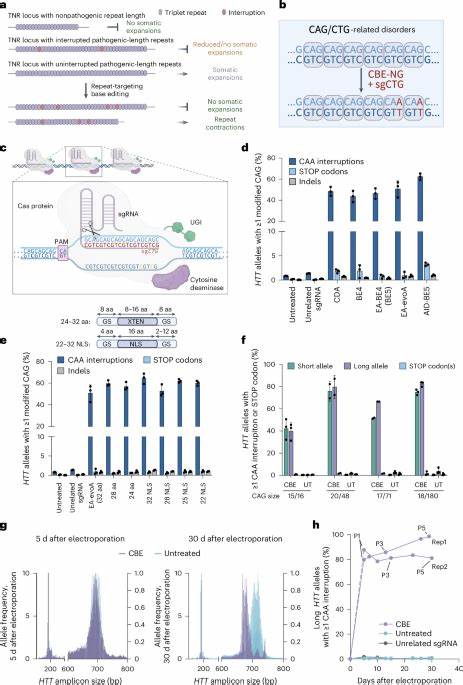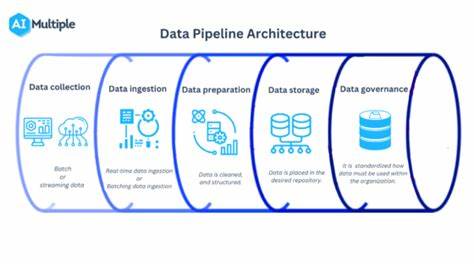
Im Zeitalter der Digitalisierung ist die Verarbeitung und Integration von Daten zu einer entscheidenden Grundlage für unternehmerischen Erfolg geworden. Data Pipelines spielen hierbei eine zentrale Rolle, indem sie den Datenfluss von der Quelle bis zur Zielanwendung strukturieren und automatisieren. Unternehmen stehen dabei vor der Herausforderung, geeignete Tools zu wählen, die ihren individuellen Anforderungen gerecht werden. Dieser Beitrag bietet einen umfassenden Überblick über die gängigsten Data Pipeline Tools und deren Einsatzgebiete, um Entscheidungsträger und Fachleute bei der Auswahl und Implementierung zu unterstützen. Data Pipeline Tools sind Softwarelösungen, die den Prozess der Extraktion, Transformation und Laden (ETL) von Daten automatisieren.
Sie ermöglichen es, Daten aus verschiedenen Quellen zu sammeln, zu bereinigen, zu transformieren und anschließend in Zielsysteme zu übertragen. In einer Welt, in der Daten in riesigen Mengen und aus unterschiedlichsten Kanälen anfallen, wird die Fähigkeit, Daten effizient zu verarbeiten, zu einem Wettbewerbsvorteil. Ein essenzielles Kriterium bei der Auswahl eines Data Pipeline Tools ist die Kompatibilität mit den verwendeten Datenquellen und -systemen. Viele Tools unterstützen eine breite Palette von Datenbanken, Cloud-Diensten, APIs und Dateisystemen, wodurch sie flexibel in unterschiedlichsten Umgebungen eingesetzt werden können. Neben der Kompatibilität sollte auch auf Skalierbarkeit geachtet werden.
Während kleine Unternehmen zunächst mit überschaubaren Datenmeng en arbeiten, steigen Anforderungen häufig schnell an, sodass das Tool mitwachsen muss, ohne Leistungseinbußen zu erleiden. Moderne Data Pipeline Tools bieten nicht nur reine ETL-Funktionalitäten, sondern ermöglichen auch komplexe Datenverarbeitungen und -analysen in Echtzeit. Streaming-Daten können verarbeitet und somit zeitnahe Erkenntnisse generiert werden. Dies ist insbesondere relevant für Branchen wie E-Commerce, Finanzwesen oder IoT-Anwendungen, in denen schnelle Reaktionszeiten entscheidend sind. Zu den etablierten Tools im Bereich der Data Pipelines zählt Apache Airflow als Open-Source-Lösung, die mit ihrem fokus auf Workflow-Orchestrierung überzeugt.
