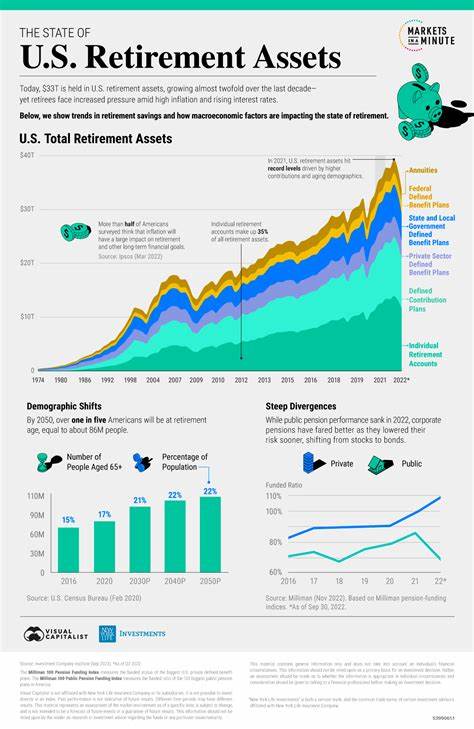
Die Programmiersprache D steht für Leistungsfähigkeit und Flexibilität, insbesondere wenn es um den Umgang mit komplexen Datenstrukturen geht. Ein zentrales Thema in vielen Anwendungen ist der Umgang mit multidimensionalen Arrays. Diese ermöglichen die Repräsentation von Daten in mehreren Dimensionen, sei es zur Speicherung von Matrizen, Tabellen oder mehrdimensionalen Datensätzen. D bietet verschiedene Möglichkeiten, multidimensionale Arrays zu erstellen und zu verwalten, die sowohl einfach als auch hochperformant sind. Grundlegend unterscheidet man in D zwischen normalen Arrays, statischen Arrays mit fester Länge und dynamischen Arrays.
Normale Arrays repräsentieren eine Sequenz von Elementen, die linear im Speicher angeordnet sind. Statische Arrays haben eine bekannte, zur Kompilierzeit festgelegte Größe, während dynamische Arrays flexibel sind und zur Laufzeit wachsen oder schrumpfen können. Die Eigenschaft .length gibt stets die Anzahl der Elemente zurück, während .ptr einen Zeiger auf das erste Element liefert.
Ein wichtiges Konzept bei D-Arrays ist das der Slices, welche dynamische Arrays sind, die aus einem gegebenen Arraybereich herausgeschnitten werden können. Sie bieten eine effiziente Möglichkeit, Teilbereiche von Arrays ohne Kopieren zu bearbeiten. Slices können durch einfache Bereiche wie arr[1 .. 3] gebildet werden und besitzen eigene Längen und Zeiger.
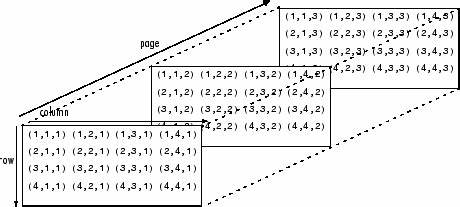
Multidimensionale Arrays lassen sich in D grundsätzlich auf zwei Arten realisieren: als sogenannte jagged Arrays und als dichte Arrays mit festen Dimensionen. Jagged Arrays bestehen aus Arrays von Arrays, wobei die Längen der inneren Arrays variieren können. Diese Flexibilität führt allerdings zu einer gewissen Leistungseinbuße, da die inneren Arrays separat im Speicher liegen und Zugriffe auf sie indirekt erfolgen. Beispielhaft ist ein jagged Array int[][] jaggedArr = [[0, 1], [2, 3, 4]]; das unterschiedlich lange Unterarrays enthält. Dichte Arrays hingegen sind fest dimensioniert und werden als Arrays mit konstanten Längen definiert, etwa int[2][3], was ein zweidimensionales Array mit 3 Zeilen und 2 Spalten erzeugt.
Diese Arrays sind im Speicher zusammenhängend und bieten daher optimale Zugriffszeiten. Außerdem ermöglicht D eine Variable-Länge-Dimension wie int[2][] dynamicDenseArr = new int[2][](3), bei dem nur die äußere Dimension flexibel ist. Um einfache und effiziente Erstellung sowie Manipulation von multidimensionalen Arrays zu erleichtern, stellt D die Funktionalitäten aus dem std.range Modul bereit. Die Funktion iota erzeugt dabei eine Folge von Werten in einem Bereich, die mithilfe von chunks in zweidimensionale Slices aufgeteilt werden können.
