Die rasante Entwicklung künstlicher Intelligenz hat die Art und Weise, wie wir mit Technologie interagieren, in den letzten Jahren grundlegend verändert. Insbesondere große Sprachmodelle – auch bekannt als Large Language Models (LLMs) – haben durch ihre Fähigkeit, natürliche Sprache zu verstehen und zu generieren, viel Aufmerksamkeit erlangt. Bislang war die Ausführung solcher Modelle meist auf mächtigen Cloud-Servern angesiedelt. Doch mit der steigenden Nachfrage nach Datenschutz, geringerer Latenz und mehr Energieeffizienz rückt eine Alternative zunehmend in den Fokus: Die Ausführung von LLMs direkt auf mobilen und Desktop-Geräten dank Apples Apple Neural Engine (ANE). Die Apple Neural Engine ist eine spezialisierte Hardware-Einheit, die erstmals 2017 mit dem iPhone X eingeführt wurde und speziell entwickelt ist, um KI-Workloads energieeffizient und schnell zu bewältigen.
Im Gegensatz zur ausschließlichen Nutzung von CPU oder GPU ermöglicht die ANE durch optimierte Tensor-Berechnungen eine deutlich bessere Performance bei neuronalen Netzwerkoperationen. Die Frage lautet nun, wie man große Sprachmodelle, die aufgrund ihrer enormen Komplexität und Größe traditionell auf große Rechenzentren angewiesen waren, so portiert und optimiert, dass sie auf der ANE flüssig laufen. Die Antwort liegt in einer Kombination aus Fortschritten in der Modellkompression, Quantisierung und spezialisierter Software-Tools, die das Framework CoreML und die ANE-Hardware optimal nutzen. Projekte wie ANEMLL sind entsprechende Beispiele, die speziell darauf ausgerichtet sind, die Portierung von großen Sprachmodellen auf die Apple Neural Engine zu erleichtern. Durch diese Open-Source-Initiative wird eine Pipeline bereitgestellt, mit der Entwickler Modelle direkt von den Hugging Face Bibliotheken konvertieren können – einem der führenden Repositories für vortrainierte KI-Modelle.
Dieser Prozess umfasst die Umwandlung der Modellgewichte in ein Format, das vom CoreML-Compiler und der ANE verstanden wird. Damit entfällt teilweise die Abhängigkeit von Internetverbindungen und Cloud-Diensten, was eine ganze Reihe von Vorteilen mit sich bringt. Der bedeutendste Vorteil ist die Gewährleistung von Datenschutz und Sicherheit. Da das Modell und die Berechnungen auf dem Gerät verbleiben, können sensible Nutzerdaten das Gerät nicht verlassen, was insbesondere in Bereichen wie Healthcare, Finanzen oder Personalwesen von immenser Bedeutung ist. Zudem profitiert die Nutzererfahrung von deutlich geringeren Verzögerungen, denn die Recheninfrastruktur befindet sich lokal und nicht irgendwo in einem entfernten Rechenzentrum.
Auch aus Sicht der Energieeffizienz bietet die ANE klare Vorteile. Cloud-Server verbrauchen immense Mengen an Energie, während mobile Geräte durch eine effiziente Hardware wie die ANE längere Akkulaufzeiten ermöglichen und gleichzeitig performant bleiben. Die ANE nutzt einen eigenen, für KI-Workloads optimierten Ansatz, der den Energieverbrauch deutlich reduziert. Die Portierung der Modelle auf die ANE ist technisch herausfordernd und erfordert verschiedene Schritte. Neben der Konvertierung der Modelle müssen sie auch quantisiert werden.
Quantisierung beschreibt den Prozess, Modelle mit geringerer numerischer Präzision auszuführen, was zu kleineren Modellen und schnellerer Berechnung beiträgt, aber zugleich das Verhalten des Modells weitestgehend erhalten soll. Die aktuelle Quantisierung auf der ANE nutzt vor allem 4-Bit-Quantisierung (LUT4), welche jedoch noch ausbaufähig ist. Die Qualität der quantisierten Modelle variiert und es sind weitere Fortschritte in Blockquantisierung und anderen GPTQ-Techniken nötig, um noch präzisere und schnellere Modelle zu gewährleisten. Apples CoreML-Framework spielt dabei eine zentrale Rolle. Es ermöglicht das Kompilieren und Ausführen von Modellen auf verschiedenen Apple-Hardwarekomponenten, darunter auch die ANE.
