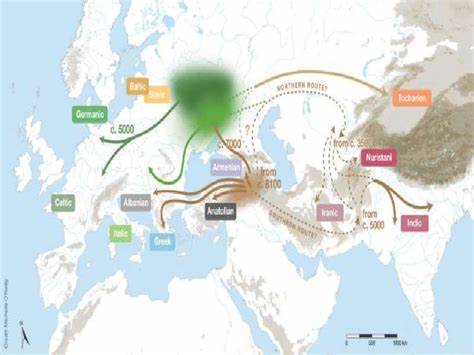
Die Frage nach der Herkunft der indogermanischen Sprachen zählt seit langem zu den spannendsten Themen der Sprachwissenschaft und historischen Linguistik. Verschiedene Theorien konkurrieren um Anerkennung, wobei sich besonders die sogenannte anatolische Hypothese und die Steppe-Hypothese einen besonderen Platz in der Forschungsgemeinschaft erobert haben. In den letzten Jahren hat die computergestützte Phylogenetik mit der Anwendung von Sprachbäumen, insbesondere solchen mit gesampelten Vorfahren, neues Interesse genährt. Die jüngste Veröffentlichung von Heggarty et al. im Jahr 2023 schlägt vor, dass diese Methodik ein hybrides Modell für die indogermanische Herkunft stützt – eine Kombination aus anatolischem und steppigem Ursprung.
Doch wie robust sind diese Ergebnisse wirklich? Eine kritische Auseinandersetzung mit Datenbasis, Methodik und Ergebnissen offenbart eine komplexe Gemengelage aus Fortschritten und systemischen Schwächen, die die Akzeptanz eines solchen hybriden Modells herausfordert. Sprachbäume sind methodisch inspiriert von den Prinzipien der biologischen Phylogenetik und versuchen, Verwandtschaftsverhältnisse historischer Sprachen durch lexikalische Daten und formale Algorithmen abzubilden. Dabei werden verschiedene Sprachen, sogenannte Taxa, anhand ihrer Grundwortschätze und typologischer Merkmale verglichen, um deren Stammbaum zu rekonstruieren. Das Konzept der gesampelten Vorfahren erweitert diese Modelle um die Möglichkeit, dass einige Knoten des Baumes tatsächlich vorgelagerte oder sogar erhaltene Stammsprachen repräsentieren, anstatt ausschließlich hypothetische Ursprungsformen. Die Studie von Heggarty et al.
nutzt eine umfassende Datenbank mit 161 Sprachvarianten und einem Wortschatz von 170 Grundbegriffen. Dieser Datensatz, bekannt als IE-CoR, ist eine deutliche Verbesserung gegenüber früheren Projekten durch eine bessere kuratorische Sorgfalt und die Beteiligung einer großen Anzahl von Fachexperten. Dennoch zeigt sich bei genauer Analyse des Materials, dass trotz Verbesserungen bei der Datenqualität erhebliche methodologische Probleme bestehen bleiben. Die Unterscheidung zwischen echten genetischen Verwandtschaften und sprachlichen Diffusionseffekten, sogenannte Arealinflüsse, wird oftmals nicht hinreichend geleistet. Auch das Phänomen des derivationalen Drift, bei dem sich auf derselben Wurzel basierende Formen unabhängig entwickeln und somit nicht notwendigerweise gemeinsame Abstammung anzeigen, findet zu wenig Berücksichtigung.
Diese Aspekte führen dazu, dass der rekonstruierte Sprachbaum sowohl topologisch als auch zeitlich in mehreren entscheidenden Punkten den etablierten historischen und linguistischen Erkenntnissen widerspricht. Besonders auffällig sind Unsicherheiten in der Verzweigung und niedrige statistische Wahrscheinlichkeiten für wichtige Knoten im Baum. So erscheinen etwa Verbindungen zwischen Hethitisch und Tocharisch, die in der klassischen Forschung kaum als stichhaltig gelten, mit überraschend hoher Wahrscheinlichkeit. Die Chronologie, die den ersten Aufsplitterungen der indogermanischen Sprachen datiert, bewegt sich im Bereich von etwa 4700 bis 7600 vor Christus, was die anatolische Hypothese auch weiterhin in den Vordergrund hebt. Dieser Zeitpunkt weicht jedoch deutlich von traditionelleren Ansätzen ab, die den Beginn der indogermanischen Sprachdifferenzierung in die Mitte des 4.
Jahrtausends v. Chr. datieren. Das vorgeschlagene hybride Modell will damit eine Synthese erreichen, in der die erste Spaltung des Proto-Indogermanischen in anatolische und nicht-anatolische Zweige den bäuerlichen Ausbreitungen aus Anatolien zugeschrieben wird, während spätere Migrationen und Differenzierungen in der Steppe stattfinden sollen. Diese Sichtweise weckt Hoffnung auf eine Integration der beiden Haupttheorien, stößt jedoch auf Widerstand aufgrund der methodischen Einschränkungen der eingesetzten Modelle.
