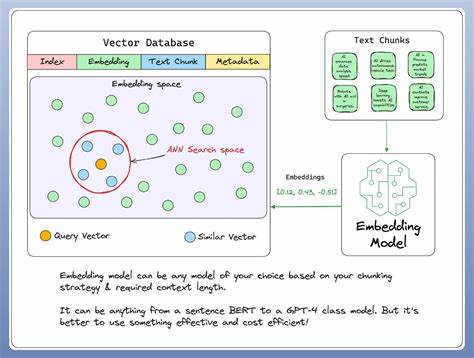
Die Informationssuche hat sich in den letzten Jahren stark gewandelt. Mit der rasanten Entwicklung von künstlicher Intelligenz und maschinellem Lernen sind Embedding-Modelle zu einem zentralen Bestandteil moderner Suchtechnologien geworden. Im Jahr 2025 sind diese Modelle essenziell, um komplexe Daten in semantische Vektoren zu transformieren, was eine präzisere und kontextbezogenere Suche ermöglicht. Technologien, die vor wenigen Jahren noch als experimentell galten, sind mittlerweile fest in die Infrastruktur von Unternehmen integriert und treiben die Qualität von Suchmaschinen und KI-Anwendungen entscheidend voran. Das Jahr 2025 bringt bereits den zweiten oder dritten großen Sprung in der Entwicklung von Embedding-Modellen mit sich.
Anbieter und Entwickler veröffentlichen neue Versionen ihrer Modelle, die sowohl in der Performance als auch in der Effizienz beständig zulegen. Besonders auffällig ist dabei der Fortschritt im Bereich der Relevanz und der multilingualen Fähigkeiten. Aktuelle Tests und Vergleiche zeigen, dass vor allem das Embedding-Modell Voyage-3-large die Konkurrenz in Sachen Relevanz deutlich übertrifft. Dieses Modell ist in der Lage, Suchanfragen und Inhalte präzise so abzubilden, dass die semantische Nähe optimal genutzt wird – ein Meilenstein, der die Nutzererfahrung auf ein neues Niveau hebt. Ein weiterer Trend sind sogenannte Matroyshka-Techniken, mit deren Hilfe die aussagekräftigsten Informationen in den ersten Dimensionen des erzeugten Vektors gesteuert werden.
Das ermöglicht es, Vektoren bei Bedarf zu kürzen, ohne dabei wertvolle semantische Details zu verlieren. Diese Effizienzsteigerung trägt erheblich dazu bei, Suchprozesse schneller und ressourcenschonender zu gestalten, ohne dass Einbußen bei der Genauigkeit entstehen. Neben proprietären Modellen wie denen von OpenAI, Google Gemini und Voyage finden Open-Source-Lösungen zunehmend Beachtung. Besonders hervorzuheben ist das Stella-Modell, das in der Open-Source-Community als sehr leistungsstark gilt und unter der MIT-Lizenz für kommerzielle Nutzung verfügbar ist. Trotz seiner vergleichsweise geringen Größe beeindruckt es durch hohe Genauigkeit und lässt sich gut für spezifische Aufgaben anpassen.
Diese Flexibilität macht es insbesondere für Entwickler attraktiv, die selbst Modelle feinjustieren oder in ihre individuellen Anwendungsfälle integrieren möchten. Die Kostenfrage spielt bei der Wahl eines Embedding-Modells ebenfalls eine bedeutende Rolle. Während OpenAI-Modelle mit hohen Leistungsausweisen glänzen, sind diese oft mit relativ hohen Kosten verbunden und unterliegen zudem Lizenzbeschränkungen. Im Gegensatz dazu bieten Modelle wie Voyage-3-lite ein gutes Kosten-Leistungs-Verhältnis mit nennenswerten Einsparungen bei ähnlich hoher Qualität. Auch das Gemini text-embedding-004 Modell punktet mit kostenlosem Zugang, was für viele Entwickler und Start-ups einen attraktiven Einstieg in die Welt der vektorisierten Suche darstellt.
Multilinguale Fähigkeiten gewinnen ebenfalls an Bedeutung. Anwendungen operieren zunehmend in globalen Kontexten, in denen Daten und Nutzer in verschiedenen Sprachen agieren. Einige Modelle wie Gemini beschränken sich derzeit noch auf Englisch, während andere, beispielsweise Voyager oder Stella, überzeugende Ergebnisse auch in französischsprachigen und weiteren Dataset-Umgebungen liefern. Diese Vielseitigkeit eröffnet neue Möglichkeiten für Unternehmen und Entwickler, die internationale Suche oder mehrsprachige KI-Anwendungen realisieren möchten. Die Datenbasis, auf der die Modelle getestet werden, ist essenziell für aussagekräftige Ergebnisse.
Klassische Text-Suchdatensätze gelten mittlerweile als stark von Modelltrainings bekannt und können daher weniger aussagekräftig für die Vergleichbarkeit neuer Modelle sein. Deshalb bieten neuartige Tests mit OCR-Daten aus Bilderdatensätzen, wie dem ViDoRe-Benchmark, eine spannende Alternative. Mit diesen möglichst unverbrauchten Ausgangsdaten kann die tatsächliche Leistungsfähigkeit eines Modells authentisch beurteilt werden, ohne Overfitting-Effekte oder übermäßigen Trainingseinfluss. In der Praxis zeigt sich, dass neben der reinen Genauigkeit auch Faktoren wie die Ausgabegröße der Vektoren und die Effizienz beim Durchsuchen der Vektorräume entscheidend sind. Kleinere Vektoren erlauben eine schnellere Indizierung und Suche, was gerade bei sehr großen Datenbanken zu signifikanten Performancevorteilen führt.
Daher sind Modelle, die trotz kompakter Vektorgrößen eine hohe semantische Präzision liefern, besonders begehrt. Die Zukunft der Embedding-Modelle für die Informationssuche deutet auf noch tiefere Integration in KI-gesteuerte Anwendungen hin. So beispielsweise bei Retrieval-Augmented Generation (RAG), einer Methode, die aktuelle Textgenerierung mit dynamischer Wissensabfrage kombiniert. Embedding-Modelle sind hier das Herzstück, das semantische Suchanfragen ermöglicht und relevante externe Informationen nahtlos in die Textgenerierung einbindet. Diese Kombination steigert die Qualität von Chatbots, virtuellen Assistenten und anderen intelligenten Systemen erheblich und eröffnet neue Geschäftsfelder.
Für Entwickler und Unternehmen, die die besten Embedding-Modelle nutzen möchten, bedeutet das Ausprobieren und Abwägen von verschiedenen Optionen. Proprietäre Lösungen bieten oft den Komfort der Integration und regelmäßigen Updates, während Open-Source-Modelle den Vorteil von Anpassbarkeit und Transparenz besitzen. Wichtig ist dabei auch, die zugrundeliegenden Lizenzbedingungen zu prüfen, um den Einsatz in kommerziellen Anwendungen abzusichern. Abschließend lässt sich festhalten, dass das Jahr 2025 für die Informationssuche eine spannende Zeit darstellt. Die Kombination aus verbesserten Embedding-Modellen, optimierten Trainingsmethoden und vielseitigen Einsatzszenarien sorgt dafür, dass die Informationssuche semantisch intelligenter, schneller und effizienter wird.