Maschinelles Lernen (ML) etabliert sich zunehmend als Schlüsseltechnologie in verschiedensten Branchen und Anwendungen. Dabei ist das Prototyping – also die schnelle Entwicklung, das Testen und Anpassen von ML-Modellen – oft ein komplexer und zeitintensiver Prozess. Die Herausforderung liegt nicht nur im Training leistungsstarker Modelle, sondern auch im effizienten Umgang mit großen Datenmengen sowie einer sauberen, nachvollziehbaren Datenvorbereitung. Genau hier kommen moderne Tools wie DuckDB und scikit-learn ins Spiel, die in Kombination eine vielversprechende Plattform für ML-Prototyping bieten, insbesondere für Python-Nutzer. In diesem Artikel wird aufgezeigt, wie DuckDB und scikit-learn Hand in Hand eine robuste Umgebung schaffen, um Machine Learning Workflows von der Datenvorbereitung bis zur Modellinferenz optimal zu gestalten.
DuckDB ist eine relationale In-Memory-Datenbank, die SQL-Abfragen lokal im Speicher extrem schnell ausführen kann. Der Fokus liegt auf analytischen Workloads mit einem unkomplizierten Setup, was sie ideal für den Einsatz in Datenwissenschaft und maschinellem Lernen macht. scikit-learn hingegen ist eine der beliebtesten Python-Bibliotheken für Machine Learning, die eine breite Palette an Algorithmen und Hilfsmitteln für Klassifikation, Regression und Clustering bietet und sich durch ihre Benutzerfreundlichkeit auszeichnet. Eine typische Herausforderung beim Machine Learning ist die Vorbereitung der Daten. Oftmals stammen Daten aus unterschiedlichen Quellen, sind unvollständig oder in einem für ML ungeeigneten Format.
Das hat direkten Einfluss auf die Modellqualität und die Performance im laufenden Betrieb. DuckDB unterstützt hier dank seiner SQL-Oberfläche und flexiblen Schnittstellen eine unkomplizierte und effiziente Datenmanipulation. Beispielsweise kann man mit DuckDB problemlos CSV-Daten laden, filtern und transformieren, ohne aufwändige externe Tools einzubinden. Zum Beispiel kann das berühmte Palmer Penguins-Datenset, ein beliebter Datensatz zur Klassifikation von Pinguin-Arten, direkt aus dem Web geladen und mit DuckDB in SQL verarbeitet werden. Dabei lassen sich fehlende Werte (NA oder NULL) einfach ausschließen, was grundlegend für sauberes Training ist.
Ein weiteres praktisches Feature von DuckDB ist die Möglichkeit, Datentypen während oder nach dem Import anzupassen, was die Kompatibilität mit Machine Learning Modellen verbessert. So werden numerische Werte korrekt als Dezimalwerte gespeichert, was beispielsweise für präzise Modellierung notwendig ist. Ein weiterer wichtiger Schritt vor dem Modeltraining ist die Transformation kategorischer Merkmale in numerische Werte. Dieser Prozess, oft als Label-Encoding bezeichnet, ist essenziell, da die meisten ML-Algorithmen numerische Eingabedaten erwarten. DuckDB zeigt hier seine Stärken durch die einfache Generierung von Referenztabellen mit eindeutigen Bezeichnern für jede Kategorie – dies ähnelt klassischen Workflows in Data Warehouses und erleichtert die Nachverfolgbarkeit und Wiederverwendbarkeit der Daten.
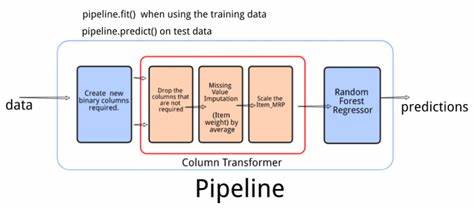
Dieser Ansatz ist besonders nützlich, wenn mehrere kategorische Variablen parallel verarbeitet werden müssen. Auf dem Weg zum Modell ist das Aufteilen der Daten in Trainings- und Testsets ein weiterer Standardprozess, um eine objektive Bewertung der Modellleistung zu ermöglichen. Mittels schlichter SQL-basierter Abfragen in DuckDB kann das Datenpaket bequem aufgeteilt und dann nahtlos für das Training an scikit-learn übergeben werden. Die Integration ermöglicht es, trainierte Modelle schnell zu speichern und wiederzuverwenden, beispielsweise mit dem Python-eigenen Pickle-Format. Zur Modellierung wird häufig ein Random Forest Classifier eingesetzt.