Ein weiterer kritischer Punkt betrifft die Zahl der Sprachvarianten im Verhältnis zur Menge der verwendeten lexikalischen Merkmale. Es ist eine statistische Grundregel in der phylogenetischen Analyse, dass mit zunehmender Anzahl an Taxa auch die Zahl der Charaktere – hier Grundwörter – erhöht werden muss, um eine stabile und belastbare Verzweigung darzustellen. Das Verhältnis in diesem Projekt deutet auf eine Unterbestimmung hin, was die Zuverlässigkeit des Ergebnisses fragwürdig macht. Im Gegensatz dazu empfiehlt die „Moskauer Schule“ einen gegenteiligen Weg, indem sie weniger Taxa, dafür mit Zwischenrekonstruktionen von Vorstadien der Sprachen, verwendet. Auf diesem Weg wird die Komplexität der Analyse verringert und die Robustheit erhöht.
Die linguistische Datenbasis selbst, trotz ihres Umfangs und der sorgfältigen Erarbeitung, weist zudem Schwächen auf. Eine Reihe von Wortlisten beinhaltet unbeachtete oder unzureichend markierte Lehnwörter, was insbesondere bei stark kontaktgeprägten Sprachen wie Tsakonisch-Griechisch oder Kashmiri zu falscher Verortung in der Sprachfamilie führen kann. Diese verzerrten Daten beeinflussen direkt die Gruppierung in den Sprachbäumen, was zu Fehlschlüssen über Verwandtschaftsverhältnisse führt. Auch die Auswahl der Grundbegriffe folgt nicht immer nachvollziehbaren Kriterien. So bevorzugen die Autoren eine morphologische Einfachheit als Auswahlprinzip, ohne überzeugende Belege für deren Wirksamkeit auf synchronischer Ebene zu liefern.
Tiefgreifende etymologische Analysen, die zwischen echten Verwandtschaften und komplexen Sprachkontakten oder Bedeutungsverschiebungen differenzieren, fehlen teils oder sind nur unzureichend integriert. Die phylogenetische Aufarbeitung würde dadurch klar gewinnen, wenn diese linguistischen Feinheiten systematisch einbezogen würden. Besonders problematisch ist die Interpretation des erstellten Stammbaums. Statt einer klar gegliederten Verzweigung zeigt sich oft eine große Anzahl von multifurkationen, also Verzweigungspunkten mit schwacher Spannung: mehrere Zweige gehen gleichzeitig aus einem Knoten hervor, ohne klare Reihenfolge. Dies entspricht historisch wohl eher realistischen Szenarien von gleichzeitigem Zerfall oder Patchwork-artiger Sprachentwicklung und verweist auf die Grenzen der angewandten Methoden.
Die Vorstellung, dass ein sogenannter Maximum Clade Credibility (MCC) Baum die beste Repräsentation sei, wird dabei in Frage gestellt. Eine Mehrheit der Forscher tendiert dazu, das 50-Prozent-Mehrheitsregel-Konsensmodell (MRC) als realistischer und robuster zu betrachten. Trotz aller Kritik muss anerkannt werden, dass die neue Studie einen Fortschritt hinsichtlich der Datenqualität und der Einbindung fachlicher Expertise darstellt. Im Vergleich zu älteren Arbeiten aus demselben Lager wurden Fehler im lexikalischen Material deutlich reduziert. Trotzdem bleiben grundlegende methodische Probleme ungelöst und führen zu Ergebnissen, die viele etablierte Erkenntnisse über die indogermanische Sprachentwicklung nicht überzeugend widerzuspiegeln vermögen.
Das sogenannte hybride Modell kann insofern eher als methodisch und theoretisch motivierter Versuch verstanden werden, einerseits die anatolische und andererseits die steppige Herkunftshypothese unter einem Dach zu versammeln, als dass es eine tatsächlich eindeutige Evidenz darstellt. Die traditionelle Kritik aus dem Kreis der klassischen Indogermanistik mahnt zu Besonnenheit. Formal basierte, computergestützte Modelle sollten keinesfalls die klassischen ethnolinguistischen, archäologischen und historischen Befunde überlagern, sondern nur ergänzen. Entscheidend ist ein interdisziplinärer Dialog, der beide Ansätze kritisch gegeneinander abwägt. Insgesamt illustriert die Debatte um die Sprachbäume mit gesampelten Vorfahren exemplarisch die Herausforderungen bei der Anwendung computergestützter Verfahren auf komplexe, historisch vielfältige Sprachfamilien.
Die indogermanischen Sprachen sind ein Paradebeispiel für dicht verflochtene genealogische und kontaktbedingte Beziehungen, deren zwingende Trennung die Modellierung erschwert. Künftige Forschungen werden vermutlich verstärkt auf die Kombination von qualitativen, linguistischen Analysen und quantitativen, formalen Methoden setzen. Dabei werden erweiterte Datensätze, mehrsprachliche Expertise und innovative phylogenetische Techniken eine zentrale Rolle spielen, um eine verlässlichere Rekonstruktion der indogermanischen Sprachentwicklung anzustreben. Zusammenfassend lässt sich festhalten, dass die jüngsten Fortschritte wichtige Impulse für die Erforschung der indogermanischen Sprachgeschichte liefern. Sprachbäume mit gesampelten Vorfahren bieten interessante methodische Ansätze, tragen jedoch aktuell nicht ausreichend zur Klärung der Herkunftsfrage bei, um das hybride Modell als gesicherten Konsens zu etablieren.
Eine kritische, interdisziplinäre Weiterentwicklung der Datengrundlage und Methodik ist unerlässlich, um in Zukunft präzisere und überzeugendere Ergebnisse zu erreichen.