So lässt sich beispielsweise aus einer flachen Sequenz von 20 Werten eine 2D-Ansicht mit 4 Reihen und 5 Spalten erzeugen. Diese Technik ist besonders nützlich, wenn Daten flach gespeichert und dennoch multidimensional verarbeitet werden sollen. Zur Ermittlung der Dimensionen von mehrdimensionalen Arrays oder Slices bietet sich das Konzept der rekursiven Templates an. Ein solches Template kann die Länge jeder Dimension ermitteln und so eine Art Shape oder Form des Arrays simulieren, da native D-Arrays keine direkte Eigenschaft dafür besitzen. Bei korrekt chunked Arrays ergeben sich so präzise Dimensionen, etwa [4, 5] für ein 4x5 Array.
Im professionellen Umfeld, gerade wenn es um numerische Berechnungen und wissenschaftliche Anwendungen geht, kommt die leistungsfähige mir-algorithm Bibliothek ins Spiel. Das mir.ndslice Modul bietet dort spezielle Strukturen für multidimensionale Slices, die unterschiedliche Vorteile gegenüber standardmäßigen D-Arrays bieten. Hier bezeichnet man Slices als mehrdimensionale Bereiche mit Eigenschaften wie Shape, Strides und einem geschlossenem Speicherlayout. Sie sind besonders schnell und speichereffizient.
Bei der Arbeit mit mir.ndslice ist es wichtig zu verstehen, wie Slices erzeugt werden. Ein direkter Konstruktoraufruf mit slice!int eines Arrays erzeugt nicht immer das gewollte Ergebnis, da eine mehrdimensionale Slice mit der Form der Dimensionslängen initialisiert wird. Mittels der Funktion as aus dem mir.ndslice.
topology Modul kann man jedoch eine korrekte View auf Werte erzeugen, die das tatsächliche Elementarray repräsentiert. Das erleichtert die Arbeit mit eindimensionalen und mehrdimensionalen Arrays wesentlich. Mit der Methode sliced lassen sich eindimensionale und multidimensionale Slices intuitiv und effizient erstellen. sliced arbeitet über Iteratoren, Arrays oder Pointer und erzeugt Views, die das Originalobjekt ohne Kopie darstellen. Dabei kann durch Angabe der Dimensionen direkt eine mehrdimensionale Slice erworben werden, ohne dass vorher eine Größe in ein flaches Array umgewandelt werden muss.
Die Kombination von iota mit fuse bietet ebenfalls eine elegante Möglichkeit, multidimensionale Bereiche zu formen. Fuse erzeugt eine mehrdimensionale Sicht auf eine flache iota-Folge und ermöglicht so einfache und schnelle Initialisierungen. Ein wesentliches Merkmal von mir.ndslice ist die Möglichkeit, Slices in flache Arrays umzuwandeln, indem man die .field Eigenschaft nutzt.
Sie liefert zurück eine eindimensionale D-Array-Repräsentation der Daten. Diese ist hilfreich, wenn man bestimmte Operationen oder Interoperabilität mit anderen Funktionen benötigt, dabei aber die Speicherzusammenhängigkeit gewährleisten möchte. Der Ausdruck und die Darstellung von Arrays und Slices gelingt einfach mit der Funktion writeln. Will man präzisere Formatierungen oder ästhetische Darstellungen erhalten, gibt es spezialisierte Vorgehensweisen, die etwa das Einrücken oder Zeilenumbrüche berücksichtigen, um die Übersichtlichkeit bei mehrdimensionalen Strukturen zu erhöhen. Ein Thema, das besonders Entwickler von wissenschaftlichen Anwendungen anspricht, ist die Erzeugung von Arrays mit Zufallswerten.