Entwickler können somit Modelle in ihrer Ursprungssprache trainieren – in der Regel Python mit Frameworks wie PyTorch oder TensorFlow – und diese dann mit CoreML in ein Format übertragen, das für Apple-Geräte optimiert ist. Derzeit liegt der Fokus vor allem auf Meta's LLaMA 3 Architektur, die aufgrund ihrer vergleichsweise guten Leistungsfähigkeit und Verfügbarkeit stark genutzt wird. Verschiedene Varianten dieser Modelle, darunter auch kleinere 1-Milliarden-Parameter-Versionen, werden bereits erfolgreich auf der ANE ausgeführt. Zusätzlich zu LLaMA sind auch sogenannte „distillierte“ Modelle wie DeepSeek und DeepHermes in der ANEMLL-Community verfügbar. Diese bieten eine reduzierte Modellgröße bei größtmöglicher Leistungsfähigkeit.
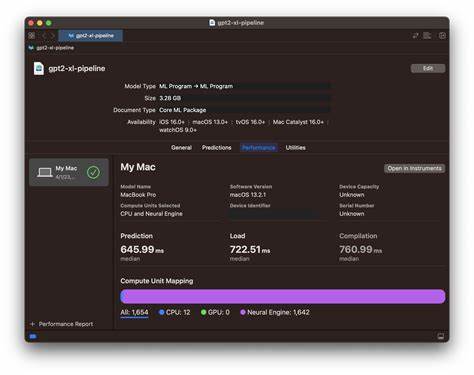
Für Entwickler bietet ANEMLL verschiedene Werkzeuge an, darunter Konvertierungsskripte, Referenzimplementierungen in Swift und Python sowie Beispielanwendungen für iOS und macOS. Insbesondere die Swift-Integration ist für Apple-Entwickler spannend, da sie native Applikationen mit effizienten LLM-Funktionalitäten ermöglicht. Eine wichtige Rolle spielt auch die Benchmarking-Komponente ANEMLL-BENCH, mit der die Performance unterschiedlicher Modelle und Optimierungen auf verschiedenen Apple-Geräten gemessen werden kann. Dies ist essenziell, um Modelle oder Optimierungen gezielt für bestimmte Anwendungsfälle zu priorisieren. Für die Nutzer eröffnet dieser Trend völlig neue Möglichkeiten.
Sprachassistenten, Chatbots und andere KI-Anwendungen können nun auch offline, schnell und sicher betrieben werden. Anwender sind nicht mehr zwingend auf eine aktive Internetverbindung angewiesen und können das volle Potenzial von KI-Technologie auf ihren eigenen Geräten ausnutzen. Zudem wird die Barriere für Entwickler gesenkt, die LLMs in ihren Anwendungen einsetzen möchten, da die Hardwarebeschleunigung der ANE eine hochperformante Ausführung selbst auf ressourcenbegrenzten mobilen Geräten ermöglicht. Trotz der zahlreichen Vorteile ist das Ökosystem noch jung und befindet sich im Alpha-Stadium. Die Quantisierungsmethoden sind noch nicht vollständig ausgereift, und die Modellunterstützung wird nach und nach erweitert.
Interessierte Entwickler sollten sich stets über die offiziellen Kanäle auf GitHub oder Hugging Face auf dem Laufenden halten, um Neuerungen und optimierte Modelle zu erhalten. Die Zukunft verspricht weitere Verbesserungen: Apple arbeitet kontinuierlich an der Weiterentwicklung seiner Neural Engine, und durch die offene Entwicklungsgemeinschaft werden in den kommenden Jahren wahrscheinlich immer effizientere sowie noch genauere LLM-Ausführungen auf der ANE möglich sein. Parallel dazu könnten weitere Modelle und Architekturen neben LLaMA unterstützt werden, was die Vielfalt und Einsatzmöglichkeiten zusätzlich erhöht. Zusammenfassend lässt sich sagen, dass die Ausführung großer Sprachmodelle auf der Apple Neural Engine eine zukunftsträchtige Innovation darstellt. Sie verbindet modernste KI-Technologie mit den Vorteilen von Datenschutz, niedriger Latenz und Energieeffizienz auf Mobilgeräten und Desktop-Systemen.
Projekte wie ANEMLL geben Entwicklern die Werkzeuge an die Hand, um diese Möglichkeiten effizient zu nutzen und native KI-Anwendungen für die Apple-Welt zu schaffen. Wer auf der Suche nach einer Lösung für On-Device-KI ist, sollte die Entwicklungen rund um die ANE genau beobachten und frühzeitig in die Technologie investieren. Die Kombination aus leistungsfähigen LLMs und der starken Hardwarebeschleunigung der Apple Neural Engine ebnet den Weg für eine neue Generation intelligenter, privater und responsiver Anwendungen auf iPhone, iPad und Mac.