Die rasante Entwicklung im Bereich der Künstlichen Intelligenz hat insbesondere durch große Sprachmodelle (Large Language Models, LLMs) enorme Fortschritte ermöglicht. Diese Modelle sind darauf trainiert, menschliche Sprache zu verstehen, zu generieren und komplexe Aufgaben zu lösen. Doch trotz ihrer beeindruckenden Fähigkeiten sind sie auch enorm ressourcenintensiv – sowohl in Bezug auf den Trainingsaufwand als auch auf die benötigte Rechenkapazität. Ein vielversprechender Ansatz, um dem entgegenzuwirken, ist die Anwendung von Reinforcement Learning (RL) zur gezielten Steuerung und Optimierung kleiner Teilbereiche dieser umfangreichen Modelle. Dabei spielt die Feinabstimmung kleiner Subnetzwerke eine entscheidende Rolle.
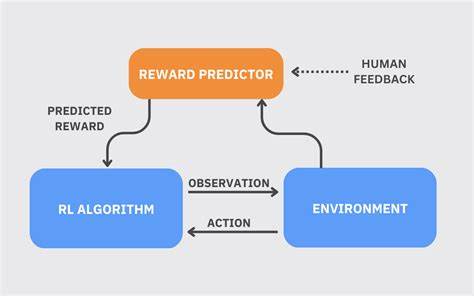
Dieser Ansatz hat das Potential, die Art und Weise zu verändern, wie Sprachmodelle trainiert und eingesetzt werden. Reinforcement Learning ist eine Lernmethode, bei der ein Agent durch Versuch und Irrtum lernt, optimales Verhalten zu entwickeln. In der Welt der Sprachmodelle bedeutet dies, dass das Modell durch Interaktionen, beispielsweise mit Benutzereingaben oder simulierten Aufgaben, belohnt wird, wenn es nützliche und korrekte Ergebnisse liefert. Diese Belohnungen werden genutzt, um die Parameter des Modells schrittweise zu verfeinern und die Leistungsfähigkeit zu steigern. Was hierbei jedoch faszinierend ist, ist der Umstand, dass diese Verbesserungen nicht durch eine vollständige Modifikation aller Parameter erreicht werden.
Stattdessen zielt Reinforcement Learning darauf ab, nur wenige spezifische Parameter, ein sogenanntes Subnetzwerk, anzupassen. Aktuelle Studien und Forschungsarbeiten, wie sie unter anderem in der Arbeit „Reinforcement Learning Finetunes Small Subnetworks in Large Language Models“ von Sagnik Mukherjee und Kollegen dargestellt sind, zeigen, dass nur zwischen fünf und dreißig Prozent der Parameter eines großen Sprachmodells tatsächlich durch RL verändert werden müssen, um bedeutende Leistungsfortschritte zu erzielen. Dies führt zu einem erheblichen Effizienzgewinn, denn der Großteil des Modells bleibt unberührt und kann seine ursprünglichen, durch Vortraining erlernten Fähigkeiten beibehalten. Diese Entdeckung hat weitreichende Konsequenzen für die Praxis und Anwendung großer Sprachmodelle. Zum einen können Rechenressourcen eingespart werden, da weniger Parameter bearbeitet und optimiert werden müssen.
Zum anderen wird das Anpassen und Feinjustieren von Modellen viel schneller und deutlich kostengünstiger. Insbesondere für Unternehmen und Entwickler, die maßgeschneiderte Lösungen auf Basis großer Sprachmodelle anstreben, eröffnet sich ein schnellerer und flexiblerer Weg, um Modelle auf spezifische Aufgaben oder Domänen zu spezialisieren. Eine weitere überraschende Erkenntnis ist, dass die kleinen Subnetzwerke, die durch Reinforcement Learning angepasst werden, bei unterschiedlichen Trainingsläufen, Startbedingungen und sogar verschiedenen RL-Methoden eine größere Übereinstimmung aufweisen als zufällig erwartet. Das legt nahe, dass es offenbar bestimmte kritische Parameterbereiche im Modell gibt, die besonders wichtig für eine zielgerichtete Anpassung sind. Die Auswahl dieser Parameter erfolgt dabei nicht willkürlich, sondern folgt einer inhärenten Struktur des Modells und seiner Lernfähigkeit.