Airflow erlaubt die Gestaltung komplexer Datenflüsse mittels Python-Skripten und bietet eine übersichtliche Benutzeroberfläche zur Kontrolle und Überwachung. Für Unternehmen, die Open-Source bevorzugen und flexible Anpassungen benötigen, stellt Airflow eine perfekte Option dar. Im Gegensatz dazu stehen Managed Services wie AWS Glue, die vor allem für Nutzer der Amazon Web Services Infrastruktur interessant sind. AWS Glue bietet eine serverlose Architektur, die die Einrichtung und den Betrieb von ETL-Prozessen vereinfacht. Automatisierte Schema-Erkennung und skalierbare Ressourcen sind weitere Vorteile, die den Betrieb effizienter machen.
Neben diesen Lösungen rücken auch Plattformen wie Google Cloud Dataflow und Azure Data Factory immer mehr in den Fokus. Sie sind integraler Bestandteil der jeweiligen Cloud-Ökosysteme und ermöglichen nahtlose Verbindungen zu anderen Cloud-Diensten, was den Aufbau hybrider und multicloudfähiger Datenarchitekturen erleichtert. Dadurch können Unternehmen agil auf sich verändernde Anforderungen reagieren und innovative Lösungen schneller implementieren. Ein wichtiger Trend bei Data Pipeline Tools ist die zunehmende Unterstützung von Low-Code- oder No-Code-Lösungen. Diese Tools richten sich an Anwender, die keine tiefen Programmierkenntnisse besitzen, aber dennoch komplexe Datenprozesse erstellen möchten.
Durch visuelle Editoren und vorgefertigte Bausteine wird die Entwicklung von Pipelines erheblich vereinfacht und beschleunigt. Im Bereich der Echtzeitdatenverarbeitung haben sich Tools wie Apache Kafka als Industriestandard etabliert. Kafka bietet eine robuste Plattform für das Streamen von Daten und die Integration verschiedener Systeme über Event-Streaming. In Kombination mit Stream-Processing-Frameworks ermöglichen solche Lösungen die flexible und skalierbare Verarbeitung von Datenströmen. Neben der technischen Funktionalität spielen auch Sicherheitsaspekte eine wesentliche Rolle.
Viele Data Pipeline Tools bieten integrierte Funktionen zur Zugriffskontrolle, Datenverschlüsselung und Auditierung, um Compliance-Anforderungen gerecht zu werden. Gerade in Branchen mit hohen Datenschutzstandards ist dies unerlässlich. Die Auswahl des passenden Data Pipeline Tools sollte zudem unter Kostenaspekten betrachtet werden. Während Open-Source-Lösungen zunächst kostengünstig erscheinen, können Wartung, Betrieb und Anpassungen hohen Aufwand verursachen. Managed Services dagegen bieten oft transparente Preismodelle und entlasten die IT-Teams, kommen jedoch mit wiederkehrenden Kosten.
Im Kontext der Unternehmenskultur und der vorhandenen Infrastruktur lohnt es sich, ebenfalls den Grad der Integration und den Schulungsaufwand einzuschätzen. Tools, die sich nahtlos in bestehende Ökosysteme einbinden lassen und eine intuitive Bedienung bieten, tragen dazu bei, die Akzeptanz bei den Anwendern zu erhöhen und den Return on Investment zu steigern. Zusammenfassend lässt sich sagen, dass die Landschaft der Data Pipeline Tools vielfältig ist und sich stetig weiterentwickelt. Vom einfachen ETL-Prozess bis hin zu komplexen, Echtzeit-fähigen Datenarchitekturen gibt es für nahezu jede Anforderung eine passende Lösung. Entscheidend für den Erfolg ist dabei eine sorgfältige Analyse der Geschäftsbedürfnisse, der technischen Voraussetzungen und der langfristigen Ziele.
Nur so kann ein Data Pipeline Tool ausgewählt und implementiert werden, das die Datenstrategie eines Unternehmens nachhaltig unterstützt und das Potenzial der Daten voll ausschöpft.