftmals emergente Eigenschaften aus. Typischerweise sind diese Situationen geprägt von Wechselwirkungen, die nicht vollständig vorhersehbar sind und sich nicht auf bekannte Pfade zurückführen lassen. Maßnahmen, die in einem Teilbereich Erfolg versprechen, können an einer anderen Stelle unerwartete Nebenwirkungen hervorrufen oder gar das Gesamtsystem destabilisieren.
Die Arbeit an diesen Systemen erfordert Flexibilität, kreative Lösungsansätze und eine ständige Anpassung an neue Erkenntnisse. Bei Google arbeite ich speziell an den Systemen, die das maschinelle Lernen (ML) auf globaler Ebene ermöglichen. Hier zeigt sich Komplexität in ihrer reinsten Form. Die Infrastruktur muss enorme Datenmengen in Echtzeit verarbeiten, dynamisch Ressourcen verwalten und sich gleichzeitig an neue Anforderungen anpassen. Diese Herausforderungen gehen weit über die reine technische Umsetzung hinaus und erfordern es, Zusammenhänge zu erkennen, die sich oft erst im Betrieb offenbaren.
Eine der charakteristischen Eigenschaften komplexer Systeme ist das sogenannte Emergenzverhalten. Dabei entstehen Verhaltensweisen oder Effekte, die sich nicht allein aus den einzelnen Komponenten ableiten lassen. Ein Beispiel aus meiner Arbeit ist das unerwartete Verhalten von Gemini, einem ML-System, dessen Ergebnis sich nicht durch die Analyse aller Einzelkomponenten vorhersehen ließ. Solche Phänomene erschweren die Fehlerdiagnose erheblich, da ein isoliertes Betrachten einzelner Module nicht ausreicht, um das Gesamtbild zu verstehen. Eng verbunden mit Emergenz sind verzögerte Konsequenzen.
Aktionen in komplexen Umgebungen zeigen nicht unbedingt sofort ihre Auswirkungen, sondern diese können sich erst Tage oder Wochen später manifestieren. Dies macht die Ursachenforschung zu einer Herausforderung und verlangt Aufmerksamkeit über längere Zeiträume hinweg. Im täglichen Betrieb kann dies bedeuten, dass scheinbar harmlose Änderungen zeitverzögert zu Störungen führen, was wiederum die Stabilität der Systeme gefährden kann. Weiterhin ist die Trennung zwischen lokalem und globalem Optimum ein wichtiges Element in komplexen Systemen. Maßnahmen, die einzelne Systemteile optimieren, führen nicht zwangsläufig zu einer Verbesserung des Gesamtsystems.
Im Gegenteil, lokale Optimierungen können negative Rückkopplungen an anderen Stellen verursachen. Diese Wechselwirkungen machen es nötig, stets das große Ganze im Blick zu behalten und sorgfältig abzuwägen, wie Eingriffe wirken könnten. Ein weiterer Begriff, der in diesem Zusammenhang häufig auftaucht, ist Hysterese. Dabei beeinflusst der frühere Zustand eines Systems weiterhin sein Verhalten, auch wenn der ursprüngliche Auslöser bereits beseitigt wurde. Analog zum Verkehrsstau, der auch nach der Beseitigung eines Unfalls noch eine Weile anhält, zeigt sich Hysterese zum Beispiel in verteilten Systemen als anhaltende Latenz oder Überlast, die noch reagiert, obwohl die Ursache behoben scheint.
Komplexe Systeme sind zudem oft nichtlinear in ihrem Verhalten. Kleine Veränderungen können überproportional große oder gar unerwartete Auswirkungen haben, insbesondere wenn Schwellenwerte oder Kipppunkte erreicht werden. Diese Dynamik erschwert Vorhersagen auf Basis vergangener Daten und verlangt kontinuierliches Monitoring sowie Anpassungsfähigkeit bei Planungen und Entscheidungen. Angesichts dieser Herausforderungen ist der Umgang mit komplexen Systemen für mich als Ingenieur immer wieder eine Tugendveranstaltung zwischen Kontrolle und Anpassung. Die Wahl der richtigen Herangehensweise spielt eine herausragende Rolle.