Dieses Ensemble-Verfahren kombiniert mehrere Entscheidungsbäume, um robuste und weniger überfitting-anfällige Ergebnisse zu erzielen. Die Implementierung in scikit-learn ist einfach und bietet schnelle Möglichkeiten, Parameter wie die Baumanzahl oder maximale Tiefe zu steuern, was direkt Einfluss auf die Genauigkeit sowie Trainingszeit hat. Nach dem Training zeigt sich häufig eine hohe Vorhersagegenauigkeit, wie etwa 98 Prozent, was für erste Prototypen bereits sehr zufriedenstellend ist. Doch Machine Learning endet nicht mit einem trainierten Modell. Ein entscheidender Schritt ist die Modellinferenz, also die Anwendung des Modells auf neue, bisher unbekannte Daten.
Hier bieten sich mehrere Möglichkeiten an, wie Vorhersagen mit DuckDB optimal eingebunden werden können. Die traditionellste Methode ist, Daten aus DuckDB in einen Pandas DataFrame zu extrahieren, Vorhersagen mit scikit-learn durchzuführen und die Ergebnisse anschließend wieder abzufragen. Diese Integration ist einfach zu implementieren und eignet sich besonders gut für kleinere Datenmengen oder Explorationsphasen. Für größere Datenbanken mit umfangreichen Vorhersagen ermöglicht DuckDB die Nutzung sogenannter Python User Defined Functions (UDFs). Diese erlauben das direkte Einbinden von Python-Funktionen in SQL-Abfragen.
Es gibt hierbei zwei Ansätze: ein klassischer, bei dem jede Zeile einzeln verarbeitet wird, und ein batch-weise Ansatz, der mehrere Datensätze in einem Durchgang vorhersagt. Der Zeilen-weise Ansatz eignet sich gut für Low-Volume-Anwendungen oder wenn individualisierte Vorhersagen erwünscht sind. Im Gegensatz dazu ist der Batch-Ansatz deutlich performanter bei großen Datensätzen, da die Modellvorhersage auf Arrays basiert und somit weniger Overhead durch Funktionsaufrufe entsteht. Performance ist ein zentraler Aspekt in produktiven ML-Anwendungen. Bei sehr großen Datenmengen zeigt sich, dass die Pandas-Lösung typischerweise schneller ausgeführt wird als die UDFs, da bei letzteren mehrere Konvertierungsschritte – wie JSON-Parsing und das Umwandeln in numpy-Arrays – anfallen.
Dennoch sind die Python-UDFs für kleine bis mittelgroße Daten sehr praktisch, da sie eine elegante Verschmelzung von Datenbankabfragen und ML-Modellen erlauben, ohne dass der gesamte Datensatz außerhalb der Datenbank verarbeitet werden muss. Die Kombination aus DuckDB und scikit-learn bietet somit eine mächtige Plattform, die den gesamten Machine Learning Lifecycle abdeckt: effiziente Datenaufbereitung, Modelltraining, Validierung und Performanzoptimierung sowie Integration der Inferenz direkt in die Datenarchitektur. Für Entwickler und Data Scientists bedeutet dies weniger Kontextwechsel zwischen verschiedenen Tools und eine klar strukturierte Workflow-Pipeline. Zudem ermöglicht die Nutzung von SQL in DuckDB Datenwissenschaftlern und Analysten, ihre Daten schnell zu filtern, transformieren und vorbereiten, ohne tiefgehende Programmierkenntnisse in Python vorauszusetzen. Die einfache Erweiterbarkeit durch Python-Funktionen schafft zusätzlich Flexibilität und Integrationstiefe.
Gerade im Bereich Prototyping sind Geschwindigkeit, Flexibilität und einfache Wiederholbarkeit entscheidend – Eigenschaften, die diese Kombination besonders gut erfüllt. Abschließend lässt sich festhalten, dass DuckDB mit seiner leistungsfähigen SQL-Verarbeitung und scikit-learn als bewährtem Werkzeug für Machine Learning ein Paar bilden, das den gesamten Entwicklungsprozess moderner ML-Anwendungen begleitet. Es eröffnet insbesondere in Python-Umgebungen neue Möglichkeiten, ML-Modelle schnell zu entwickeln, zu testen und skalierbar zu betreiben, ohne dabei aufwändige Infrastrukturen nutzen zu müssen. Machine Learning Prototyping mit dieser Kombination adressiert zentrale Herausforderungen wie Datenqualität, Performance und Modularität und ist für viele Anwendungsfälle – vom kleinen Forschungsprojekt bis hin zu produktiven Anwendungen – bestens geeignet. Die klare Trennung von Datenhandling und Modelllogik in Verbindung mit mächtigen Werkzeugen schafft einen produktiven Rahmen, der Data Scientists und Entwicklern gleichermaßen zugutekommt.
Wer effiziente ML-Workflows in der Python-Welt sucht, sollte DuckDB und scikit-learn daher unbedingt in seinen Werkzeugkasten aufnehmen.