Interessant ist, dass sich diese Anpassungen nicht auf wenige einzelne Schichten im neuronalen Netzwerk beschränken. Stattdessen erhalten fast alle Parameterbereiche ähnliche, wenn auch sparsame Updates. Dieser breit gestreute, kleine Bereich an Veränderungen ist dennoch hochwirksam, da die Gradientenupdates, also die mathematischen Anpassungen der Parameter, nahezu vollrangig sind. Oder anders gesagt: Die kleinen Subnetzwerke, an denen Veränderungen vorgenommen werden, sind so gestaltet, dass sie den vollen Ausdrucksraum abdecken können, den die jeweiligen Parameter ursprünglich modellieren können. Dies ist ein Schlüsselaspekt für die hohe Effizienz und Effektivität des Prozesses.
Der Grund für diese sogenannte „Parameter-Update-Sparsity“ liegt offenbar darin, dass das Modell während der Optimierung mit Daten arbeitet, die nahe an der bestehenden Policy-Verteilung liegen. Das bedeutet, dass die RL-gesteuerten Anpassungen nicht radikal neue Verhaltensweisen generieren, sondern vielmehr sehr gezielt und subtil die bereits gelernten Fähigkeiten verfeinern. Techniken wie KL-Regulierung und Gradient-Clipping, die darauf abzielen, die Policy nahe am ursprünglichen Modell zu halten, haben dabei einen vergleichsweise geringen Einfluss. Das stützt die These, dass diese Feinabstimmung intrinsisch durch den Trainingsprozess selbst bedingt ist. Aus technischer Sicht bieten diese Ergebnisse neue Perspektiven für die Weiterentwicklung von Sprachmodellen.
Die Idee, nicht ganze gigantische Parameterfelder zu verändern, sondern gezielt kleine Bereiche zu optimieren, entspricht aktuellen Trends in der KI-Forschung, die auf Effizienz, Nachhaltigkeit und Skalierbarkeit abzielen. Denn die zunehmende Größe und Komplexität moderner Modelle bringt auch praktische Herausforderungen wie hohen Energieverbrauch und lange Trainingszeiten mit sich. Zwei der entscheidenden Faktoren für den Erfolg von RL-basierten Feineinstellungen kleiner Subnetzwerke sind demnach die Wahl geeigneter Trainingsdaten und das Design der Optimierungsalgorithmen. Angesichts dieser Entwicklung können Forscher und Entwickler künftig gezielter Modelle modifizieren, ohne sie komplett neu trainieren zu müssen. So können zum Beispiel bestehende Modelle in kundenspezifischen Anwendungen schnell an neue Anforderungen angepasst werden, ohne den gesamten Rechenaufwand eines Volltrainings zu verursachen.
Dies ist besonders wertvoll für Branchen mit hohen Sicherheits- oder Datenschutzanforderungen, wo Modelle oft nur in stark kontrollierten Umgebungen angepasst werden dürfen. Darüber hinaus zeigt diese Arbeit, dass Reinforcement Learning nicht nur zur Steigerung der Modellleistung auf Standardbenchmarks geeignet ist, sondern auch subtile Anpassungen ermöglicht, die das Verhalten von Sprachmodellen menschlicher und wertorientierter gestalten. Die Ausrichtung auf menschliche Werte und Normen ist eines der zentralen Anliegen moderner KI-Forschung, um ethisch verantwortungsbewusste Systeme zu schaffen. Die Tatsache, dass diese Ausrichtung im Rahmen einer sparsamen Parameterauswahl erfolgen kann, untermauert die Effizienz des RL-Ansatzes. Nicht zuletzt können diese Erkenntnisse die künftige Architekturgestaltung von Sprachmodellen beeinflussen.
Wenn bekannt ist, dass nur kleine Subnetzwerke angepasst werden müssen, könnten neue Modellarchitekturen gezielt auf eine modulare oder teilbare Struktur hin entwickelt werden. Dadurch ließen sich Feinabstimmungen noch gezielter durchführen und technische Hürden wie Overfitting oder unerwünschte Nebenwirkungen minimieren. Zusammenfassend ist die Feinabstimmung kleiner Subnetzwerke in großen Sprachmodellen mittels Reinforcement Learning ein bedeutender Fortschritt in der KI-Forschung. Dieser Ansatz kombiniert Leistung und Effizienz und ermöglicht eine präzise, ressourcenschonende Optimierung. Die Ergebnisse zeigen, dass selbst bei minimalen Änderungen an einem Teil des Modells erstaunliche Verbesserungen der Funktionalität erzielt werden können.
Für die Zukunft versprechen diese Methoden, die Entwicklung intelligenter, anpassungsfähiger und verantwortungsbewusster KI-Systeme zu beschleunigen und dabei nachhaltigere Technologien zu fördern.