So hat sich die Strategie bewährt, reversible Entscheidungen zu priorisieren, um schnelle Iterationen und Lernen zu ermöglichen. Das Konzept der sogenannten „Einweg-“ und „Zweiweg“-Entscheidungen, das unter anderem Jeff Bezos geprägt hat, verdeutlicht dabei, wann ein Risikomanagement mit Vorsicht und wann ein zügiges Handeln möglich ist. Ebenso wichtig ist die Definition von relevanten Metriken, die über einfache lokale Optimierungswerte hinausgehen und das System ganzheitlich bewerten. Ohne solch eine ganzheitliche Betrachtung besteht die Gefahr, dass scheinbare Erfolge einzelne Schwachstellen kaschieren und langfristig zu größeren Problemen führen. Innovation ist in komplexen Umgebungen nicht nur wünschenswert, sondern häufig essenziell.
Bei Google habe ich gelernt, dass es eine grundsätzliche Haltung braucht: Kein Problem ist per se unlösbar, wenn es Kreativität, Ressourcen und den Willen gibt, neue Wege zu gehen. Im Team werden unterschiedliche Sichtweisen eingebracht, um aus scheinbar ausweglosen Situationen heraus neue Lösungsansätze zu erarbeiten. Diese Offenheit für neue Denkweisen schafft den Raum, der in komplexen Systemen so dringend benötigt wird. Technisch gesehen ist eine kontrollierte Einführung von Änderungen entscheidend, um Risiken zu minimieren. Techniken wie Feature Flags, Canary Releases, progressive Rollouts oder Shadow Testing erlauben es, Eingriffe schrittweise zu erproben, ohne dass das gesamte System auf einmal beeinträchtigt wird.
Solche Praktiken ermöglichen es, Fehler schnell zu identifizieren und zurückzunehmen, bevor sie große Auswirkungen haben. Eine weitere zentrale Säule ist die Ausgestaltung umfassender Observability. Diese umfasst das Sammeln und Auswerten von Daten mit hoher Granularität und Vielfalt, so dass jeder Zustand eines Systems in Echtzeit verstanden und analysiert werden kann. Ohne eine solche Transparenz sind unerwartete Fehler schwer zu beheben, was wiederum den Innovations- und Verbesserungsprozess stark bremst. Simulationen sind eine hilfreiche Ergänzung bei der Steuerung komplexer Systeme.
Reale Betriebsdaten können dabei genutzt werden, um Szenarien offline zu reproduzieren und potenzielle Änderungen vorab zu testen. Deterministische Simulationen bieten die Möglichkeit, unter kontrollierten Bedingungen unterschiedliche Verhaltensweisen zu untersuchen. Die Kombination aus detaillierter Überwachung und Simulation schafft starke Feedbackschleifen, die helfen, Unsicherheiten zu reduzieren. Zusätzlich eröffnen Maschinelles Lernen und datengetriebene Ansätze immer größere Chancen im Umgang mit Komplexität. Im Gegensatz zu statischen Regelwerken ist ML in der Lage, sich kontinuierlich anzupassen und aus neuen Daten Muster zu erkennen, die vorher nicht explizit definiert waren.
Dies ermöglicht es, dynamisch auf Veränderungen zu reagieren und Entscheidungen auf Wahrscheinlichkeiten zu basieren, statt starren Wenn-Dann-Regeln zu folgen. Abschließend ist der Faktor Mensch nicht zu unterschätzen. Eine enge, offene und klare Zusammenarbeit im Team sorgt dafür, dass komplexe Sachverhalte verständlich kommuniziert werden und unterschiedliche Perspektiven eingebracht werden können. Gerade in unsicheren oder nichtlinear gelagerten Situationen ist es entscheidend, gemeinsam über Optionen zu reflektieren und fundierte Entscheidungen zu treffen. Die Arbeit an komplexen Systemen bei Google hat mir gezeigt, dass es weniger um das Beherrschen einzelner Technologien geht, als vielmehr um das Erkennen von Mustern, das Akzeptieren von Ungewissheiten und die Bereitschaft, zukunftsorientiert zu denken.
Die Kombination aus fundiertem Fachwissen, innovativen Methoden und einem gut abgestimmten Team schafft die Grundlage, um die Herausforderungen komplexer Umgebungen zu meistern und nachhaltige Lösungen zu entwickeln. Für jeden Profi in der Technologiebranche bietet dieses Verständnis nicht nur einen Leitfaden für die eigene Arbeit, sondern auch einen Wettbewerbsvorteil in einer Welt, die zunehmend von komplexen Systemen geprägt ist.