In Verbindung mit Standardfunktionen wie generate und take aus std.range sowie uniform aus std.random kann man leicht eindimensionale Zufallsfolgen erzeugen und mit sliced zu mehrdimensionalen Slices umformen. Mir bietet darüber hinaus mit randomSlice in mir.random.
algorithm eine performante Lösung, um multidimensionale Zufallsarrays direkt zu generieren, wobei neben göttlichen Verteilungen auch individuelle Zufallszahlengeneratoren verwendet werden können. Zur Manipulation von Elementen in Slices kann über Funktionen wie each auf jeden Eintrag zugegriffen werden. Dabei lässt sich nicht nur lesen, sondern auch mit Zuweisungen oder string-Mixin Operatoren Änderungen durchführen, was eine effiziente In-Place-Bearbeitung ohne zusätzliche Speicherzuweisungen ermöglicht. Für das Erzeugen neuer Slices aus bestehenden, beispielsweise mit Nullwerten, können Map-Operationen genutzt werden, obwohl hier Speicherallokationen auftreten. Die Syntax für grundlegende mathematische Operationen wie Addition, Subtraktion oder Multiplikation ist dabei stark an die herkömmliche elementweise Algebra angelehnt.
So lassen sich Slices bequem mit Skalaren oder anderen Slices verknüpfen. Operationen bleiben dabei zunächst lazy, d.h. die Berechnung findet erst bei Bedarf statt, was die Performance verbessern kann. In manchen Szenarien ist das Verändern einzelner Elemente einer Slice notwendig.
Für lazy Slices, wie die aus sliced, ist dies nicht direkt möglich. Stattdessen verwendet man feste Slice-Arrays, welche tatsächlich Speicher besitzen und sicher modifizierbar sind. Dort kann man etwa einzelne Werte oder ganze Zeilen oder Spalten zielgerichtet verändern. Neben einfachen Operationen sind auch komplexere mathematische Funktionen wie Exponential oder Wurzel durch Mapping von Element-Funktionen auf Slices realisierbar. Die mir.
math-Bibliothek bietet dafür effiziente Funktionsvarianten an. Für Aggregatfunktionen wie die Summe steht ebenfalls eine optimierte Implementierung bereit, die je nach Datentyp unterschiedliche Summationsalgorithmen wählt. Zur gezielten Verarbeitung einzelner Dimensionen eines multidimensionalen Arrays kann die Funktion byDim verwendet werden. Sie ermöglicht es, eine Dimension auszuwählen und daraus eine View zu erstellen, die die Bearbeitung von Zeilen oder Spalten vereinfacht. Damit lassen sich beispielsweise Summen von Spalten oder Bedingungen über einzelne Dimensionen auswerten und filtern.
Sortierungen mehrdimensionaler Arrays sind mit Hilfe von mir.ndslice.sorting möglich. Dabei kann die Sortierung auf einzelnen Dimensionen in-place erfolgen, was die Effizienz zu erhöht und Speicherplatz spart. Die Verwendung dieses Features ermöglicht die einfache Organisation von Datensätzen in Matrixform.
Das Indexieren und Slicen von mir.ndslice Slice-Objekten folgt ähnlich der Syntax von nativen D-Arrays. Dabei sind negative Indizes nicht erlaubt, aber der Spezialoperator $ dient der Vereinfachung bei der Angabe von Endpositionen. Mehrdimensionale Arrays werden mit mehreren Indizes adressiert, um gezielt auf Zeilen und Spalten zuzugreifen oder Teilbereiche auszuwählen. Insgesamt zeigen die vielfältigen Möglichkeiten von D und mir.
ndslice, wie anspruchsvolle multidimensionale Datenstruktur effizient implementiert und verarbeitet werden können. Die Kombination aus Flexibilität, Leistung und umfangreichen Bibliotheken macht D zu einer exzellenten Wahl für Entwickler, die numerische oder datenintensive Applikationen realisieren wollen. Dabei zeichnet sich die Sprache durch klar verständliche Syntax, moderne Konzepte wie lazy Evaluation und gut durchdachte Erweiterungen aus, die den Umgang mit komplexen Daten formen und erleichtern. Wer sich in die Welt der mehrdimensionalen Arrays in D einarbeitet, profitiert von der großen Community und den stetig wachsenden Ressourcen. Das Zusammenspiel von Kernsprachenkonstrukten mit leistungsfähigen Zusatzbibliotheken wie mir.
ndslice eröffnet eine breite Palette an Möglichkeiten für professionelle und effiziente Programmierung. So lassen sich komplexe Algorithmen, Simulationen oder Data-Science-Anwendungen mit hoher Performance umsetzen, ohne auf bewährte Konzepte oder bewährte Werkzeuge verzichten zu müssen.